点击上方
蓝字
CG世界 关注CG我们
“ 感知CG · 感触创意 · 感受艺术 · 感悟心灵 ”
中国极具影响力CG领域自媒体
文/索菲亚·嘟胖
CG世界建设小组
付国宝审核
各位早哇!动笔写今天的文章之前,我一直在翻看早些年给大家更新的文章,其中有一篇开头是这样写的:
“有的伙伴说,CG世界快看不下去了,看了作品受打击,看了技术跟不上,看了留言伤自尊。”
![]()
如今时间过去很久了,大家不仅依然在看我们的文章,而且还有越来越多的小伙伴愿意与我们同行,很感谢你们一直以来的陪伴和支持
(也没什么好表示的,不然给大家劈个叉吧)
。只是突然想感慨一下,这并不是结束语,是今天的Opening,打算和大家唠点干
(gān)
的东西。

之前有人利用黑科技把《射雕英雄传》里朱茵的脸换成了杨幂的脸,我们先不把问题上升到肖像权和道德观的高度层面哈,只是单纯地说这种人工智能技术还是挺厉害的,利用到了AI机器学习中的深度学习方式。
现如今,
深度学习已经慢慢开始成为制作视觉效果的一种新型主要工具,虽然仍处于起步阶段,但确实在改变着传统方式,与目前现有的模型材质灯光渲染的流程不同,深度学习是基于幻象或者合理地创建基于训练数据集图像的过程。今天咱们就捋着这条线儿来了解一下。
早在Siggraph2016大会上就首次展出了
RGB视频实时人脸捕捉和重演技术Face2Face
,这是面部替换技术的一个里程碑式的发展。

利用面部追踪技术和图像算法,将源演员的面部表情、说话时肌肉的变化非常逼真地复制到另一个视频中的目标演员脸上,从而实现面部重演。这种技术应该算是
第一个能够进行实时面部转换的模型
,准确度和真实度比传统面部图形处理方式的结果要精确很多。
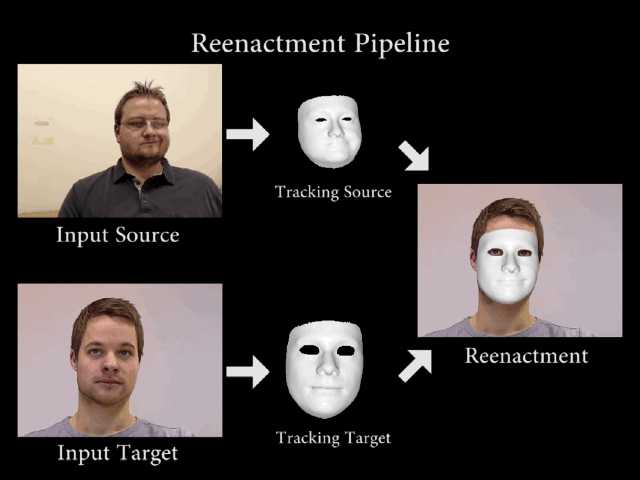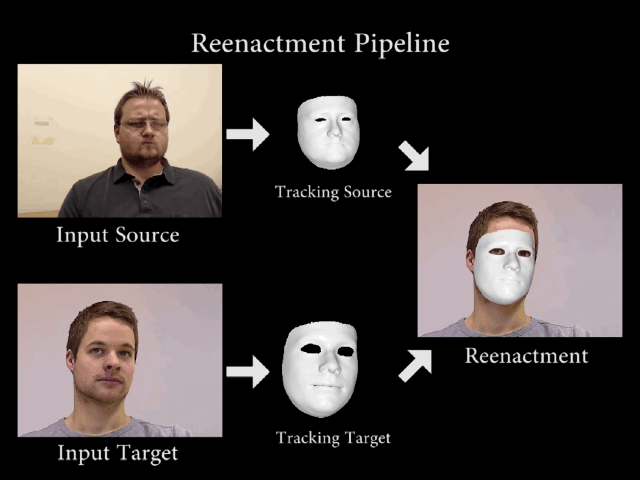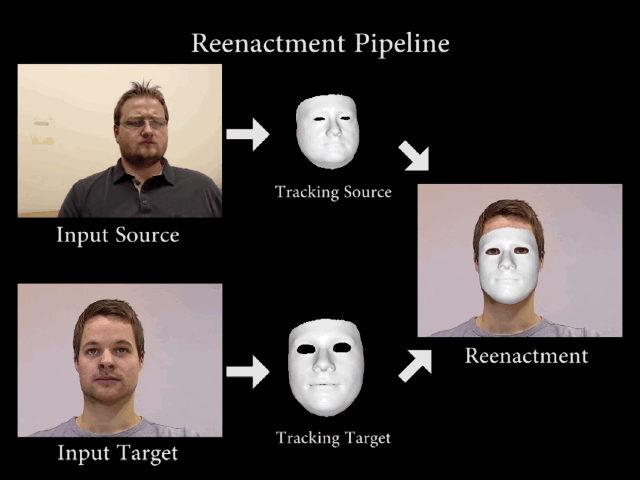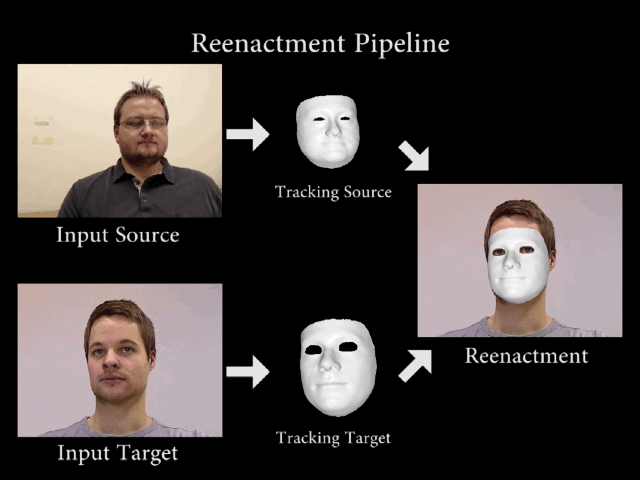
▲流程分解图
通过训练神经网络,使用深度学习方法来生成实时动画语音
▲点击视频直观了解该项技术
“动画方面的自动唇形同步”技术是在Siggraph2017大会上发表的。通过深度学习的方法不仅可以为
讲英语的演员自动同步唇形,还可以适用于其他语种或是唱歌的动作
。
大概就是这么一个过程哈:研究人员训练一台电脑,根据获得的语音音频,预测发声的口型;利用现有的语音识别软件,将音频转录成可应用于参考面部的音素
(音素就是语音中的最小单位,依据音节里的发音动作来分析,一个动作构成一个音素)
,把得到结果重定向到任何实时的CG角色绑定上,使动画人物唇部和发声口型实现同步。

研究人员介绍说,这种系统适用于任何语言、任何风格,甚至是任何输入方式的演讲者,它已经
率先在动画制作中取得了一定进展
,艺术家们通过标准编辑软件就可以轻松的创作和编辑风格化动画。
Deepfakes其实是”deep machine learning“
(深度机器学习)
和”fake photo/video“
(假照片/视频)
组合在一起的缩写,除了一开始我们提到的古装剧演员换脸的例子,其实早在2017年年末就被不正当应用起来了,不仅有伤风雅,而且侵犯了很多好莱坞明星的肖像权,造成了恶劣影响,大家应该都知道这个事儿哈。

左图为源视频,右图为处理后的视频。这种黑科技是利用深层神经网络学习系统,来获取源视频中人物的面部动作,通过编码和解码的过程,获得合成后的目标人物面部。
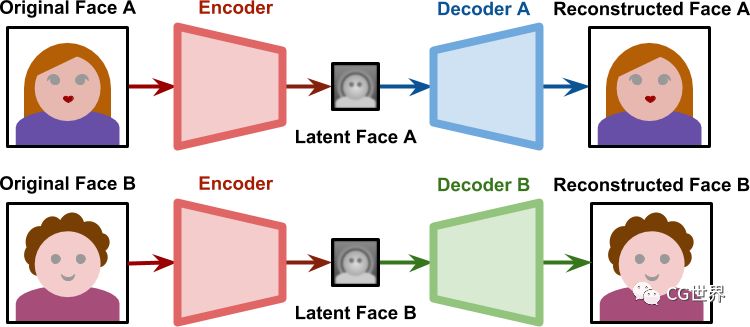
▲训练过程图解
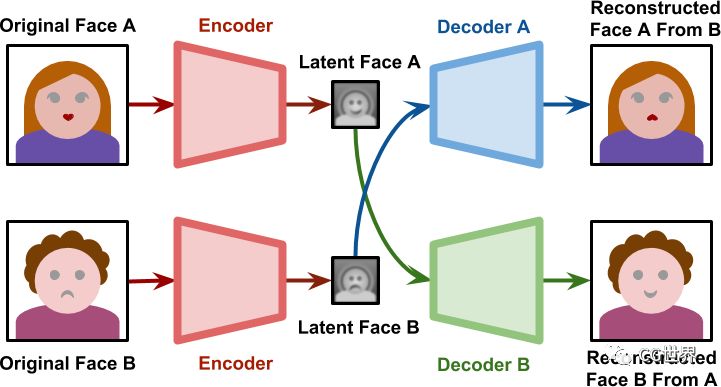
▲生成过程图解
上面两张图清晰地解释了训练过程和生成过程。训练阶段两个网络分开进行,共享相同的编码器,拥有各自不同的解码器;训练结束后的生成阶段,源A生成的潜在面部A传递给解码器B,实现源B的面部重建过程,另一个网络同理。我们可以通过过程图大致了解一下,再深入一些的咱们就不讨论了蛤
(主要是我理解的就很浅薄)
。
但Deepfakes并没有那么神通广大,重建的面部存在
”瞪眼无神“
,也就是不能眨眼的问题,就算是能眨个几下,
频率也远远低于正常人类的眨眼范围
。这么说来,黑科技还是存在一些bug的。
用视频中的人物面部表情驱动另一个目标视频中的人物表情

时隔
Siggraph2017
一年之后,研究人员在Siggraph2018大会上发布了Deep Video Portraits,从字面上来翻译就是“深度视频肖像”。
很大白fà的解释就是,源视频中人物的动作,比如晃脑袋、做鬼脸、各种神态之类的等等,都可以呈现在目标视频中的人物面部,看上去似乎是Deepfakes的升级版。有一张图完整地展示了这种技术的整个实现过程。
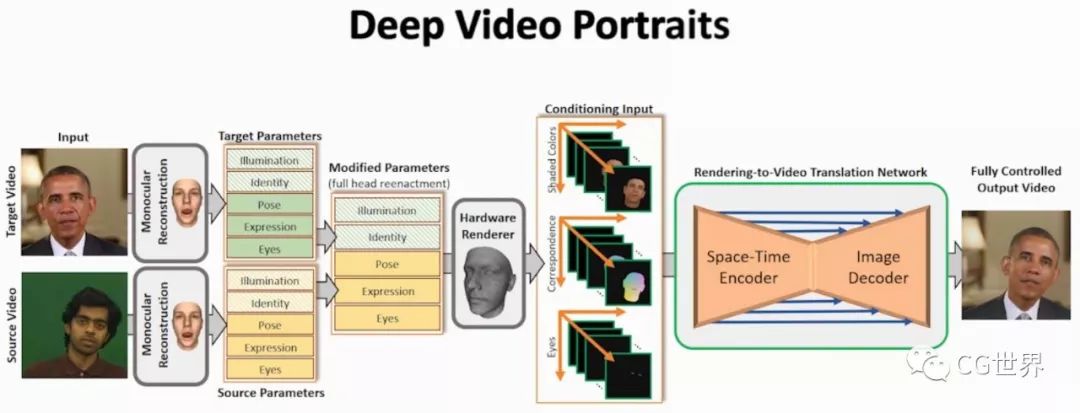
同时输入目标视频与源视频
(由上至下)
,通过重建跟踪处理得到一系列目标参数与源参数,两种参数通过融合和修改后得到新的全尺寸面部重演参数,包括照明、识别、姿势、表情和眼睛
(由上至下)
;之后对修改过的面部模型进行硬件渲染,然后输入导入到视频转换的网络中。在网络中通过“时空编码”再到“图像编码”,就可以控制目标视频汇总的人物肖像了。

这套技术所具有的优点实在太多了,比如可以实现包括阴影在内的人物肖像控制、精准传递表情和神态、实时交互等等。
翻译和本地化视频内容的新方法
仅仅重现各种面部表情和神态并没有什么实际意义,技术还得要改变生活,为人们的工作方式带来便利才可以。
2018年英国的Synthesia公司为BBC的项目提供了可以无缝翻译和本地化视频内容的新方法“原生配音”(Native Dubbing)
,它是利用人工智能或机器学习,使视频演员的唇形动作与新的对话轨道实现同步,消除了语言翻译障碍,解决了目前不同语言配音和ADR
(根据同期声参考声带,进行对白重置的技术)
所可能产生的问题。来个视频感受一下。
哦,不要觉得Synthesia公司很陌生,毕竟公司的一位创立者,就是2016年Face2Face技术背后的关键研究人员之一。
那么Native Dubbing大概的流程是如何进行的呢?
公司并没有公布详细地内部技术方法,我们目前只是知道一个大概的情况。

第一阶段是提供数据,用于创建新语言驱动的数字面部。
需要主持人或者是演员在正常状态下说3-5分钟的话,要带着扭头/转头的动作。
这段素材在随便什么地方拍摄都可以,对舞台和特定灯光基本没有什么要求。
第二阶段是使用Synthesia技术来翻译刚刚拍摄素材中的对话内容,也就是我们常说的翻译成目标语言。
或者有的时候制作人想把源视频替换成自己也是可以的,只要同时上传自己的音频和视频就可以了。

当然如果最后得出的效果还是不够真实,研究人员会调整流程重新来过。
这个技术
最关键部分就是可以精确生成源视频的无标记面部跟踪
。
我们常提到的机器学习,在这项技术中具体指的是头部和面部被跟踪和被学习的过程。
利用人工智能技术,在训练数据的基础上创建每一帧都非常真实的面部效果。
它和传统意义上的3D建模、添加材质纹理、制作动画、渲染的过程是不同的。

整个过程完全都是自动化的,不需要人工干预,差不多一段视频是在几天之内分阶段进行的。
在机器学习的过程中,卷积神经网络的训练过程需要花一些时间,至少得12个小时起步。
训练完成之后,面部重新生成动画差不多就是实时进行的了。
所以说在面部学习和深度学习的步骤完成之后,整个流程进行地就会快一些。
通过这样的方式可以消除不同语言之间所产生的障碍,对于制作高端产品视频和像Youtube UP主这类需要把视频翻译成更多语言的用户群体来说,Native Dubbing是很方便实用的,既促进文化交流,又包容了多样性文化。
目前Synthesia公司正在搭建一个云平台,想要快速地把这项技术传达给世界各地的视频内容创建者。
Video Dialoge Replacement
™
*
这部
分只聊技术,不代表CG世界任何政治观点
前面咱们说了一些关于图像分类、识别和合成方面的技术,还说了在翻译视频中的唇形同步技术,接下来咱们再说说和视频对话替换有关的。
一家位于以色列的初期创业公司Canny AI
(网站链接是https://www.cannyai.com/)
即将发布他们的
VDR™(视频对话替换)程序
,可以把视频中的所有对话替换成其他内容,并发布了一段把世界各国领导人的正式演讲内容剪到一起,替换上约翰·列侬的歌曲《Imagine》,成了各国领导人合唱同一首歌的视频。

▲长按识别二维码观看
他们为什么会想到研发这么一种技术呢?还得从一部巴西反乌托邦题材的Netflix网剧说起。










