This is a guest post by Dana Van Aken, Andy Pavlo, and Geoff Gordon of Carnegie Melon University. This project demonstrates how academic researchers can leverage our AWS Cloud Credits for Research Program to support their scientific breakthroughs.
Database management systems (DBMSs) are the most important
component of any data-intensive application. They can handle large
amounts of data and complex workloads. But they’re difficult to manage
because they have hundreds of configuration “knobs” that control factors
such as the amount of memory to use for caches and how often to write
data to storage. Organizations often hire experts to help with tuning
activities, but experts are prohibitively expensive for many.
OtterTune, a new tool that’s being developed by students and researchers in the Carnegie Mellon Database Group,
can automatically find good settings for a DBMS’s configuration knobs.
The goal is to make it easier for anyone to deploy a DBMS, even those
without any expertise in database administration.
OtterTune differs from other DBMS configuration tools
because it leverages knowledge gained from tuning previous DBMS
deployments to tune new ones. This significantly reduces the amount of
time and resources needed to tune a new DBMS deployment. To do this,
OtterTune maintains a repository of tuning data collected from previous
tuning sessions. It uses this data to build machine learning (ML) models
that capture how the DBMS responds to different configurations.
OtterTune uses these models to guide experimentation for new
applications, recommending settings that improve a target objective (for
example, reducing latency or improving throughput).
In this post, we discuss each of the components in
OtterTune’s ML pipeline, and show how they interact with each other to
tune a DBMS’s configuration. Then, we evaluate OtterTune’s tuning
efficacy on MySQL and Postgres by comparing the performance of its best
configuration with configurations selected by database administrators
(DBAs) and other automatic tuning tools.
OtterTune is an open source tool that was developed by students and researchers in the Carnegie Mellon Database Research Group. All code is available on GitHub, and is licensed under Apache License 2.0.
How OtterTune works
The following diagram shows the OtterTune components and workflow.
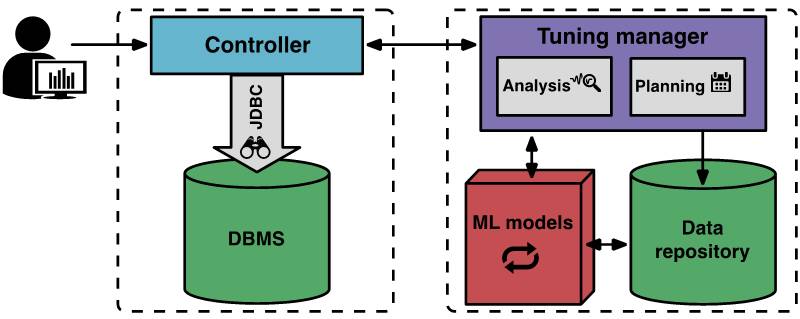
At the start of a new tuning session, the user tells
OtterTune which target objective to optimize (for example, latency or
throughput). The client-side controller connects to the target DBMS and
collects its Amazon EC2 instance type and current configuration.
Then, the controller starts its first observation period,
during which it observes the DBMS and records the target objective. When
the observation period ends, the controller collects internal metrics
from the DBMS, like MySQL’s counters for pages read from disk and pages
written to disk. The controller returns both the target objective and
the internal metrics to the tuning manager.
When OtterTune’s tuning manager receives the metrics, it
stores them in its repository. OtterTune uses the results to compute the
next configuration that the controller should install on the target
DBMS. The tuning manager returns this configuration to the controller,
with an estimate of the expected improvement from running it. The user
can decide whether to continue or terminate the tuning session.
Notes
OtterTune maintains a blacklist of knobs for each DBMS
version it supports. The blacklist includes knobs that don’t make sense
to tune (for example, path names for where the DBMS stores files), or
those that could have serious or hidden consequences (for example,
potentially causing the DBMS to lose data). At the beginning of each
tuning session, OtterTune provides the blacklist to the user so he or
she can add any other knobs that they want OtterTune to avoid tuning.
OtterTune makes certain assumptions that might limit its
usefulness for some users. For example, it assumes that the user has
administrative privileges that allow the controller to modify the DBMS’s
configuration. If the user doesn’t, then he or she can deploy a second
copy of the database on other hardware for OtterTune’s tuning
experiments. This requires the user to either replay a workload trace or
to forward queries from the production DBMS. For a complete discussion
of assumptions and limitations, see our paper.
The machine learning pipeline
The following diagram shows how data is processed as it
moves through OtterTune’s ML pipeline. All observations reside in
OtterTune’s repository.
OtterTune first passes observations into the Workload
Characterization component. This component identifies a smaller set of
DBMS metrics that best capture the variability in performance and the
distinguishing characteristics for different workloads.
Next, the Knob Identification component generates a ranked
list of the knobs that most affect the DBMS’s performance. OtterTune
then feeds all of this information to the Automatic Tuner. This
component maps the target DBMS’s workload to the most similar workload
in its data repository, and reuses this workload data to generate better
configurations.
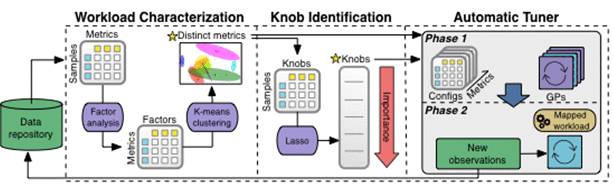
Let’s drill down on each of the components in the ML pipeline.
Workload Characterization: OtterTune uses
the DBMS’s internal runtime metrics to characterize how a workload
behaves. These metrics provide an accurate representation of a workload
because they capture many aspects of its runtime behavior. However, many
of the metrics are redundant: some are the same measurement recorded in
different units, and others represent independent components of the
DBMS whose values are highly correlated. It’s important to prune
redundant metrics because that reduces the complexity of the ML models
that use them. To do this, we cluster the DBMS’s metrics based on their
correlation patterns. We then select one representative metric from each
cluster, specifically, the one closest to the cluster’s center.
Subsequent components in the ML pipeline use these metrics.
Knob Identification: DBMSs can have
hundreds of knobs, but only a subset affects the DBMS’s performance.
OtterTune uses a popular feature-selection technique, called Lasso,
to determine which knobs strongly affect the system’s overall
performance. By applying this technique to the data in its repository,
OtterTune identifies the order of importance of the DBMS’s knobs.
Then, OtterTune must decide how many of the knobs to use
when making configuration recommendations. Using too many of them
significantly increases OtterTune’s optimization time. Using too few
could prevent OtterTune from finding the best configuration. To automate
this process, OtterTune uses an incremental approach. It gradually
increases the number of knobs used in a tuning session. This approach
allows OtterTune to explore and optimize the configuration for a small
set of the most important knobs before expanding its scope to consider
others.
Automatic Tuner: The Automated Tuning
component determines which configuration OtterTune should recommend by
performing a two-step analysis after each observation period.
First, the system uses the performance data for the metrics
identified in the Workload Characterization component to identify the
workload from a previous tuning session that best represents the target
DBMS’s workload. It compares the session’s metrics with the metrics from
previous workloads to see which ones react similarly to different knob
settings.
Then, OtterTune chooses another knob configuration to try.
It fits a statistical model to the data that it has collected, along
with the data from the most similar workload in its repository. This
model lets OtterTune predict how well the DBMS will perform with each
possible configuration. OtterTune optimizes the next configuration,
trading off exploration (gathering information to improve the model)
against exploitation (greedily trying to do well on the target metric).
链接:
https://aws.amazon.com/cn/blogs/ai/tuning-your-dbms-automatically-with-machine-learning/?tag=vglnk-c1507-20
原文链接:
http://weibo.com/1715118170/F6e54g9Uj?type=comment#_rnd1496575107147









