Hadoop分布式文件系统(HDFS)是指被设计成适合运行在通用硬件上的分布式文件系统(Distributed File System)。
本文将介绍eBay ADI Hadoop team如何克服万难,在短短两小时内
将近 1000万 级别文件数量与 10PB 规模大小的数据全部迁移至新的namespace,从而达到RPC流量迁移的效果,保证了HDFS集群的稳定性。
本文所介绍的这场PB规模量级的数据迁移其实由来已久,当时我司内部因为新业务上的支持,导致HDFS集群数据量一度激增。通过每日的RPC(Remote Procedure Call,远程过程调用)总
量统计结果,整个集群的RPC处理量比之前翻了2~3倍之多;
随之而来,我们的HDFS集群承受了前所未有的RPC压力,以至于经常处于异常忙碌的状态,而关键SLA任务也会因为HDFS过慢而时
不时地发生延时问题。
上述症结已经不是通过打个简单的patch就能立马解决的问题,基于该背景,我们决定采用新加HDFS Federation的方式,将部分业务数据迁移到另一个新的namespace下。
我们在测试演练数据迁移过程中踩了许多大大小小的坑,不过最后经过团队小伙伴的共同努力,最终圆满完成了这项数据量庞大的跨namespace数据迁移,且迁移期间并没有影响到当天的
SLA任务。
本文将详细阐述并总结我们在此次数据迁移过程中踩过的坑,以及我们最后是如何将近
1000万
级别文件数量,
10PB
规模大小的数据,在短短
2小时
内全部迁移完成的。
数据迁移的大目标方向定好后,新NN环境搭建其实是一件比较容易搞定的事情(准备好一对新的NN节点,安装好Hadoop环境,加入到集群即可),而真正的难点,在于数据的迁移。
数据迁移首先要解决的问题就是:要迁移哪些业务数据?哪些数据迁移后能对我们的集群起到立竿见影的减压效果?
当然这得用数据说话,我们主要通过以下3个关键指标对大集群上的业务数据进行初步的分析:
-
物理数据量所占空间;
-
文件目录总数;
-
每个业务目录下所产生的RPC总数。
分析出结果后,我们综合考虑,选择其中一个关键业务目录,对其进行迁移,这个目录的业务数据规模在1000万,10PB这样的量级。
鉴于待迁移的数据量规模庞大,我们在确定迁移方案之前,针对Hadoop原生自带的DistCp工具做了一次性能测试,检验其数据拷贝效率是否能达到预期。
做了一个简单的数据测试,生成10TB数据,进行数据拷贝大约花了15分钟,换算而言1PB约为1500分钟。如果我们把1500分钟约为1天(1440分钟)来算的话,10PB就要花10天的时间进行拷
贝迁移,这显然无法令人接受。
上面给我们的要求是最多只允许2~3小时的窗口时间内(此时间允许服务downtime),分毫不差地完成所有数据的迁移。毫无疑问,这听上去对我们来说是一个巨大的挑战。
通过多次的讨论,我们基本确认出以下两种方案:
方案一,初始全量拷贝+多次增量diff的数据拷贝。
此方式的好处在于这个数据拷贝可以提前做,只有第一次全量拷贝时花的时间比较长,后续都通过增量拷贝的方式来同步那些发生了变化的数据。然后我们在最终做change的时间窗口同步
最后一次的diff数据即可。在技术可行性上,DistCp本身已经支持结合HDFS Snapshot的方式来做这样的增量拷贝。
此方案的缺陷在于实际操作性比较复杂,在最终拷贝前,我们需要定期地去同步增量的数据。而且这时候老的数据还不能删除,集群需要有富余的空间同时存储新老数据。至于定期同步增量
数据的方式,我们还得考虑自动化的方式来搞。
方案二,静态数据拷贝+最终动态数据的拷贝。
方案二和方案一在数据分层次拷贝的思想大方向是一致的。区别点在于这里我们只做最终一次的剩余动态数据的拷贝而不做多次小增量数据的拷贝。在数量级别上,它的量还是有一定规模的
。
在实际操作上,方案二比较容易施行,因为我们只要在最终拷贝前,提前拷贝走静态不变的数据,留最后变动的数据在最后一次操作完成即可。
于是我们决定采用第二种方案。紧接着,我们要面对的一个核心问题来了:如何大幅度提升DistCp的数据拷贝效率。
尽管面临的挑战非常巨大,但是后面还是得一步步开始,从而将困难由大化小,由小化无。本章节中,笔者将简单聊聊我们是如何一步步对DistCp做优化的。
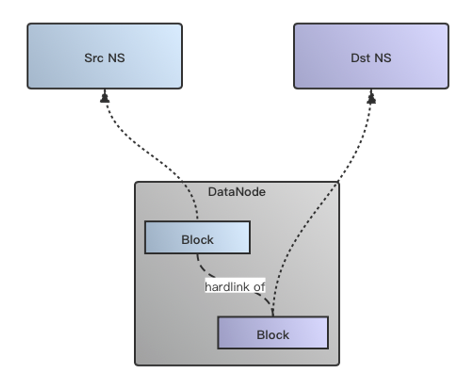
鉴于我们的集群处于HDFS Federation模式,下面的DN存储是共享的,所以并没有必要在物理数据层面进行拷贝。于是我们Backport了社区HDFS-2139 (HDFS-2139:Fast copy for HDFS)
的改动到我们内部版本中。
Fastcopy的拷贝过程与原始数据拷贝方式的最大区别在于物理数据是通过建立hardlink的方式来做,省去了实际数据拷贝的过程,以此大大缩短数据拷贝的时间,原理图如下所示:
实现了HDFS Fastcopy后,我们将HDFS Fastcopy的文件拷贝操作集成到DistCp的文件拷贝过程中,通过新增一个useFastcopy的option开关来控制是否走Fastcopy的方式。
完成Fastcopy
这块的优化改动之后,我们做了性能对比测试,结果相比原生DistCp拷贝,速度提升了5倍之多。在Fastcopy的模式下,DistCp的map task就只需要做createFile,addBlock这样的简单
HDFS RPC操作了。
在实际测试过程中,我们经常发现因为文件size分布不均衡,导致长尾任务出现。比如要拷贝的目录里有众多的小文件,然后突然有个子目录里都是GB级别这样的大文件,于是这类大文件
被分到的那些task往往就会变得很慢,如果是在按照文件目录数进行划分的strategy(设置DynamicInputFormat)中则更为为明显。
但是如果按拷贝文件size进行均分,在Fastcopy下时其实是没有意义的,因为我们并不copy实际的物理数据。
我们想了一个办法,在还是基于文件size分配策略的逻辑下,对不足1个块大
小的小文件统统按照1个块的size算,来减少大文件和小文件之间的差异性影响。
这里我们对DistCp的UniformSizeInputFormat进行了上面逻辑的优化,在此改造后,长尾现象得到了明显
的改善。
在拷贝大目录操作的时候,我们发现DistCp在所有task执行后经常会卡在最后commit阶段,后来才知道是在做目录ACL的preserve保留操作。这与文件ACL perserve是在map task里操作的
不同,目录是统一放在最后做的。
我们将此操作进行了前置,如此一来,这步操作就同样被分散到了各自task内执行。此改进优化了DistCp最后commit阶段的执行时间。
在拷贝大量数据时,某些task难免会出现因为网络或者机器层面原因导致的个别任务拷贝失败的情况。这个时候如果在不指定ignore failure(忽略失败)的情况下,DistCp就会执行失败
。DistCp目前是有现有参数控制这个逻辑的。
另外,为了确保能够收集到失败拷贝的详细信息,我们新增了一个reduce task来收集前面所有map task拷贝失败的拷贝记录(包括文件和目
录),然后由reduce task写出到一个文件里。后续我们再对失败文件进行二次拷贝和恢复。
当我们测试拷贝100万级别以上的数据时,偶尔个别文件拷贝失败是大概率会发生的。所以新增
reduce task做failure信息的收集十分必要。附带了额外reduce task的distcp执行图如下所示:
在拷贝过程中,个别慢节点、异常节点的情况也时有发生,当集群规模比较大的情况下,此类问题很难避免。我们通过调整一些参数来让task进行更快的重试来应对上述情况。比如
ipc.client.connect.max.retries.on.timeouts=3,最多允许client连接3次超时,默认是45次(相当之多了,每次超时会等待20秒)。
另外我们加大了task的超时时间配置到30分钟
(mapreduce.task.timeout),以避免过短的超时时间配置,导致任务重试,效率不高。
此外我们将DistCp Job metadata的目录数据指向另外一个速度更快的内部HDFS集群,避免DistCp任务因为读写自身内部metadata数据操作
过慢从
而影响整体DistCp的执行。
此相关参数为
yarn.app.mapreduce.am.staging-dir。
以上提到的参数都可以通过-D(比如-Dipc.cl
ient.connect.max.r
etries.on.timeouts=3)的方式动态传入,无须修
改本地配置文件。
在经过前面五部分的优化之后,我们的DistCp拷贝相较原生模式,在稳定性和效率上已有很大的提升了。但是重新来看之前定的2~3小时内迁完全部数据的目标,难度还是不小。
于是我们挑
选了前面几个大头任务,逐个目录对里面的数据进行了分析。业务的数据体量虽然规模庞大,但是每日的增量数据,占比不会太高,大部分现有的还是老的历史数据。如果我们将业务历史不
变的数据提前拷走,只在最后change的窗口拷贝当天新增的数据,应该就可以达到我们的预期目标了。
后经过分析,1000万左右的文件数,我们能实现拷贝走大约一半的数据,最后留另外的500~600万的数据在操作当天迁移走。按照我们在集群中的测试情况来预演,400~500万的数据大约在1
个半小时可以迁移完成,这就足以达到我们的目标了。
对此我们额外实现了类似于DistCp -filter功能的whitelist白名单拷贝以及snapshot dt当天日期拷贝的功能。随后我们基于自定义的filter功能在正式数据迁移日期前进行了历史数据
的拷贝。然后留了最后500~600万规模的数据在change当天进行拷贝。
上文提到过,我们内部集群采用的是Federation方式,对client而言是通过HDFS Viewfs的方式进行访问的。这里我们将一个隶属于原目录下mapping的子目录进行了拆离,这样就组成了嵌
套Viewfs mapping的情况。但是我们现有Hadoop版本对于嵌套Viewfs mapping并不支持。
我们尝试实现了社区HADOOP-13055(Implement linkFallback for ViewFileSystem)实现
failback的mapping语义来支持这种使用场景,但最后还是通过实现了嵌套mapping的功能来解决这个问题。
数据迁移过程前后的数据一致性同样是我们需要重视的问题。在数据拷贝开始阶段,HDFS上正在open的待拷贝数据必须要被强制关闭,否则在拷贝过后可能会出现HDFS此文件元数据状态和
实际磁盘写出文件状态不一致的情况。
我们基于社区HDFS-10480 (Add an admin command to list currently open files)的list当前open file的功能,主动调用recoverLease call
来达到NN端指定目录close open file的功能。以此确保数据拷贝前不会有open file的存在。
在最后数据迁移前,我们总共进行了四轮系列的测试。










