作者:
Steven Dufresne
翻译:
雁惊寒
随着黑客、学生、研究人员以及企业数量的增加,神经网络越来越流行。最近一次复苏是在80、90年代,当时几乎没有网络,也没有神经网络相关的工具。本次复苏始于2006年左右。从一个黑客的角度来看,在那个时候都有哪些可用的工具和资源?现在又有哪些?我们对将来的期望又是怎么样的呢?对我个人来说,树莓派上的GPU正是我所期盼的。
80、90年代
阅读本文的年轻人可能想知道,在互联网没有发明之前,我们这些老家伙是如何接触到新知识的。其实,纸质杂志在当时起到了相当大的作用。比如,《科学美国人》杂志在1992年9月的心灵与大脑特刊便让我第一次接触到了神经网络,既是在生物学上,也是在人工智能学上。
在当时,你既可以自己从头编写神经网络程序,也可以从其他地方订购一套包含源代码的软盘。我就曾经在《科学美国人》杂志的《美国科学家》专栏订购了这么一套软盘。当然,你也可以购买一套能够开发低级别的、复杂的数学神经网络开发库。比如,在多伦多大学,就有一个名叫Xerion的免费的模拟器。
如果你经常关注书店里科学类书刊的话,你有时候也会发现这方面的书籍,最经典的就是曾经出版过两卷的《并行分布式处理探索》,作者是Rumelhart、 McClelland等人。我最喜欢的一本书是《神经计算与自组织映射导论》,如果你对利用神经网络来控制机械臂感兴趣,这本书对你来说将会受益匪浅。
当然,你也可以参加一些短期的课程和会议。我在1994年曾经参加了一个为期两天的免费会议,这个会议最早是由Geoffrey Hinton主办的,后来改由多伦多大学主办。这个会议无论是在当时,还是在现在,都是神经网络领域的领导者。当时被誉为最好的年度会议是神经信息处理系统会议,它在当今仍然很受欢迎。
最后,我把为了发布论文而开发的神经网络程序整理了一遍。同时,我把所有的会议论文、课程讲义、复印的文章和手写的笔记统统摞了起来,足足达到了3英尺厚。
神经网络在经历了80、90年代的复苏后,又逐渐变得相对低调起来。从整个世界来看,除了对于个别研究团队,它已经变得不再重要。伴随着缓慢的改进以及一些小小的突破,神经网络始终保持着很低调。直到大概2006年左右,它又在世界范围内引发了一场大爆炸。
现在
现在我们来看一下神经网络工具得到重大突破的一些地方:
神经网络框架
现在有非常多的神经网络框架,他们使用了各种不同的授权协议,允许用户免费下载。其中很多还是开源框架。大部分的流行框架允许你在GPU上运行神经网络,并且支持大多数的神经网络算法。
下文将介绍一些流行的框架,他们都支持GPU,除了模糊神经网络。
开发语言:Python,C++
TensorFlow是Google公司推出的最新的神经网络框架,它专门为分布式而设计。作为一个底层框架,虽然有着非常大的灵活性,但是也比高级框架(例如Keras和TFLearn,下文会有介绍)拥有更陡的学习曲线。目前,Google正在开发Keras集成在TensorFlow中的版本。
推荐Hackaday网站上的两篇文章“能识别锤子和啤酒瓶的机器人”和“TensorFlow入门”一睹TensorFlow的风采。
开发语言:Python
这是一款用来做多维矩阵高效数值计算的开源库。它出自蒙特利尔大学,可运行在Windows、Linux和OS X上。Theano发布于2009年,已经存在了很长时间。
开发语言:命令行, Python, MATLAB
Caffe是一款由伯克利人工智能研究所和社区贡献者共同开发的开源库。在Caffe中,你可以使用文本文件来定义模型,然后通过命令行工具来进行处理。Caffe同时也有Python和MATLAB接口。例如,首先使用文本文件定义模型,然后在另外一个文本文件中给出详细的训练方法,然后通过命令行工具读入这两个文件,这样就能开始训练神经网络了。最后,你可以使用Python程序来调用这个已经训练好的神经网络来实现一些功能了,比如说把图片进行分类。
开发语言:Python, C++, C#
这是微软的认知开发包(CNTK),可运行在Windows和Linux上。微软目前正在开发一个内部使用Keras的版本。
开发语言:Python
这个库以TensorFlow或者Theano作为底层,这样可以使其用起来更加简单。Keras同时也有支持CNTK的计划。目前,把Keras融入到TensorFlow的工作正在进行中,而以后就会出现一个仅支持TensorFlow的独立的版本。
开发语言:Python
跟Keras一样,是一个基于TensorFlow的高级别的库。
开发语言:支持超过15种语言,但不支持GPU
这是一个使用C语言开发的高级别的开源库,仅可用于完全连接和稀疏连接的神经网络。然而,FANN却已经流行了很多年,甚至已经包含在一些Linux发行版中。Hackaday最近的一篇“通过强化学习来让机器人学习走路”中提到了关于FANN的使用。
开发语言:Lua
一款使用C语言开发的开源库。特别要注意的一点,在Rorch官网上特别注明了该框架支持嵌入式设备,例如iOS、Android和FPGA。
开发语言:Python
PyTorch相对来说还是比较新的,在其官网上注明了目前还属于早起的测试版,但似乎现在已经吸引了很多人的目光。它运行在Linux和OS X上,并以Torch作为底层。
你应该选择哪一个框架呢?除编程语言或者操作系统对你来说是影响选择的一个大问题,如果你觉得数学太难,或者不想深入地挖掘神经网络的细节,那么尽量选择一个高级的框架吧。在这种情况下,请远离TensorFlow,因为相对于Kera、TFLearn或者其他高级框架,你必须去学习更多的API函数。该框架在强调自身具有强大数学功能的同时,也需要你去花费更多的精力来创建神经网络。另外一个影响你选择框架的因素是你是否需要做基础研究,一个高级框架可能不会让你能接触到内部逻辑。
在线服务
你是否正在寻找一种可用的神经网络库,但你又不想花费太多的时间去学习呢?这里有一些互联网在线服务可以满足你的要求。
我们已经看到了无数使用亚马逊Alexa语音识别服务的例子。Google也提供了包括视觉和语音的云机器学习服务。这方面的例子有:使用树莓派来对糖果进行排序,以及识别人类的表情。Wekinator是一款针对艺术家和音乐家的软件,它可用于训练神经网络,可以让人们用手势来控制屋内的电器的开关。当然了,微软也有自己的认知服务API,包括视觉、语音、语言等多个方面。
GPU和TPU
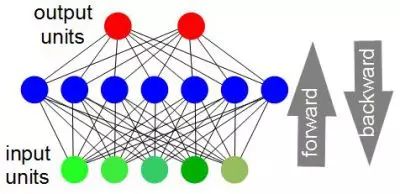
遍历一个神经网络
训练一个神经网络需要循环迭代访问整个神经网络,包括正向的和反向的,每次迭代都会提高神经网络的精度。从某种程度上来说,迭代的越多,最后的精度也越高。总的迭代次数可能会达到几百次甚至上千次。对于80、90年代的计算机来说,要实现足够多的迭代次数可能需要花费的不可思议的时间。文章“
深度学习神经网络:概述
”提到,在2004年,GPU的使用使得完全连接神经网络的速度提高了20倍,在2006年,卷积神经网络的速度提高了4倍,到2010年,使用CPU来训练的速度比使用GPU提高了50倍,神经网络的精度也越来越高。

Nvidia Titan Xp显卡。 图片来源: Nvidia
GPU是如何来提高训练的速度的呢?训练神经网络最重要的部分是做矩阵乘法运算,在这方面,GPU要比CPU快得多。显卡和GPU的市场领导者,Nvidia公司,创建了一套名叫CUDA的API,神经网络软件可以使用这套API来充分利用GPU。今后,我们会经常看到CUDA这个词。随着深度学习的发展,Nvidia公司又增加了不少API,包括CuDNN(用于深度神经网络的CUDA)。
Nvidia也有自己的单板计算机:Jetson TX2。该计算机主要用来设计自动驾驶汽车的大脑、自动拍照的无人机等等。当然,我们也要指出,这个电脑的价格还是有点高的。
Google公司也一直致力于设计自己的硬件加速系统:张量处理单元(Tensor Processing Unit,TPU)。你可能也注意到这个名字与上文介绍的Google框架TensorFlow有相似地方。根据Google关于TPU的论文描述,TPU是为神经网络的归纳阶段而设计的。归纳不是指训练神经网络,而是说使用训练后的神经网络。我们目前还没有看到有任何框架使用TPU,但是我们还是要记住这个东西的。
使用其他人的硬件
你是否有一个不支持GPU,或者你不想耗费自己的计算资源但是又需要花很长时间来训练的神经网络?在这种情况下,你可以使用互联网上的云计算服务。例如,
FloydHub
,它对于个人来说并没有月租费,而且每小时只需要话费几分钱。还有另外一个选择:
Amazon EC2
。
数据集
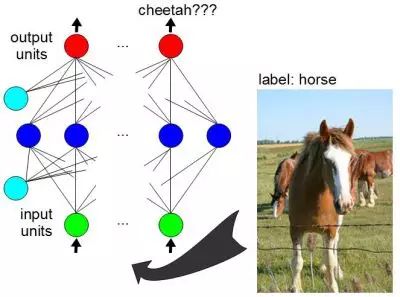
使用打过标记的数据来训练神经网络
神经网络的突破之一是包含大量样本的训练数据有效性。在训练一个使用
监督训练算法
的神经网络的时候,需要有大量的数据作为输入,并且也要告知预期的输出结果是什么。在这种情况下,输入的数据需要打上标记。如果你给神经网络的输入是一匹马的图片,而它的输出却说这个图片看起来像一只猎豹,那么它需要知道这个输出是错误的。预期输出称为标签,而输入数据就是“打了标记的数据”。










