导语:
情感情绪检测是自然语言理解的关键要素。最近,我们将原来的项目迁移到了新的集成系统上,该系统基于麻省理工学院媒体实验室推出的NLP模型搭建而成。
情感情绪检测是自然语言理解的关键要素。最近,我们将原来的项目迁移到了新的集成系统上,该系统基于麻省理工学院媒体实验室推出的NLP模型搭建而成。
代码已经开源了!(详见GitHub:https://github.com/huggingface/torchMoji )
该模型最初的设计使用了TensorFlow、Theano和Keras,接着我们将其移植到了pyTorch上。与Keras相比,pyTorch能让我们更自由地开发和测试各种定制化的神经网络模块,并使用易于阅读的numpy风格来编写代码。在这篇文章中,我将详细说明在移植过程中出现的几个有趣的问题:
-
如何使用自定义激活功能定制pyTorch LSTM
-
PackedSequence对象的工作原理及其构建
-
如何将关注层从Keras转换成pyTorch
-
如何在pyTorch中加载数据:DataSet和Smart Batching
-
如何在pyTorch中实现Keras的权重初始化
首先,我们来看看torchMoji/DeepMoji的模型。它是一个相当标准而强大的人工语言处理神经网络,具有两个双LSTM层,其后是关注层和分类器:
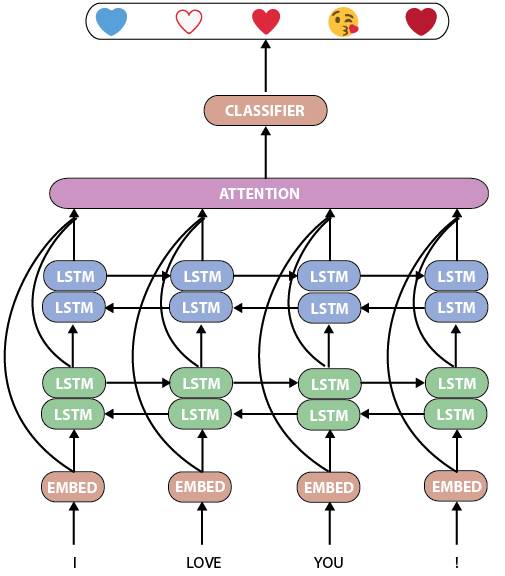
torchMoji/DeepMoji模型
如何构建一个定制化的pyTorch LSTM模块
DeepMoji有一个很不错的特点:Bjarke Felbo及其协作者能够在一个拥有16亿条记录的海量数据集上训练该模型。因此,预先训练的模型在此训练集中具有非常丰富的情感和情绪表征,我们可以很方便地使用这个训练过的模型。
该模型是使用针对LSTM的回归内核的Theano/Keras默认激活函数hard sigmoid训练的,而pyTorch是基于NVIDIA的cuDNN库建模的,这样,可获得原生支持LSTM的GPU加速与标准的sigmoid回归激活函数:
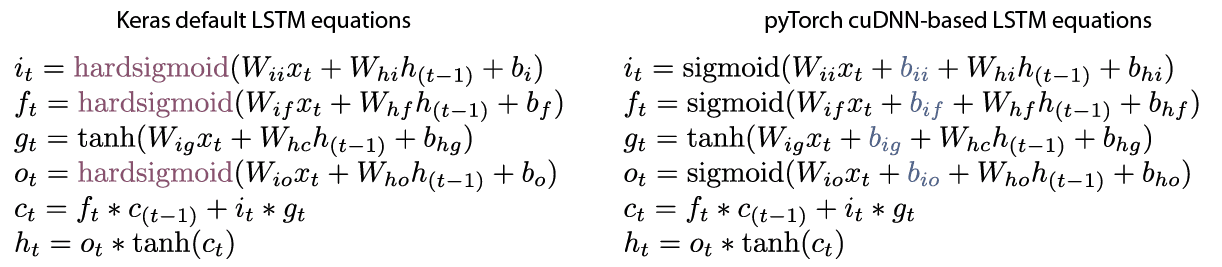
Keras默认的LSTM和pyTorch默认的LSTM
因此,我写了一个具有hard sigmoid回归激活函数的自定义LSTM层:
def LSTMCell(input, hidden, w_ih, w_hh, b_ih=None, b_hh=None):
"""
A modified LSTM cell with hard sigmoid activation on the input, forget and output gates.
"""
hx, cx = hidden
gates = F.linear(input, w_ih, b_ih) + F.linear(hx, w_hh, b_hh)
ingate, forgetgate, cellgate, outgate = gates.chunk(4, 1)
ingate = hard_sigmoid(ingate)
forgetgate = hard_sigmoid(forgetgate)
cellgate = F.tanh(cellgate)
outgate = hard_sigmoid(outgate)
cy = (forgetgate * cx) + (ingate * cellgate)
hy = outgate * F.tanh(cy) return hy, cydef hard_sigmoid(x):
"""
Computes element-wise hard sigmoid of x.
See e.g. https://github.com/Theano/Theano/blob/master/theano/tensor/nnet/sigm.py#L279
"""
x = (0.2 * x) + 0.5
x = F.threshold(-x, -1, -1)
x = F.threshold(-x, 0, 0)return x
这个LSTM单元必须集成在一个完整的模块中,这样才可以使用pyTorch所有的功能。这个集成相关的代码很长,建议直接引用到Github中的相关源代码。
Keras和pyTorch中的关注层
模型的关注层是一个有趣的模块,我们可以分别在Keras和pyTorch的代码中进行比较:
class Attention(Module):
"""
Computes a weighted average of channels across timesteps (1 parameter pr. channel).
"""
def __init__(self, attention_size, return_attention=False):
""" Initialize the attention layer
# Arguments:
attention_size: Size of the attention vector.
return_attention: If true, output will include the weight for each input token
used for the prediction
"""
super(Attention, self).__init__()
self.return_attention = return_attention
self.attention_size = attention_size
self.attention_vector = Parameter(torch.FloatTensor(attention_size)) def __repr__(self):
s = '{name}({attention_size}, return attention={return_attention})'
return s.format(name=self.__class__.__name__, **self.__dict__) def forward(self, inputs, input_lengths):
""" Forward pass.
# Arguments:
inputs (Torch.Variable): Tensor of input sequences
input_lengths (torch.LongTensor): Lengths of the sequences
# Return:
Tuple with (representations and attentions if self.return_attention else None).
"""
logits = inputs.matmul(self.attention_vector)
unnorm_ai = (logits - logits.max()).exp()
max_len = unnorm_ai.size(1)
idxes = torch.arange(0, max_len, out=torch.LongTensor(max_len)).unsqueeze(0) if torch.cuda.is_available():
idxes = idxes.cuda()
mask = Variable((idxes < input_lengths.unsqueeze(1)).float())
masked_weights = unnorm_ai * mask
att_sums = masked_weights.sum(dim=1, keepdim=True)
attentions = masked_weights.div(att_sums)
weighted = torch.mul(inputs, attentions.unsqueeze(-1).expand_as(inputs))
representations = weighted.sum(dim=1)return (representations, attentions if self.return_attention else None)class AttentionWeightedAverage(Layer):
"""
Computes a weighted average of the different channels across timesteps.
Uses 1 parameter pr. channel to compute the attention value for a single timestep.
"""
def __init__(self, return_attention=False, **kwargs):
self.init = initializers.get('uniform')
self.supports_masking = True
self.return_attention = return_attention
super(AttentionWeightedAverage, self).__init__(** kwargs) def build(self, input_shape):
self.input_spec = [InputSpec(ndim=3)] assert len(input_shape) == 3
self.W = self.add_weight(shape=(input_shape[2], 1),
name='{}_W'.format(self.name),
initializer=self.init)
self.trainable_weights = [self.W]
super(AttentionWeightedAverage, self).build(input_shape) def call(self, x, mask=None):










