众所周知,聚类算法是一种常见的数据挖掘算法,目的在于把大量的数据点分成若干类别,把相似的内容和行为聚集在一起,不同的类之间尽量保证不相似。
提到聚类算法,大家常想到的就是经典的 KMeans 算法,层次聚类算法,
基于密度和图的聚类分析方案
。目前已经有很多的文章介绍这方面的工作,在本文中就不在赘述这一块的内容。本文要介绍的是一种 SinglePass 的文本聚类算法,有文献表示 SinglePass 算法可以有效地对新闻事件或者垃圾文本进行在线聚类,进而发现热门话题或者恶意爆发的情况。
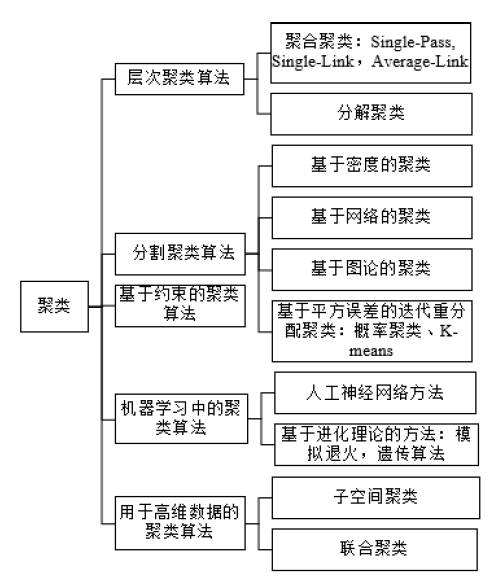
SinglePass 的算法原理:
SinglePass 算法其实就是一种流式的聚类算法,每个样本只会参与一次样本聚类,对样本的先后顺序有一定的依赖关系,其基本原理十分简单。那就是对于某个未知新样本,如果与现有的某个类足够相似,那么就放入这个类,否则就自成一类。
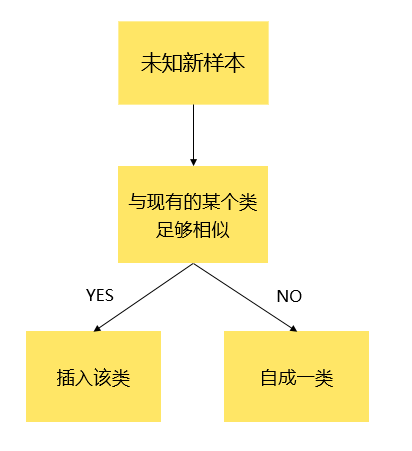
那么具体的实施步骤是怎么样的呢?
(1)第一步:切词
对于一段文本而言,第一步基本上都是进行切词这个操作,这里使用的开源工具是 jieba 切词工具。进行了切词这个操作之后,获得的是关于这段文本的词语的集合。例如:"告诉大家好消息",得到的切词结果就是 {告诉,大家,好消息}。
(2)第二步:相似度
相似度的度量是聚类算法的关键之处,常见的相似度算法有 Euclidean distance,conscine similarity, Jaccard 相似系数,pearson 相关系数等。
那么对于两个文本集合,如何对比它们之间的相似度呢?这里最常用的方法就是使用 Jaccard Index。对于两个集合 A 和 B 而言,它们的 Jaccard Index 是通过它们的交集中词语个数除以它们的并集中词语个数来计算的。用数学公式来描述就是:
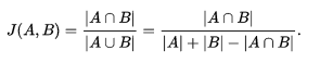
如果 A 和 B 都是空集的话,那么我们定义 J(A,B) = 1。从公式中看,Jaccard Index 具有性质 0<= J(A,B) <=1。根据 Jaccard 相似系数,就可以定义两个集合的 Jaccard 距离为:
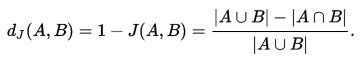
(3)第三步:代表元的选取
对于一个类而言,必须要选择一个代表元,这样才能够有效地和新来的样本进行比对,从而减少计算复杂度。目前可以采用的方法是选择该聚类中当前词语最多的元素作为该类的代表元 C,i.e. 集合 C 的势 card(C) 在该聚类中是最大的。当某个新样本到来的时候,并且判断新样本 A 与该聚类相似度的时候,只需要计算新样本 A 与该类的代表元 C 的 Jaccard Index 即可。
(4)第四步:倒排索引的建立
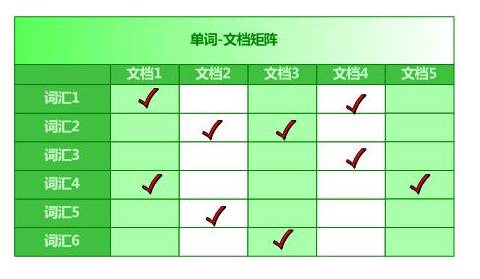
单词-文档矩阵是表达单词与文档之间的包含关系的一个模型,每一行表示一个词语,每一列表示一篇文档。如果某个词语在文档里面,那么就打勾,否则就是空白。
SinglePass 算法的分析:
(1)SinglePass聚类算法可以做成实时的,也可以做成离线的;
(2)可以有效地防止文本变化的干扰,相对数据库的 Group BY 在效果上有了不错的提升。
(3)结果明确,可解释性强。
(4)对文本输入的顺序相对敏感。如果是针对新闻信息的热点新闻发现的话,SinglePass 算法也是能够取得不错的效果的,因为新闻报道基本上都是根据时间来组织的,输入的顺序一般来说是相对固定的,算法结果并不会对新闻话题的发现有太大的影响。
欢迎大家关注公众账号数学人生
(长按图片,识别二维码即可添加关注)






