第一战,AlphaGo 赢了!几乎不出人意料。
5 月 23 日,中国围棋协会和浙江省体育局携手谷歌联合主办的「中国乌镇·围棋峰会」正式开幕,直到 5 月 27 日,柯洁与 AlphaGo 的三番棋人机大战以及人机团队赛、配对赛将陆续展开。

大赛启动仪式
关于这次围棋人机对话,有几大悬念引人注目。现役最强棋手柯洁是否有机会获胜还是将完全败北——这无疑是本轮对战的最大看点。此外,再次出战的 AlphaGo 是否已经是使用全新方式训练的新版本也是一大焦点。时隔 4 个多月,AlphaGo 的能力是否又有提升?它能否将人类对于围棋的理解带上一个更新的高度?这些问题即将在短短五天的对决中揭晓。
除了现场报道之外,机器之心邀请阿尔伯塔大学教授、计算机围棋顶级专家 Martin Müller 以及《深度强化学习综述》论文作者李玉喜博士,共同观看了比赛直播。Müller 教授所带领的团队在博弈树搜索和规划的蒙特卡洛方法、大规模并行搜索和组合博弈论方面颇有建树。实际上,参与了大师级围棋程序 AlphaGo 的设计研发的 David Silver 和黄士杰(Aja Huang)(他们分别是 DeepMind 的 AlphaGo 相关 Nature 论文的第一作者和第二作者)都曾师从于他。李玉喜博士是加拿大阿尔伯塔大学计算机系博士、博士后。致力于深度学习、强化学习、机器学习、人工智能等前沿技术及其应用。曾任电子科技大学副教授;在美国波士顿任资深数据科学家等。2017 年 1 月在 arXiv 上发表《Deep Reinforcement Learning: An Overview(深度强化学习综述)》论文 。

Martin Müller 教授和机器之心一起观看直播
AlphaGo 第一局意料之中的胜利
下午 14:47,在经过了 4 小时 17 分钟的激烈比赛之后,AlphaGo 以四分之一子的优势获胜,这并不让人感到意外。
比赛前一天,柯洁在微博上表达了自己对即将到来的比赛的看法和期待,字里行间并没有透露出击败 AlphaGo 的信心,他在微博上写道:「无论输赢,这都将是我与人工智能最后的三盘对局……现在的 AI 进步之快远超我们的想象。像国产的绝艺、日产的 ZEN 虽然和 Alphago 还有着较大差距,但已经表现出超强的实力了... 我相信未来是属于人工智能的。」
这场比赛不仅是 DeepMind 的盛事,也得到了 Alphabet 高层的重点关注。DeepMind CEO Demis Hassabis 和 Alphabet 总裁 Eric Schmidt 都来到了现场。
「祝柯洁好运!」赛前,Hassabis 表示了对围棋界深深的谢意,他说,中国是人类围棋的诞生之地。此次比赛的宗旨在于探索新打法。围棋世界就好像宇宙一般,再过一万年也不可能穷尽所有的打法。或许人工智能可能提供新的启迪。去年和李世乭的比赛结束后回到伦敦,DeepMind 对 AlphaGo 进行了全新的架构更新,推出了升级版本 Master,希望 AlphaGo 能走自己创新打法的路。
Hassabis 强调:「这不是人机大赛,而是人类使用机器探索新的方法,AlphaGo 就像哈勃望远镜,能帮助我们看到更远的未知。不管结果如何,最终胜利属于人类。」
现年 19 岁的柯洁是中国围棋九段选手,祖籍浙江丽水。他从 5 岁就师从周宗强五段正式开始学棋,2008 年 10 岁升初段开启职业生涯。他曾获得第 2 届百灵杯世界围棋公开赛冠军、第 20 和 21 届三星杯世界围棋公开赛冠军、第 2 届梦百合杯世界围棋公开赛冠军,在世界大赛中曾创造过 14 连胜的战绩。在本次围棋人机大战开打前夕,围棋排名网站 Goratings 更新了截至 5 月 21 日的世界围棋等级分排名。将在 23 日-27 日和 AlphaGo 展开对决的柯洁九段继续毫无悬念继续领跑,他与第二名朴廷桓的分差已有 30 分之多。
这场围棋人机大战是从上午 10:30 开始的;中国棋院院长华以刚、世界围棋女子冠军徐莹组合与常昊张璇夫妇轮番进行了讲解。

柯洁执黑子,第一手棋,下在右上角,以示对对手的尊敬。黄博士代替 AlphaGo 执白子。与 AlphaGo 交手后,柯洁研究了一年多 AlphaGo 喜欢的三三式,吸取了教训,对 AlphaGo 的落子 有所防范,并率先在右下角点三三,使出了 AlphaGo 的下法。「柯洁的这一步是 AlphaGo 的风格」Müller 说道。「在去年 AlphaGo 比赛之后,很多顶尖棋手都已分析了 AlphaGo 的棋风,并将其应用于实战,柯洁最近已在正式比赛中使用了这种下法并获胜。」柯洁棋风依旧强硬,AlphaGo 还是不走寻常路。
比赛过程中柯洁完全沉浸在自己的思考中,几乎未抬头看对面的黄博士一眼。
比赛 4 个小时之后,这场人机对弈大战结束,AlphaGo 以四分之一的子获胜。最终柯洁用时 2 小时 47 分,AlphaGo 用时 1 小时 30 分。自此,当前世界排名第一的棋手和人工智能 AlphaGo 的第一局比赛落下了帷幕,结果基本上没有超出任何人(包括柯洁自己)的预料。
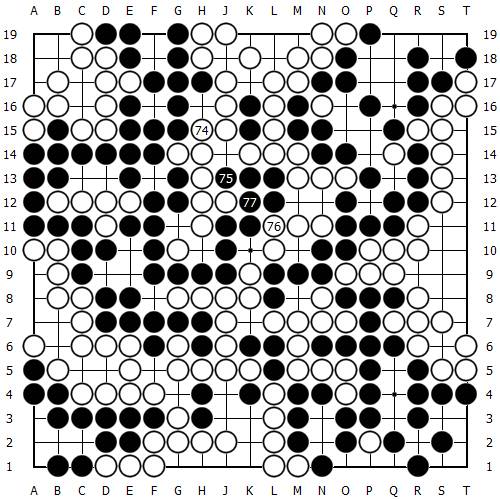
结局盘面
柯洁与 AlphaGo 的第二局比赛将在 5 月 25 日上午 10:30 开赛,柯洁能否在下一场比赛上取得出人意料的成绩,让我们拭目以待。
AlphaGo 升级版
过去一年多,只要你稍微关注过科技新闻,就一定看到过 AlphaGo 的名字(有时也被人称为「阿尔法狗」)。去年 3 月份,AlphaGo 成为了世界上第一个击败世界顶级职业选手的围棋程序。在击败了李世乭后,AlphaGo 或许已经成为了世界上最著名的人工智能程序。
但大胜李世乭的 AlphaGo 版本终究还是输了一场,所以还并不完美。据了解,当时 AlphaGo 开始主要是依靠大量学习人类棋手的棋谱来提高棋艺。随后 AlphaGo 进入到完全的自我深度学习阶段,也就是完全摒弃人类棋手的思维方式,按照自己(左右互搏)的方式研究围棋。对于 AlphaGo 是否使用人类棋谱的问题,李玉喜博士评论说:「计算机围棋是一个优化问题,对于 AlphaGo,就是在优化它所采用的深度神经网络的参数。从优化的角度说,可以从任何初始值开始,利用随机梯度下降等算法进行优化。利用人类棋谱,可以帮助设置一组不错的初始值,很可能可以提高寻找最优参数的效率;而如果不用人类棋谱,理论上可以,但一开始对参数的搜索可能有些盲目,个人认为不应该采用这个方案。」
2016 年 1 月 28 日,Nature 杂志以封面论文的形式介绍了 DeepMind 团队开发的人工智能程序 AlphaGo,这也就是后来击败韩国棋手李世乭的 AlphaGo 版本。
AlphaGo 结合了监督学习与强化学习的优势。通过训练形成一个策略网络,将棋盘上的局势作为输入信息,并对有所可行的落子位置形成一个概率分布。然后,训练一个价值网络对自我对弈进行预测,以-1(对手的绝对胜利)到 1(AlphaGo 的绝对胜利)的标准,预测所有可行落子位置的结果。AlphaGo 将这两种网络整合进基于概率的蒙特卡罗树搜索(MCTS)中,实现了它真正的优势。
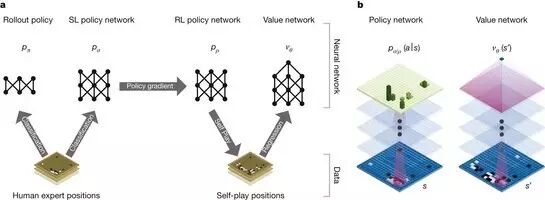
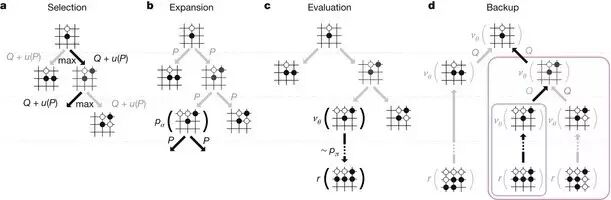
在获取棋局信息后,AlphaGo 会根据策略网络(policy network)探索哪个位置同时具备高潜在价值和高可能性,进而决定最佳落子位置。在分配的搜索时间结束时,模拟过程中被系统最繁琐考察的位置将成为 AlphaGo 的最终选择。在经过先期的全盘探索和过程中对最佳落子的不断揣摩后,AlphaGo 的探索算法就能在其计算能力之上加入近似人类的直觉判断。
但是新版的 AlphaGo 产生大量自我对弈棋局,为下一代版本提供了训练数据,此过程循环往复。
AlphaGo 的棋风一直为人惊叹,与其交战过的大多数棋手都感叹它的不可琢磨,可谓是违和感十足,却极具杀伤力。金成龙曾表示:「AlphaGo 机器人下棋的方法是人类想不出来的。它有几次小的失误,之前我认为这种失误对李世石是有利的,现在看起来 AlphaGo 是以小失误换取更大的胜利。」
AlphaGo 的强大之处不在于一招一式,而在于对每一局比赛展现出的全新视角。虽然围棋风格略显抽象,但 AlphaGo 的策略展示了灵活与开放的精神:没有先入为主的训练让它找到了最有效的下棋方式。实用哲学让 AlphaGo 经常走出违反直觉——但却最为合理的走子。
尽管围棋是一个有关圈地的游戏,但胜负手却在于对不同战区之间的取舍平衡,而 AlphaGo 擅长创造这种平衡。具体来说,AlphaGo 擅长运用「影响力」——已有棋子对自己周围的影响为自己谋取优势。虽然 AlphaGo 的价值网络不能准确地计算出影响的数值,但它的价值网络能够一次性考虑棋盘上的所有棋子,以微妙和精确的方式做出判断。正是这样的能力让 AlphaGo 把自己在局部的优势转化为整个比赛的胜势。
作为 David Silver 与黄士杰在阿尔伯塔大学的导师,Martin Müller 对他的学生们感到骄傲:「我对他们感到非常骄傲,他们都曾是我的博士/博士后学生,在阿尔伯塔也得到了强化学习的先驱 Richard Sutton 的教导。在阿尔伯塔期间,深度学习技术还未发展起来。那时我们的围棋程序还非常简单,没有加入蒙特卡洛树搜索机制,只应用了强化学习。随后他们在 DeepMind 获得了大量资源,这也为其后的成功打下了基础。」
此前,在 4 月 10 日下午,谷歌在北京的中国棋院召开新闻发布会,正式宣布 AlphaGo 将于今年 5 月 23 日在浙江乌镇对决以柯洁为代表的中国顶尖棋手。与此同时,DeepMind 官方也发表了一篇博客对新版 AlphaGo 的下棋思路进行了讲解。作为 AlphaGo 的一员,樊麾在 DeepMind 的这篇博客中写到:AlphaGo 在最近的比赛里展现出了开创性的棋风,其中最引人瞩目的是早期点三三和全新的「妖刀」变化——每个都违反了常规理论,但在更深入的研究中被证明是高明的下法。
实际上,DeepMind 可能之前已经对新的算法进行过了测试。2016 年年底,AlphaGo 化名 Master,在网络上与人类顶尖棋手下了 60 盘测试棋,取得 60 局全胜的骄人战绩。通过那次测试,谷歌旗下的 DeepMind 又发现了 AlphaGo 不少需要完善的地方,2017 年 5 月中下旬即将与柯洁进行正式人机大战的将是「AlphaGo 2.0 版本」。
Müller 认为目前 AlphaGo 的性能已经提升到了新的高度。「将蒙特卡洛树搜索和策略网络结合来提高策略网络的性能?」Müller 说道。「尽管这样需要花费大量的时间用于训练策略网络,但鉴于 DeepMind 是谷歌旗下的公司,他们可以利用到谷歌的强大硬件,甚至新一代 TPU。在去年与李世乭的对决后,DeepMind 的团队可以尝试在很多方面上进行改进。」
对于与 AlphaGo 相近的机器对手,Müller 还表示腾讯的「绝艺」已是目前世界第二强的计算机围棋程序,在未来或许会有击败 AlphaGo 的实力。
AlphaGo 未来还有多场比赛,包括史无前例的多人对战。机器之心还将继续跟踪解读,为读者第一时间带来更有价值的技术解读。
Martin Müller 将作为演讲嘉宾亮相 5 月 27 日- 28 日机器之心举办的 GMIS 2017 大会上,他将带来主题为「深度学习时代的启发式搜索(Heuristic Search in the Age of Deep Learning)」的演讲。获取人机大战和全球机器智能峰会的最新信息,请点击阅读原文或关注大会官网 gmis.jiqizhixin.com。
点击阅读原文,查看全部嘉宾阵容并报名参与机器之心 GMIS 2017 ↓↓↓











