
【AI WORLD 2017世界人工智能大会倒计时
10
天
】
在2017年11月8日在北京国家会议中心举办的AI World 2017世界人工智能大会上,我们邀请到
阿里巴巴副总裁、iDST副院长华先胜
,
旷视科技Face++首席科学家、旷视研究院院长孙剑博士,
腾讯优图实验室杰出科学家贾佳亚教授,以及
硅谷知名企业家、IEEE Fellow Chris Rowen
,共论
人脸识别等前沿计算机视觉技术
。
抢票链接:
http://www.huodongxing.com/event/2405852054900?td=4231978320026
大会官网:
http://www.aiworld2017.com
作者:Soumith Chintala等
编译:马文
【新智元导读】
本文来自ICCV 2017的Talk:如何训练GAN,FAIR的研究员Soumith Chintala总结了训练GAN的16个技巧,例如输入的规范化,修改损失函数,生成器用Adam优化,使用Sofy和Noisy标签,等等。这是NIPS 2016的Soumith Chintala作的邀请演讲的修改版本,而2016年的这些tricks在github已经有2.4k星。
ICCV 2017 slides:
https://github.com/soumith/talks/blob/master/2017-ICCV_Venice/How_To_Train_a_GAN.pdf
NIPS2016:
https://github.com/soumith/ganhacks



# 1:规范化输入

#2:修改损失函数(经典GAN)
-因为第一个公式早期有梯度消失的问题
- Goodfellow et. al (2014)
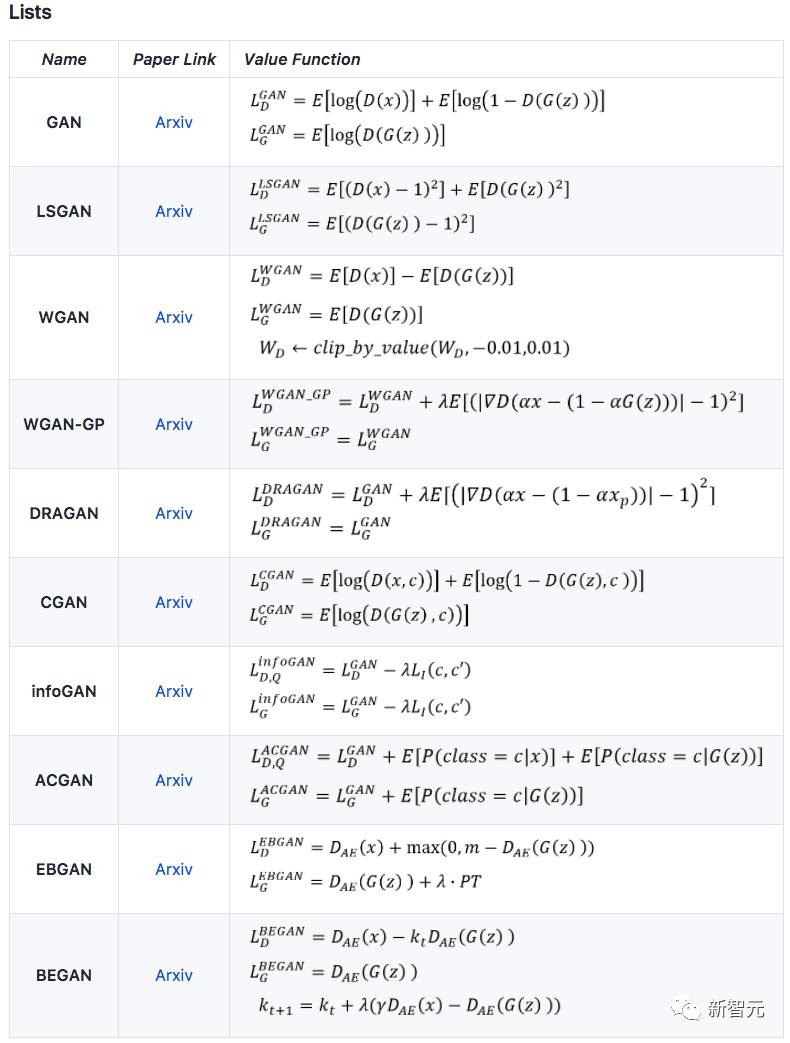
一些GAN变体
【TensorFlow】https://github.com/hwalsuklee/tensorflow-generative-model-collections
【Pytorch】https://github.com/znxlwm/pytorch-generative-model-collections
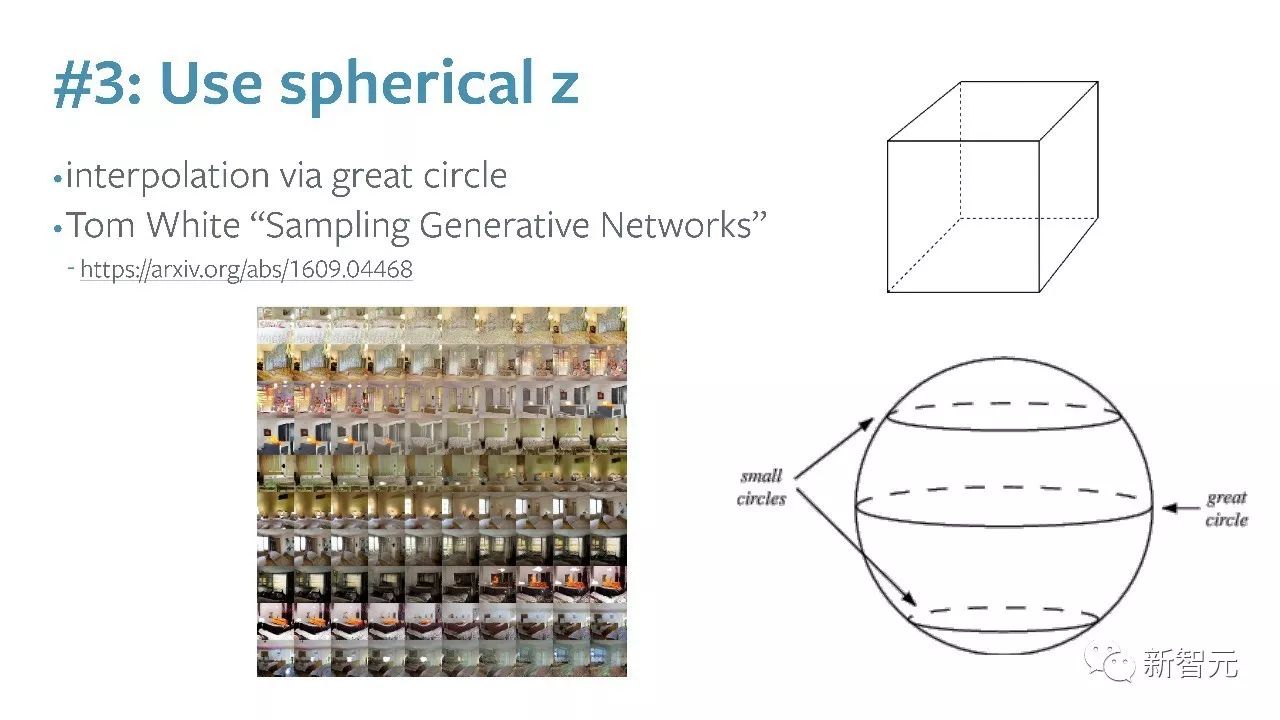
#3:使用一个具有球形结构的噪声z
- https://arxiv.org/abs/1609.04468

#4: BatchNorm

#5:避免稀疏梯度:ReLU, MaxPool
-PixelShuffle 论文:https://arxiv.org/abs/1609.05158

#6:使用Soft和Noisy标签
- Salimans et. al. 2016

#7:架构:DCGANs / Hybrids
- https://github.com/igul222/improved_wgan_training

#8:借用RL的训练技巧

#9:优化器:ADAM

#10:使用 Gradient Penalty
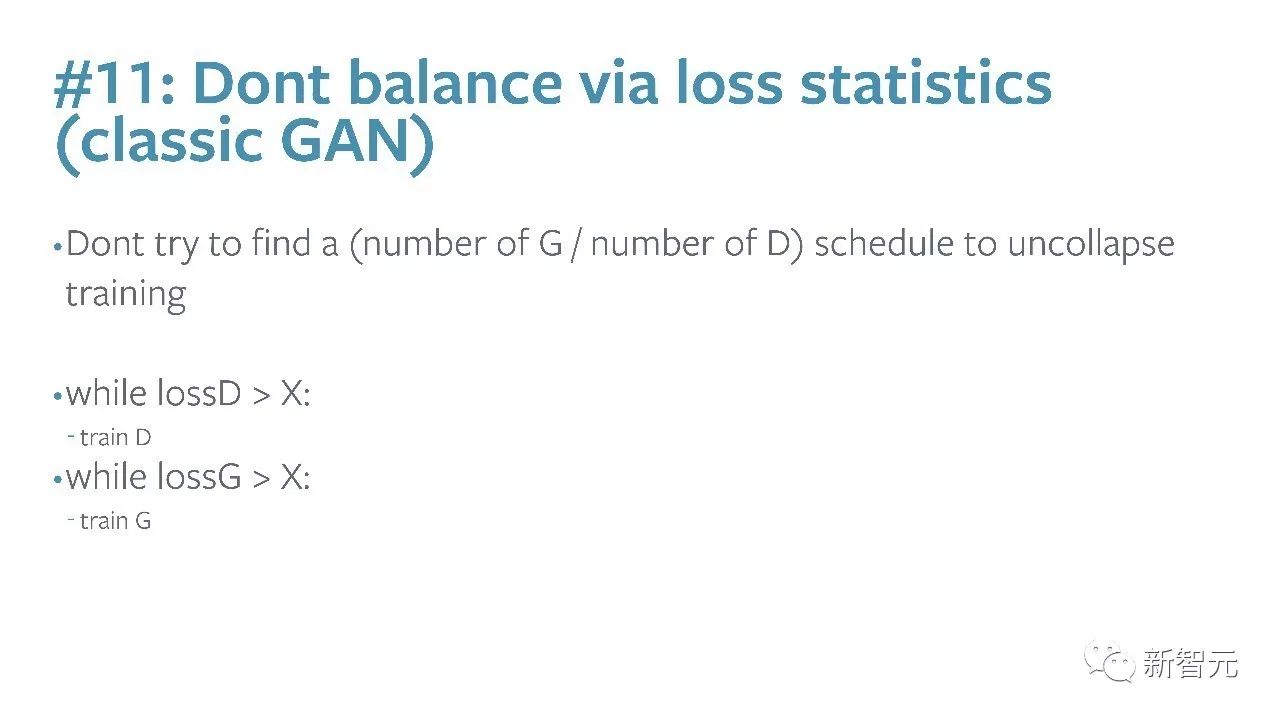
#11:不要通过loss statistics去balance G与D的训练过程(经典GAN)

#12:如果你有类别标签,请使用它们

#13:给输入增加噪声,随时间衰减
-
给D的输入增加一些人工噪声(Arjovsky et. al., Huszar, 2016)
-
给G的每一层增加一些高斯噪声(Zhao et. al. EBGAN)

#14:多训练判别器D
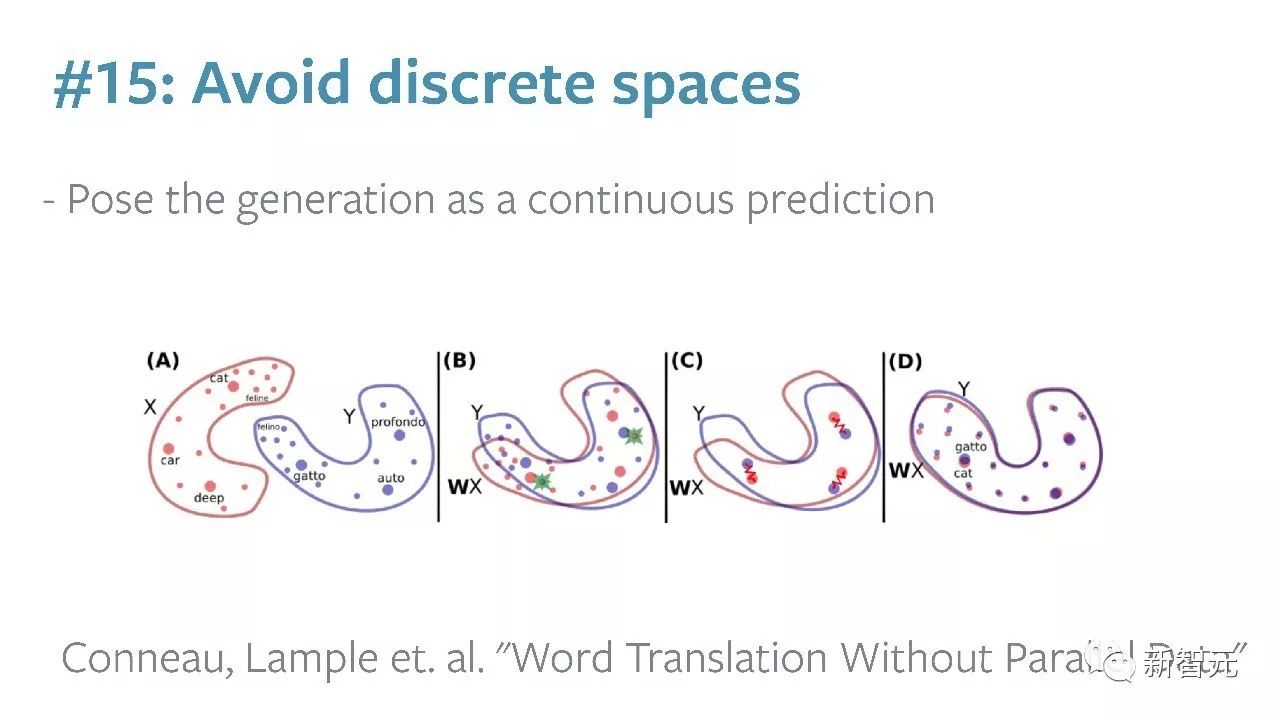
#15:避开离散空间











