本文列举了大数据相关的部分热门项目,盘点了该生态圈目前流行的一些开源产品和工具,并用google热度趋势图体现了它们的受关注程度。从不同的热度趋势,可以了解到每一个产品在近5年来全球受关注的走势,是越来越受重视还是渐渐淡出。 在QCon2016 北京站上,Druid开源项目的负责人,Imply联合创始人Fangjin Yang分享了题为 《Evolution of Open Source Data Infrastructure》的主题演讲,探讨了开源大数据世界的发展和方向。作为引申,我们希望在此基础上,利用Google Trends的趋势分析能力对一些热门开源工具做了一一搜索、对比和排名。(戳阅读原文,阅读演讲文章)
因为大数据令人惊讶的高速发展以及知识局限性,本文没有(也不可能)列举出这个生态圈里的所有开源类型,比如机器学习、数据挖掘等等无法一一罗列,也无意涵盖所有大数据牵涉的各个角落,比如OpenStack、Docker等相关大热门。这里推荐了一些比较流行的开源产品,希望能引起大家兴趣和关注。在内容介绍上,因为它们大都耳熟能详,也仅仅是抛砖引玉的对每一款产品做了简单的描述,这些描述基本来自官网介绍以及各类技术网站的推介。
注意:
一款基于Java编写的任务调度系统任务调度,来自LinkedIn公司,用于管理他们的Hadoop批处理工作流。Azkaban根据工作的依赖性进行排序,提供友好的Web用户界面来维护和跟踪用户的工作流程。
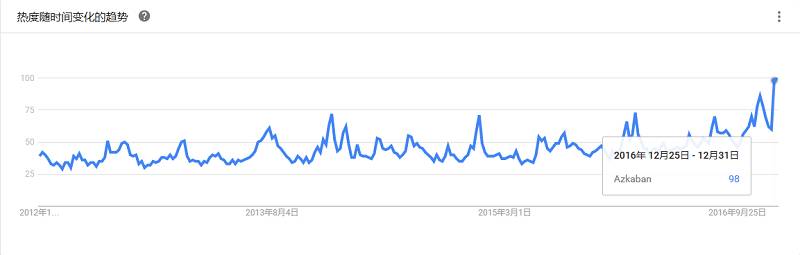
一种新的Hadoop资源管理器,它是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度,解决了旧MapReduce框架的性能瓶颈。它的基本思想是把资源管理和作业调度/监控的功能分割到单独的守护进程。
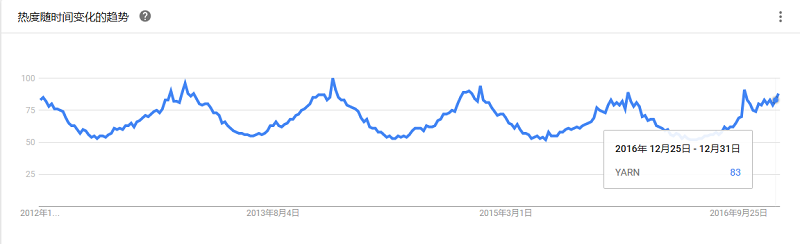
由加州大学伯克利分校的AMPLab首先开发的一款开源群集管理软件,支持Hadoop、ElasticSearch、Spark、Storm 和Kafka等架构。对数据中心而言它就像一个单一的资源池,从物理或虚拟机器中抽离了CPU,内存,存储以及其它计算资源, 很容易建立和有效运行具备容错性和弹性的分布式系统。
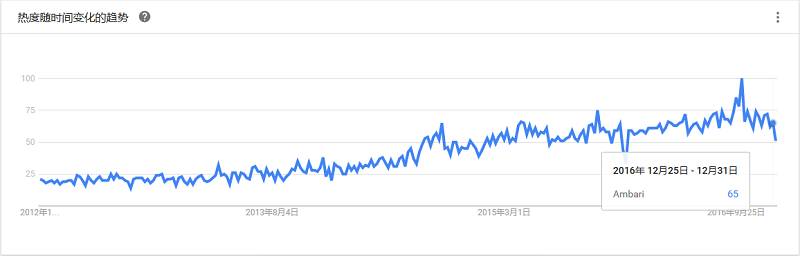
作为Hadoop生态系统的一部分,提供了基于Web的直观界面,可用于配置、管理和监控Hadoop集群。目前已支持大多数Hadoop组件,包括HDFS、MapReduce、Hive、Pig、 Hbase、Zookeper、Sqoop和Hcatalog等。
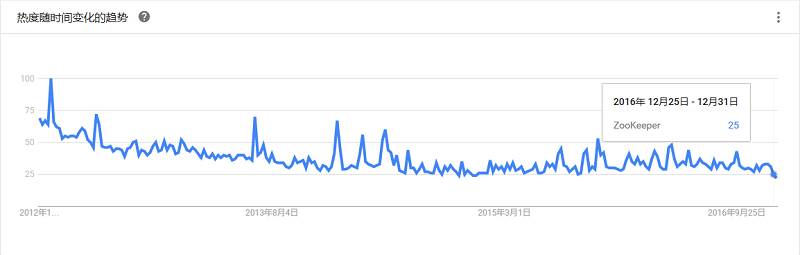
一个分布式的应用程序协调服务,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的工具,让Hadoop集群里面的节点可以彼此协调。ZooKeeper现在已经成为了 Apache的顶级项目,为分布式系统提供了高效可靠且易于使用的协同服务。
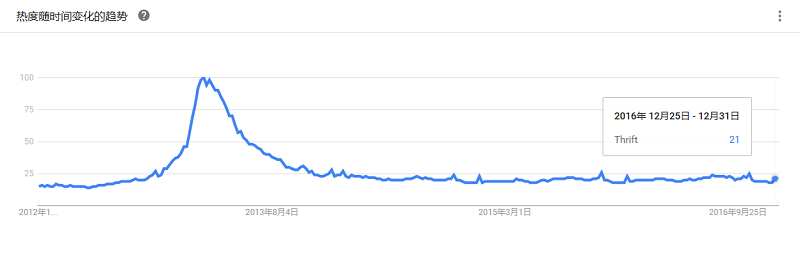
在2007年facebook提交Apache基金会将Thrift作为一个开源项目,对于当时的facebook来说创造thrift是为了解决facebook系统中各系统间大数据量的传输通信以及系统之间语言环境不同需要跨平台的特性。
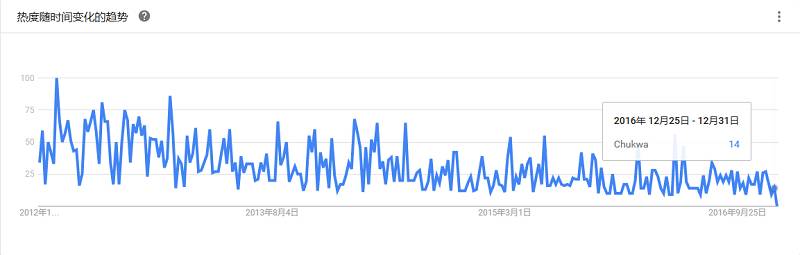
监测大型分布式系统的一个开源数据采集系统,建立在HDFS/MapReduce框架之上并继承了Hadoop的可伸缩性和可靠性,可以收集来自大型分布式系统的数据,用于监控。它还包括灵活而强大的显示工具用于监控、分析结果。
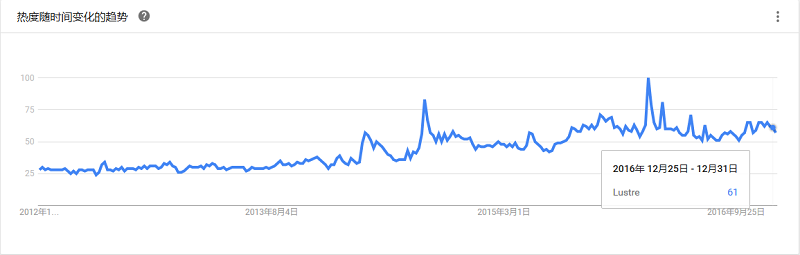
一个大规模的、安全可靠的、具备高可用性的集群文件系统,它是由SUN公司开发和维护的。该项目主要的目的就是开发下一代的集群文件系统,目前可以支持超过10000个节点,数以PB的数据存储量。
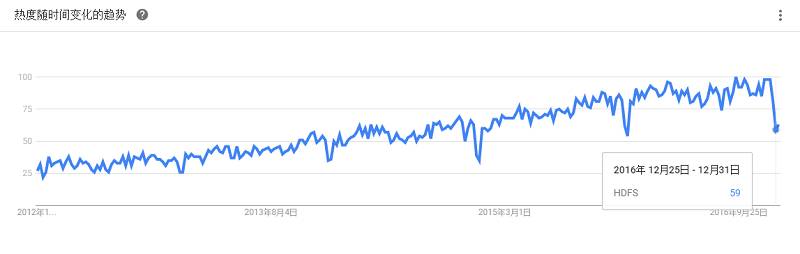
Hadoop Distributed File System,简称HDFS,是一个分布式文件系统。HDFS是一个高度容错性的系统,适合部署在廉价的机器上。HDFS能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。
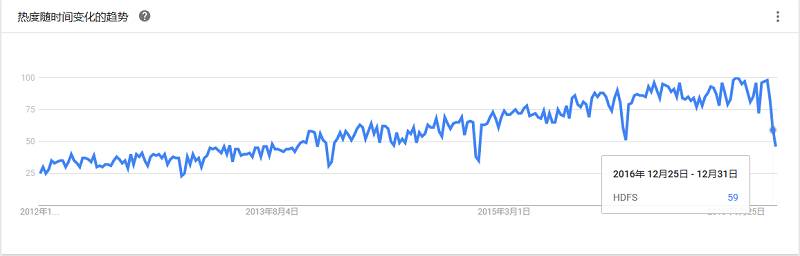
一个集群的文件系统,支持PB级的数据量。GlusterFS 通过RDMA和TCP/IP方式将分布到不同服务器上的存储空间汇集成一个大的网络化并行文件系统。
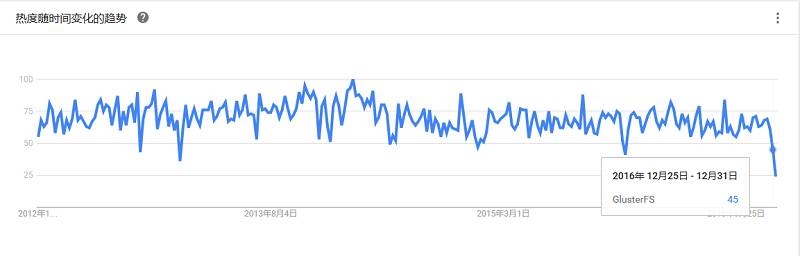
前身是Tachyon,是以内存为中心的分布式文件系统,拥有高性能和容错能力,能够为集群框架(如Spark、MapReduce)提供可靠的内存级速度的文件共享服务。
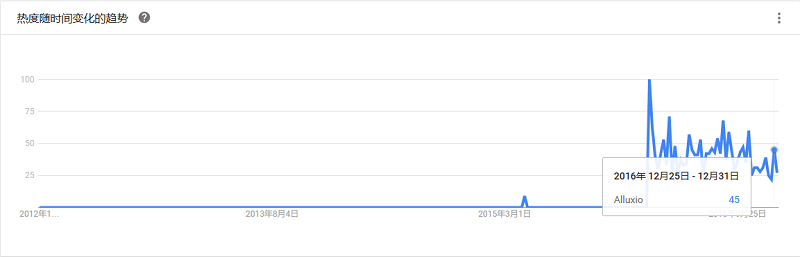
新一代开源分布式文件系统,主要目标是设计成基于POSIX的没有单点故障的分布式文件系统,提高数据的容错性并实现无缝的复制。
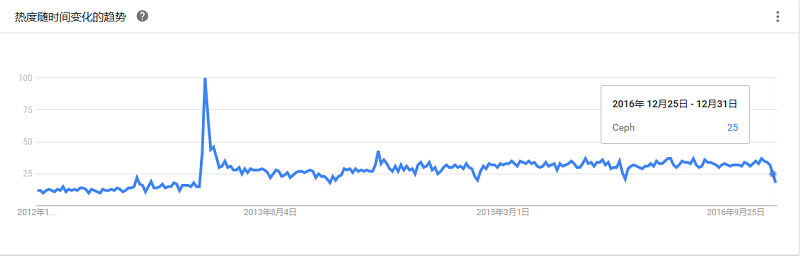
一个高性能、开源的并行文件系统,主要用于并行计算环境中的应用。PVFS特别为超大数量的客户端和服务器端所设计,它的模块化设计结构可轻松的添加新的硬件和算法支持。
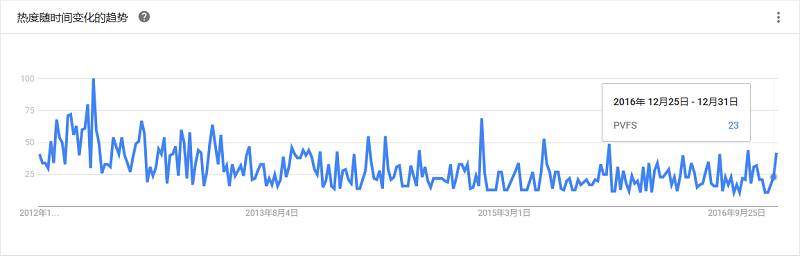
Quantcast File System (QFS) 是一个高性能、容错好、分布式的文件系统,用于开发支持 MapReduce处理或者需要顺序读写大文件的应用。
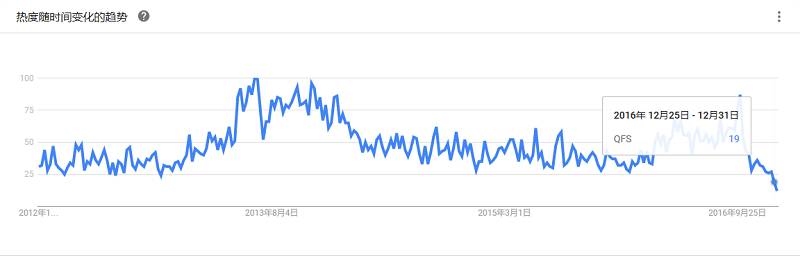
一个应用程序日志、事件的传输、处理、管理和搜索的平台。可以用它来统一对应用程序日志进行收集管理,提供了Web接口用于查询和统计。
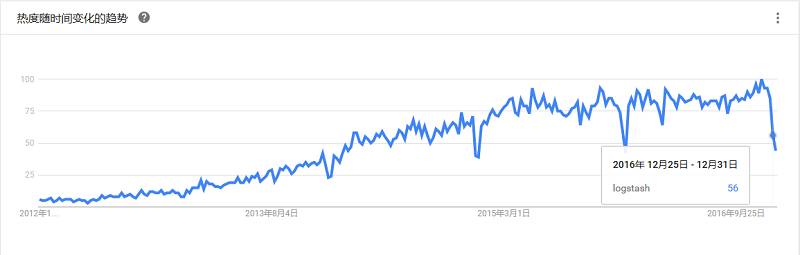
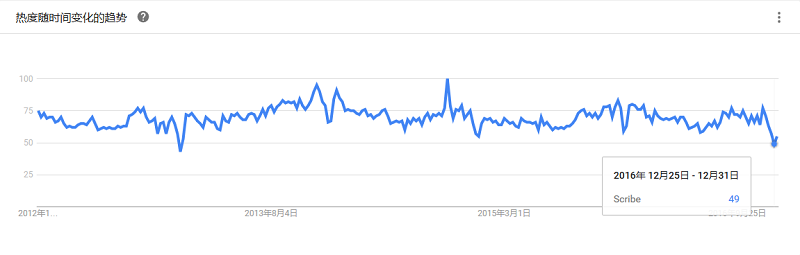
Scribe是Facebook开源的日志收集系统,它能够从各种日志源上收集日志,存储到一个中央存储系统(可以是NFS,分布式文件系统等)上,以便于进行集中统计分析处理。
Cloudera提供的一个高可用的、高可靠的、分布式的海量日志采集、聚合和传输的系统。Flume支持在日志系统中定制各类数据发送方,用于收集数据。同时,Flume支持对数据进行简单处理,并写入各种数据接受方(可定制)。
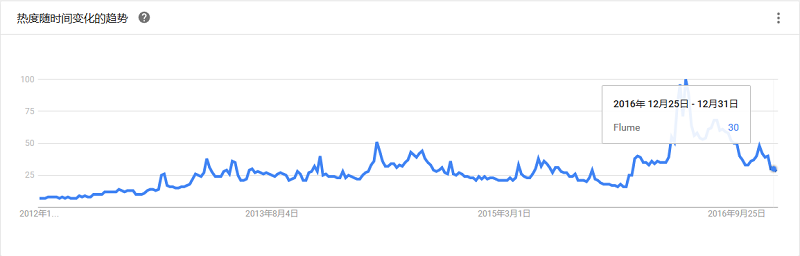
一个受欢迎的消息代理系统,通常用于应用程序之间或者程序的不同组件之间通过消息来进行集成。RabbitMQ提供可靠的应用消息发送、易于使用、支持所有主流操作系统、支持大量开发者平台。
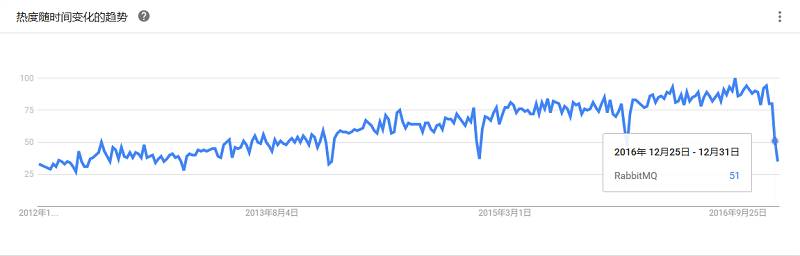
Apache出品,号称“最流行的,最强大”的开源消息集成模式服务器。ActiveMQ特点是速度快,支持多种跨语言的客户端和协议,其企业集成模式和许多先进的功能易于使用,是一个完全支持JMS1.1和J2EE 1.4规范的JMS Provider实现。
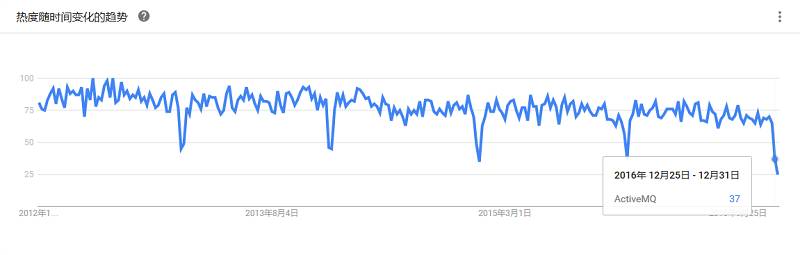
一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模网站中的所有动作流数据,目前已成为大数据系统在异步和分布式消息之间的最佳选择。
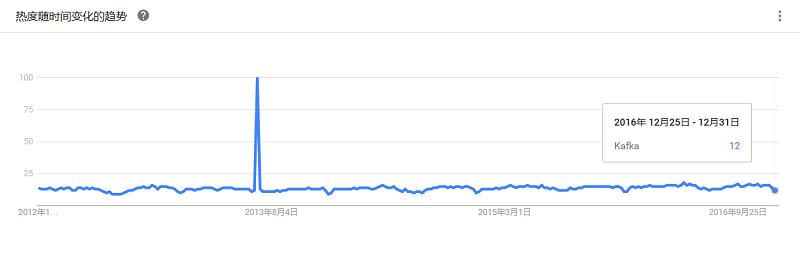
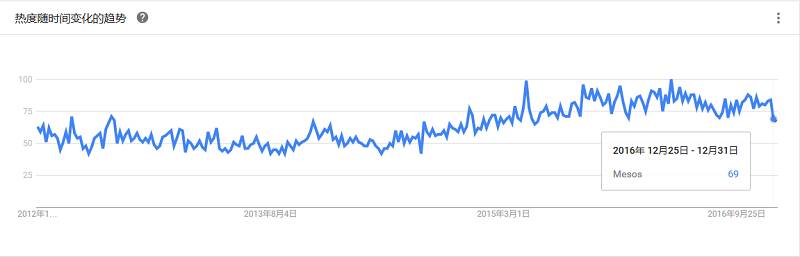
一个高速、通用大数据计算处理引擎。拥有Hadoop MapReduce所具有的优点,但不同的是Job的中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。它可以与Hadoop和Apache Mesos一起使用,也可以独立使用。
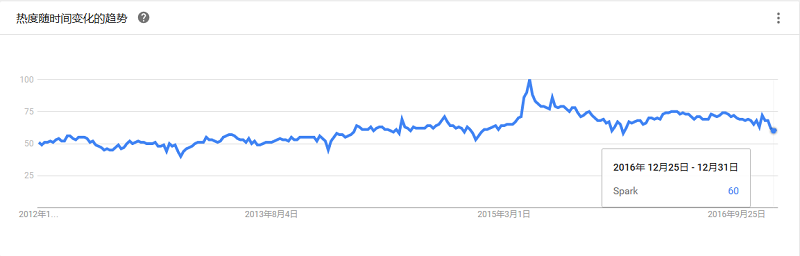
可以构建用于处理或分析流数据的自定义应用程序,来满足特定需求。Amazon Kinesis Streams 每小时可从数十万种来源中连续捕获和存储数TB数据,如网站点击流、财务交易、社交媒体源、IT日志和定位追踪事件。
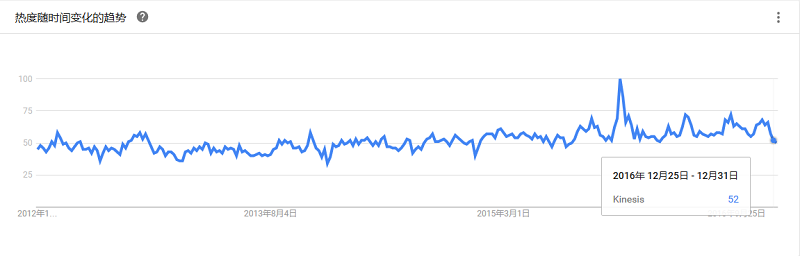
一个开源框架,适合运行在通用硬件,支持用简单程序模型分布式处理跨集群大数据集,支持从单一服务器到上千服务器的水平scale up。Apache的Hadoop项目已几乎与大数据划上了等号,它不断壮大起来,已成为一个完整的生态系统,拥有众多开源工具面向高度扩展的分布式计算。高效、可靠、可伸缩,能够为你的数据存储项目提供所需的YARN、HDFS和基础架构,并且运行主要的大数据服务和应用程序。
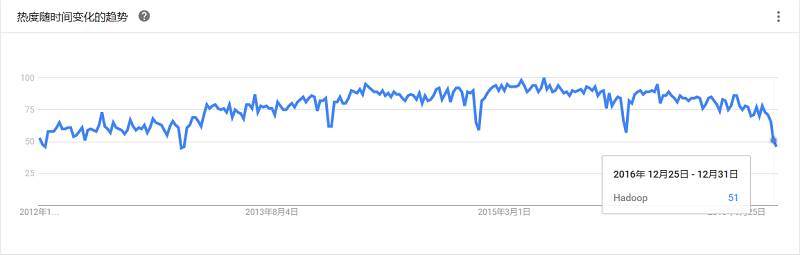
实现微批处理,目标是很方便的建立可扩展、容错的流应用,支持Java、Scala和Python,和Spark无缝集成。Spark Streaming可以读取数据HDFS,Flume,Kafka,Twitter和ZeroMQ,也可以读取自定义数据。
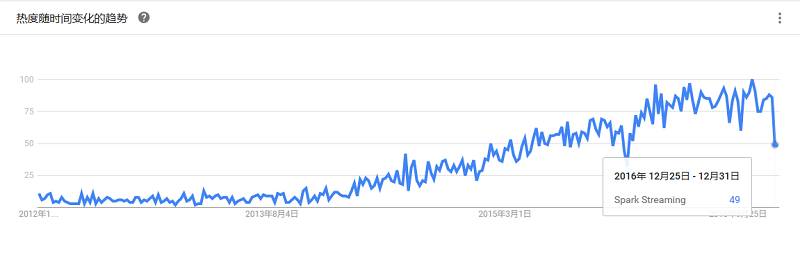
是对Storm的更高一层的抽象,除了提供一套简单易用的流数据处理API之外,它以batch(一组tuples)为单位进行处理,这样一来,可以使得一些处理更简单和高效。
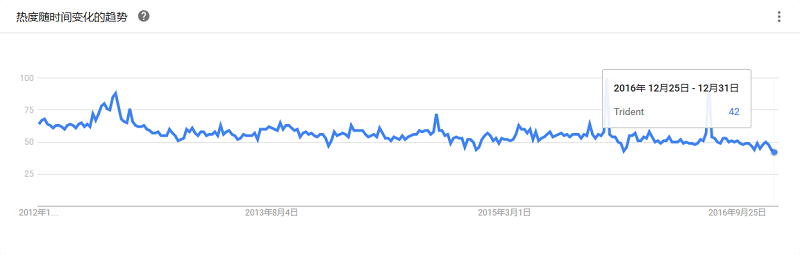
于今年跻身Apache顶级开源项目,与HDFS完全兼容。Flink提供了基于Java和Scala的API,是一个高效、分布式的通用大数据分析引擎。更主要的是,Flink支持增量迭代计算,使得系统可以快速地处理数据密集型、迭代的任务。
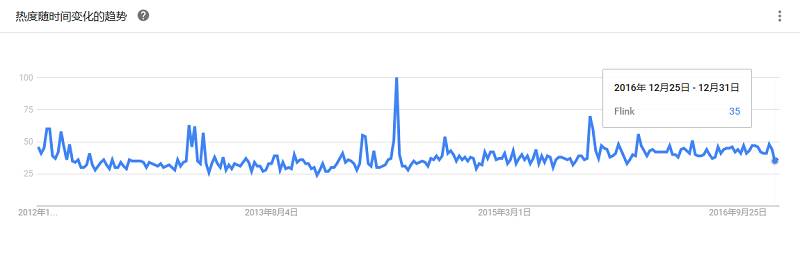
出自于LinkedIn,构建在Kafka之上的分布式流计算框架,是Apache顶级开源项目。可直接利用Kafka和Hadoop YARN提供容错、进程隔离以及安全、资源管理。
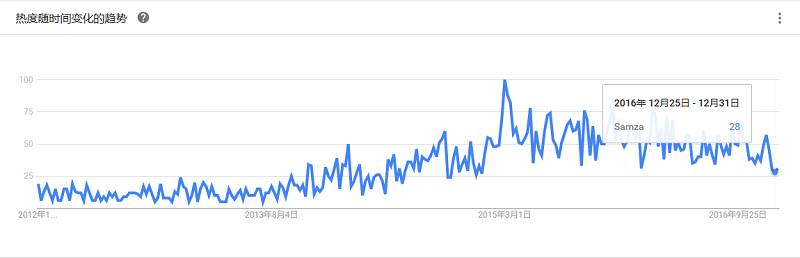
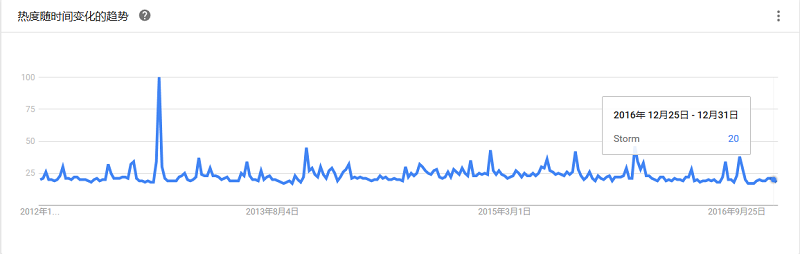
Storm是Twitter开源的一个类似于Hadoop的实时数据处理框架。编程模型简单,显著地降低了实时处理的难度,也是当下最人气的流计算框架之一。与其他计算框架相比,Storm最大的优点是毫秒级低延时。
Yahoo S4 (Simple Scalable Streaming System) 是一个分布式流计算平台,具备通用、分布式、可扩展的、容错、可插拔等特点,程序员可以很容易地开发处理连续无边界数据流(continuous unbounded streams of data)的应用。它的目标是填补复杂专有系统和面向批处理开源产品之间的空白,并提供高性能计算平台来解决并发处理系统的复杂度。
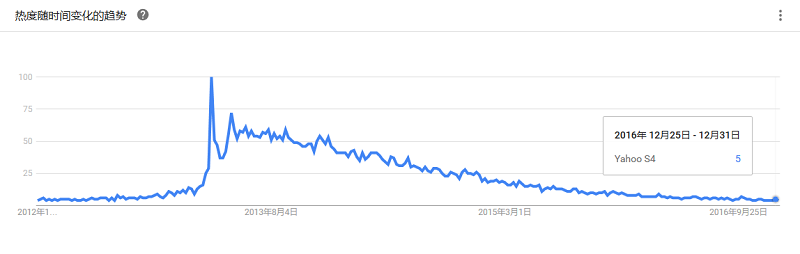
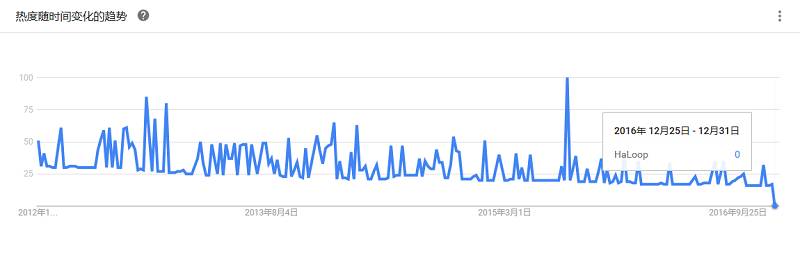
是一个Hadoop MapReduce框架的修改版本,其目标是为了高效支持 迭代,递归数据 分析任务,如PageRank,HITs,K-means,sssp等。
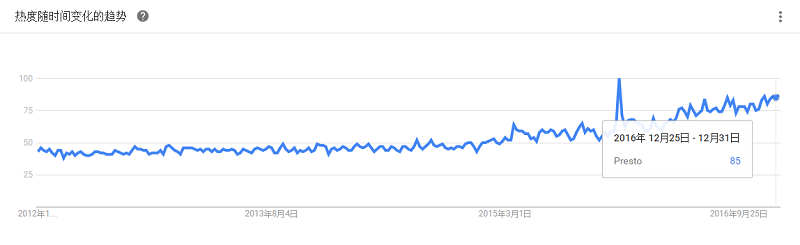
是一个开源的分布式SQL查询引擎,适用于交互式分析查询,可对250PB以上的数据进行快速地交互式分析。Presto的设计和编写是为了解决像Facebook这样规模的商业数据仓库的交互式分析和处理速度的问题。Facebook称Presto的性能比诸如Hive和MapReduce要好上10倍有多。
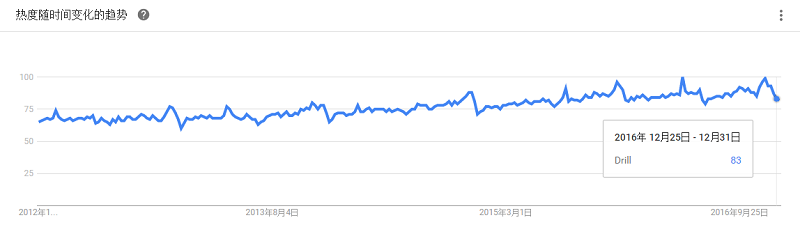
于2012年8月份由Apache推出,让用户可以使用基于SQL的查询,查询Hadoop、NoSQL数据库和云存储服务。它能够运行在上千个节点的服务器集群上,且能在几秒内处理PB级或者万亿条的数据记录。它可用于数据挖掘和即席查询,支持一系列广泛的数据库,包括HBase、MongoDB、MapR-DB、HDFS、MapR-FS、亚马逊S3、Azure Blob Storage、谷歌云存储和Swift。
是一个Java中间层,可以让开发者在Apache HBase上执行SQL查询。Phoenix完全使用Java编写,并且提供了一个客户端可嵌入的JDBC驱动。Phoenix查询引擎会将SQL查询转换为一个或多个HBase scan,并编排执行以生成标准的JDBC结果集。
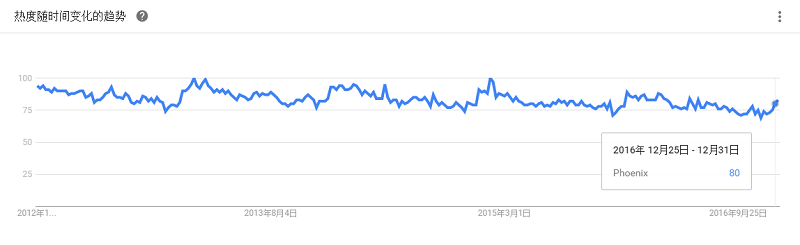
是一种编程语言,它简化了Hadoop常见的工作任务。Pig可加载数据、转换数据以及存储最终结果。Pig最大的作用就是为MapReduce框架实现了一套shell脚本 ,类似我们通常熟悉的SQL语句。
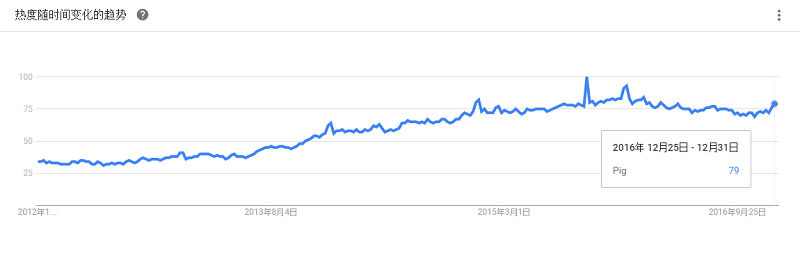
是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。 其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
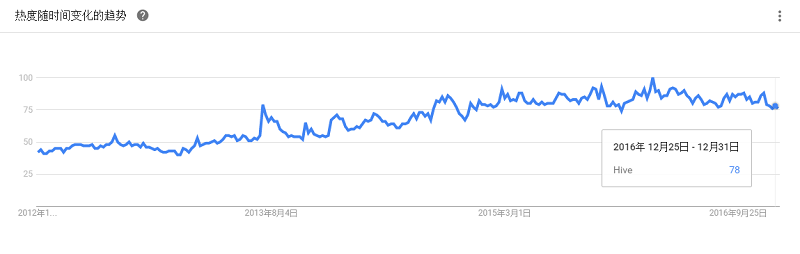
前身是Shark,SparkSQL抛弃原有Shark的代码并汲取了一些优点,如内存列存储(In-Memory Columnar Storage)、Hive兼容性等。由于摆脱了对Hive的依赖性,SparkSQL无论在数据兼容、性能优化、组件扩展方面都得到了极大的方便。
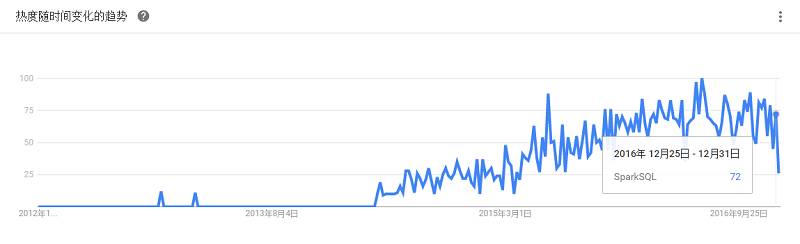
原来叫Tez,是下一代Hive,由Hortonworks主导开发,运行在YARN上的DAG计算框架。某些测试下,Stinger能提升10倍左右的性能,同时会让Hive支持更多的SQL。
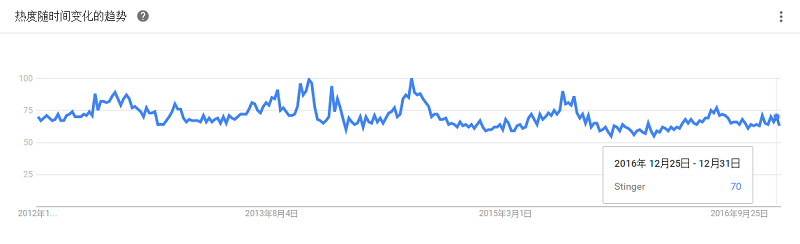
目的是在HDFS之上构建一个可靠的、支持关系型数据的分布式数据仓库系统,它的重点是提供低延迟、可扩展的ad-hoc查询和在线数据聚集,以及为更传统的ETL提供工具。
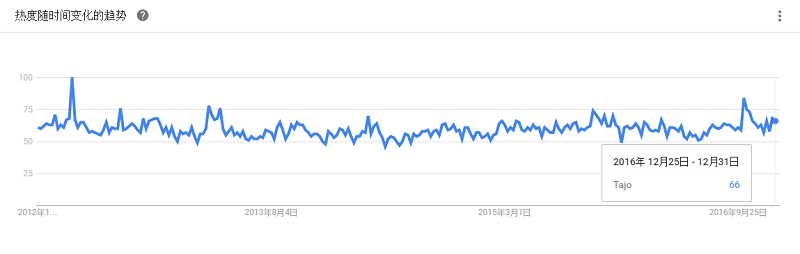
Cloudera 声称,基于SQL的Impala数据库是“面向Apache Hadoop的领先的开源分析数据库”。它可以作为一款独立产品来下载,又是Cloudera的商业大数据产品的一部分。Cloudera Impala 可以直接为存储在HDFS或HBase中的Hadoop数据提供快速、交互式的SQL查询。
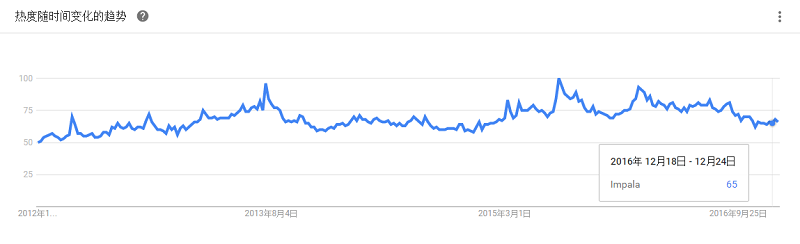
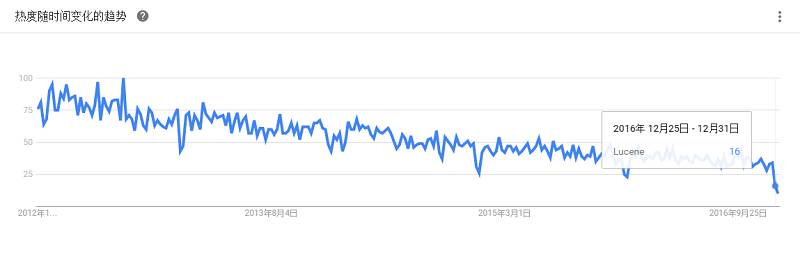
是一个基于Lucene的搜索服务器。它提供了一个分布式、支持多用户的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索、稳定、可靠、快速、安装使用方便。
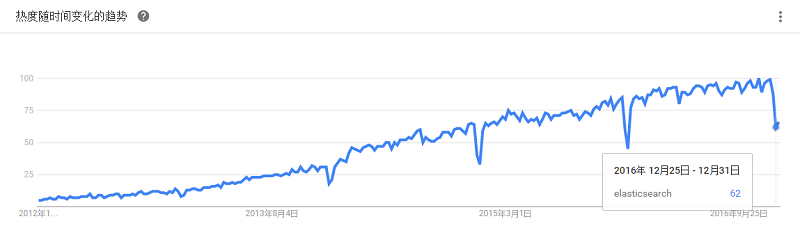
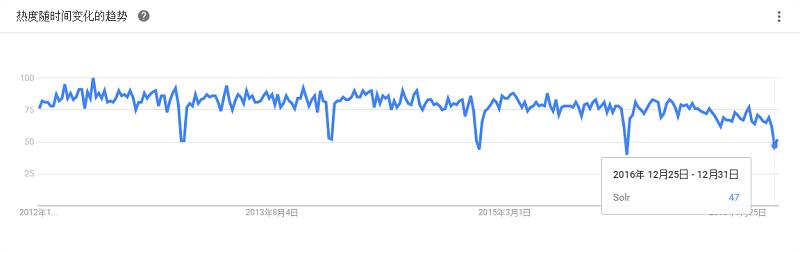
基于Apache Lucene,是一种高度可靠、高度扩展的企业搜索平台。知名用户包括eHarmony、西尔斯、StubHub、Zappos、百思买、AT&T、Instagram、Netflix、彭博社和Travelocity。
即Hive on Spark,本质上是通过Hive的HQL解析,把HQL翻译成Spark上的RDD操作,然后通过Hive的metadata获取数据库里的表信息,实际HDFS上的数据和文件,会由Shark获取并放到Spark上运算。Shark的特点就是快,完全兼容Hive,且可以在shell模式下使用rdd2sql()这样的API,把HQL得到的结果集,继续在scala环境下运算,支持自己编写简单的机器学习或简单分析处理函数,对HQL结果进一步分析计算。
基于Java的Lucene可以非常迅速地执行全文搜索。据官方网站声称,它在现代硬件上每小时能够检索超过150GB的数据,它拥有强大而高效的搜索算法。
声称其BigMemory技术是“世界上首屈一指的内存中数据管理平台”,支持简单、可扩展、实时消息,声称在190个国家拥有210万开发人员,全球1000家企业部署了其软件。
是一种高性能、整合式、分布式的内存中平台,可用于对大规模数据集执行实时计算和处理,速度比传统的基于磁盘的技术或闪存技术高出好几个数量级。该平台包括数据网格、计算网格、服务网格、流媒体、Hadoop加速、高级集群、文件系统、消息传递、事件和数据结构等功能。
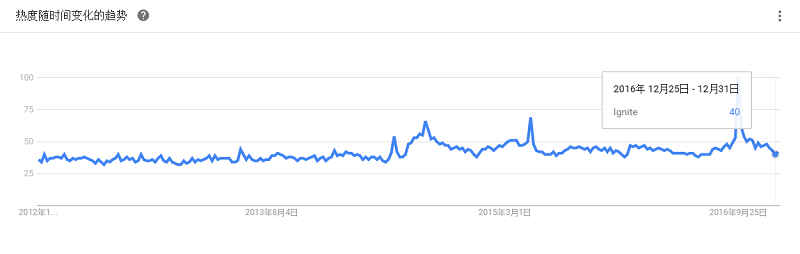
Pivotal宣布它将开放其大数据套件关键组件的源代码,其中包括GemFire内存中NoSQL数据库。它已向Apache软件基金会递交了一项提案,以便在“Geode”的名下管理GemFire数据库的核心引擎。
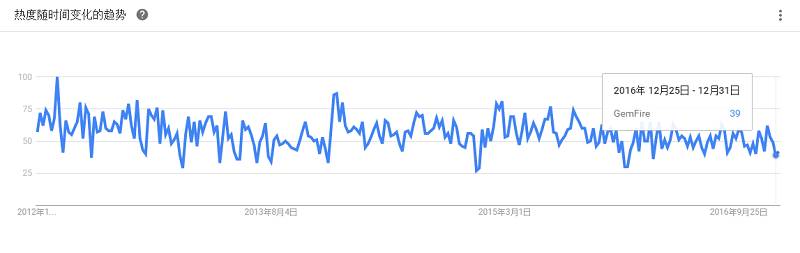
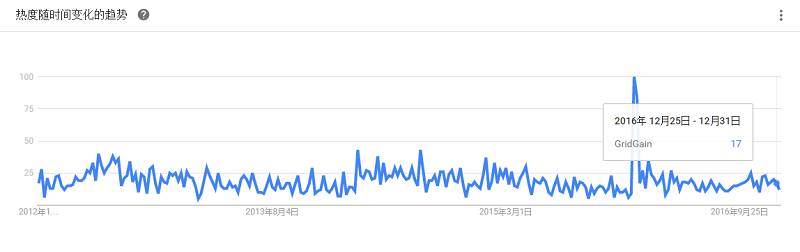
由Apache Ignite驱动的GridGrain提供内存中数据结构,用于迅速处理大数据,还提供基于同一技术的Hadoop加速器。
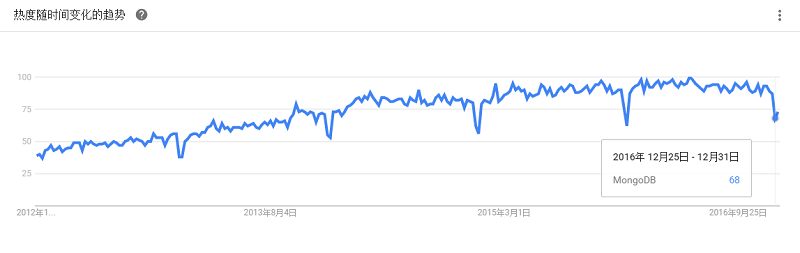
是一个基于分布式文件存储的数据库。由C++语言编写。旨在为web应用提供可扩展的高性能数据存储解决方案。介于关系数据库和非关系数据库之间的开源产品,是非关系数据库当中功能最丰富、最像关系数据库的产品。
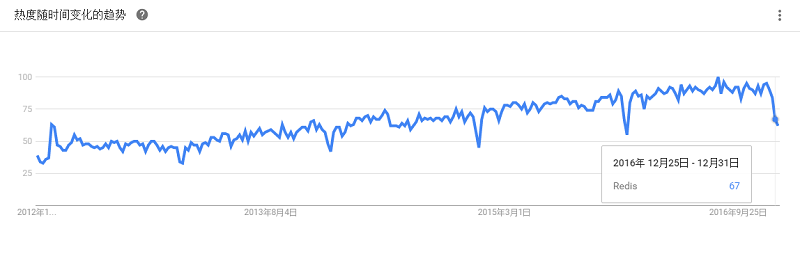
是一个高性能的key-value存储系统,和Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)和zset(有序集合)。Redis的出现,很大程度补偿了memcached这类key/value存储的不足,在部分场合可以对关系数据库起到很好的补充作用。
Hadoop分布式文件系统(HDFS)被设计成适合运行在通用硬件(commodity hardware)上的分布式文件系统。它和现有的分布式文件系统有很多共同点。HDFS是一个高度容错性的系统,适合部署在廉价的机器上。HDFS能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。
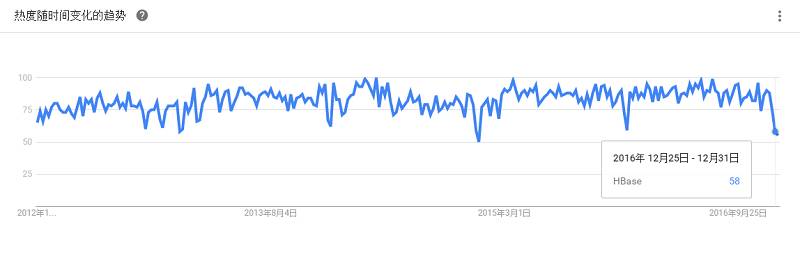
是Hadoop的数据库,一个分布式、可扩展、大数据的存储。是为有数十亿行和数百万列的超大表设计的,是一种分布式数据库,可以对大数据进行随机性的实时读取/写入访问。提供类似谷歌Bigtable的存储能力,基于Hadoop和Hadoop分布式文件系统(HDFS)而建。
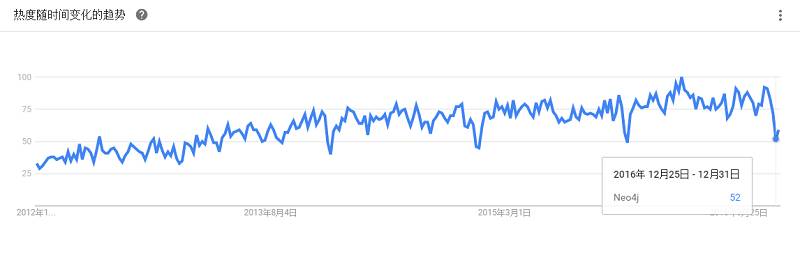
是一个高性能的,NOSQL图形数据库,它将结构化数据存储在网络上而不是表中。自称“世界上第一个和最好的图形数据库”,“速度最快、扩展性最佳的原生图形数据库”,“最大和最有活力的社区”。用户包括Telenor、Wazoku、ebay、必能宝(Pitney Bowes)、MigRaven、思乐(Schleich)和Glowbl等。
基于列存储高性能和高可用性设计的数据库方案,由于对大规模并行处理(MPP)技术的支持,提供细粒度、可伸缩性和可用性的优势。每个节点完全独立运作,完全无共享架构,降低了共享资源的系统竞争。
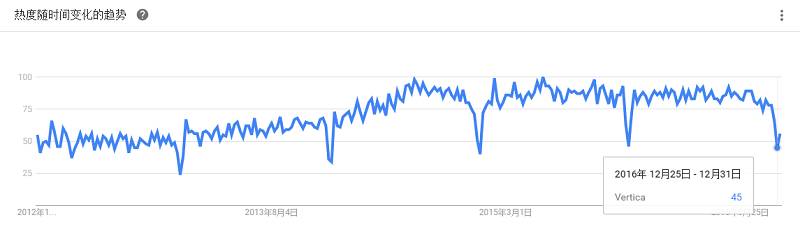
是一个混合型的非关系的数据库,类似于Google的BigTable,其主要功能比Dynamo (分布式的Key-Value存储系统)更丰富。这种NoSQL数据库最初由Facebook开发,现已被1500多家企业组织使用,包括苹果、欧洲原子核研究组织(CERN)、康卡斯特、电子港湾、GitHub、GoDaddy、Hulu、Instagram、Intuit、Netfilx、Reddit及其他机构。
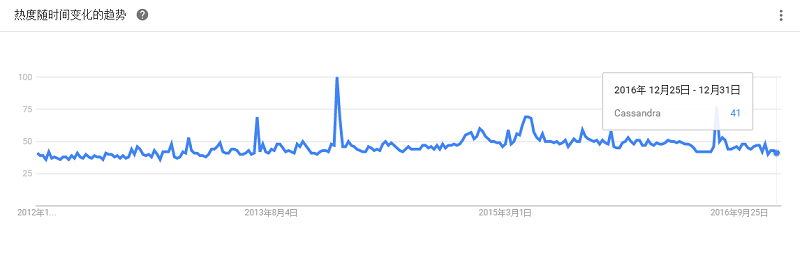
号称是“一款完全拥抱互联网的数据库”,它将数据存储在JSON文档中,这种文档可以通过Web浏览器来查询,并且用JavaScript来处理。它易于使用,在分布式上网络上具有高可用性和高扩展性。
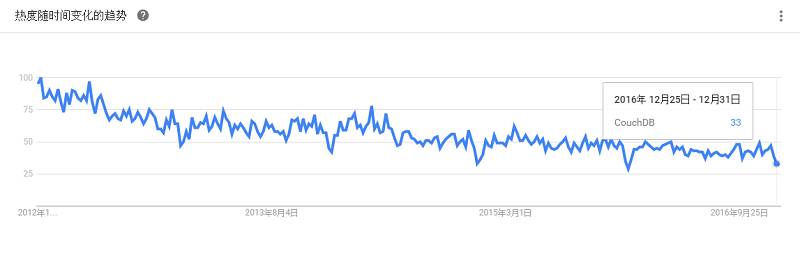
是一个经典的分布式Key-Value 存储系统,具备去中心化、高可用性、高扩展性的特点。Dynamo在Amazon中得到了成功的应用,能够跨数据中心部署于上万个结点上提供服务,它的设计思想也被后续的许多分布式系统借鉴。
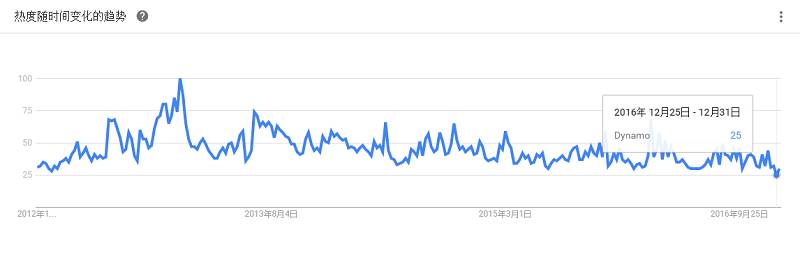
是一个用Erlang编写的高可用的NoSQL数据存储,能够减轻数据库管理工作,开发人员只需通过Web服务请求执行数据项的存储和查询,Amazon SimpleDB 将负责余下的工作。作为一项Web 服务,像Amazon的EC2和S3一样,是Amazon网络服务的一部分。
是一个开源、高性能、可伸缩的数据库,它采用与Google的Bigtable相似的模型。它与Hadoop兼容,性能超高,其用户包括电子港湾、百度、高朋、Yelp及另外许多互联网公司。
这是一个ETL工具集,它允许你管理来自不同数据库的数据,通过提供一个图形化的用户环境来描述你想做什么,而不是你想怎么做。作为Pentaho的一个重要组成部分,现在在国内项目应用上逐渐增多。
是一个开源的分布式分析引擎,提供了基于Hadoop的超大型数据集(TB/PB级别)的SQL接口以及多维度的OLAP分布式联机分析。最初由eBay开发并贡献至开源社区。它能在亚秒内查询巨大的Hive表。
是一个使用Apache 开源协议的Elasticsearch 分析和搜索仪表板,可作为Logstash和ElasticSearch日志分析的 Web 接口,对日志进行高效的搜索、可视化、分析等各种操作。
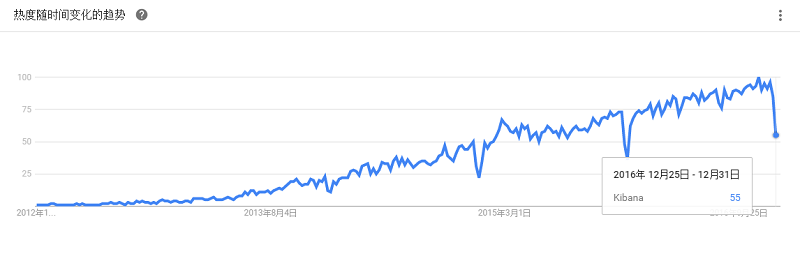
是一个用于大数据实时查询和分析的高容错、高性能、分布式的开源系统,旨在快速处理大规模的数据,并能够实现快速查询和分析。
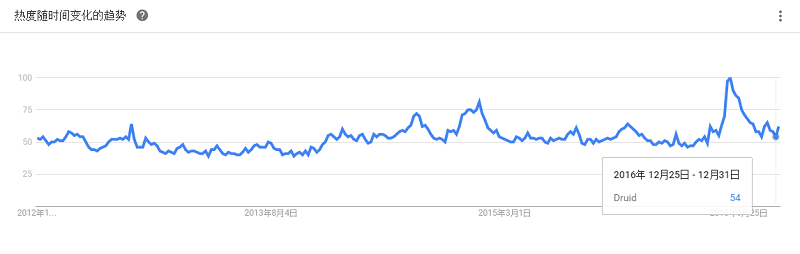
全称是“康斯坦茨信息挖掘工具”(Konstanz Information Miner),是一个开源分析和报表平台。宣称“是任何数据科学家完美的工具箱,超过1000个模块,可运行数百个实例,全面的集成工具,以及先进的算法”。
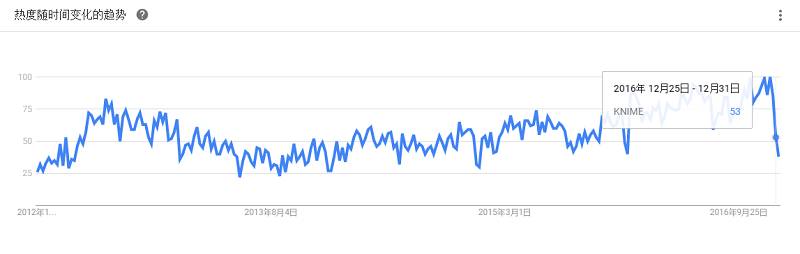
是一个提供交互数据分析且基于Web的笔记本。方便你做出可数据驱动的、可交互且可协作的精美文档,并且支持多种语言,包括 Scala(使用 Apache Spark)、Python(Apache Spark)、SparkSQL、 Hive、 Markdown、Shell等。
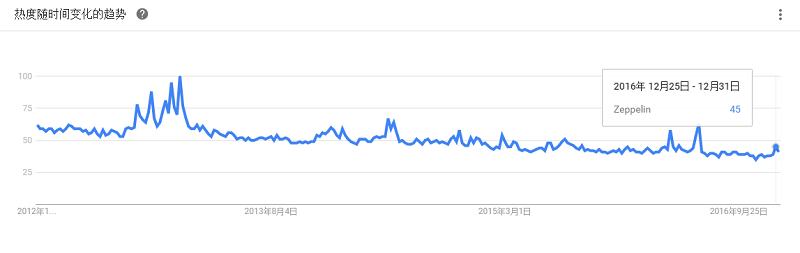
是第一家针对的数据集成工具市场的ETL(数据的提取Extract、传输Transform、载入Load)开源软件供应商。Talend的下载量已超过200万人次,其开源软件提供了数据整合功能。其用户包括美国国际集团(AIG)、康卡斯特、电子港湾、通用电气、三星、Ticketmaster和韦里逊等企业组织。
是机器数据的引擎。使用 Splunk 可收集、索引和利用所有应用程序、服务器和设备(物理、虚拟和云中)生成的快速移动型计算机数据,从一个位置搜索并分析所有实时和历史数据。
是世界上最流行的开源商务智能软件,以工作流为核心的、强调面向解决方案而非工具组件的、基于java平台的商业智能(Business Intelligence)套件。包括一个web server平台和几个工具软件:报表、分析、图表、数据集成、数据挖掘等,可以说包括了商务智能的方方面面。
提供了灵活、可嵌入的商业智能工具,用户包括众多企业组织:高朋、冠群科技、美国农业部、爱立信、时代华纳有线电视、奥林匹克钢铁、内斯拉斯加大学和通用动力公司。
Spago被市场分析师们称为“开源领袖”,它提供商业智能、中间件和质量保证软件,另外还提供相应的Java EE应用程序开发框架。
归Altamira科技公司(以国家安全技术而闻名)所有,这是一种开源大数据整合、分析和可视化平台。
是Cascading的高级扩展,为Hadoop提供了一个ANSI SQL接口极大地简化了应用程序的开发和集成。Lingual实现了连接现有的商业智能(BI)工具,优化了计算成本,加快了基于Hadoop的应用开发速度。
基于Java提供了统一的数据进程管道开发,并且能够很好地支持Spark和Flink。提供很多在线框架,开发者无需学太多框架。
是一个基于Hadoop建立的API,用来创建复杂和容错数据处理工作流。它抽象了集群拓扑结构和配置,使得不用考虑背后的MapReduce,就能快速开发复杂的分布式应用。
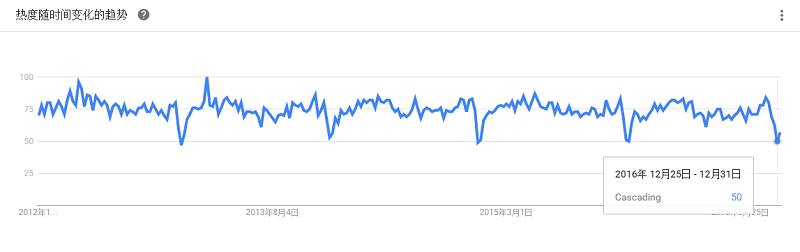
作为Hadoop之外的一种选择,是一个利用集群服务器进行大数据分析的系统,HPCC在LexisNexis内部使用多年,是一个成熟可靠的系统,包含一系列的工具、一个称为ECL的高级编程语言、以及相关的数据仓库,扩展性超强。
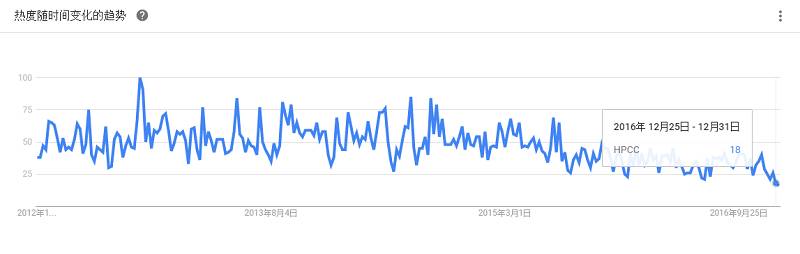
结合了面向Hive的多种机器学习算法,它包括了很多扩展性很好的算法,可用于数据分类、递归、推荐、k最近邻、异常检测和特征哈希等方面的分析应用。
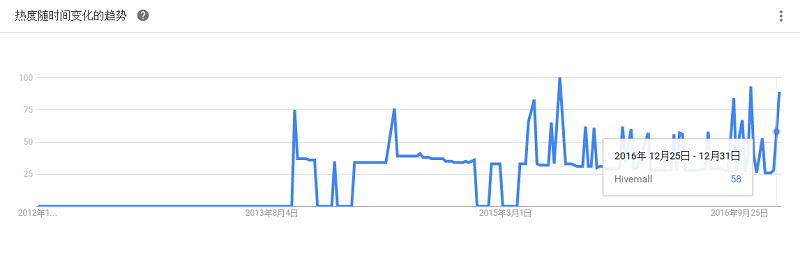
具有丰富数据挖掘分析和算法功能,常用于解决各种的商业关键问题,解决方案覆盖了各个领域,包括汽车、银行、保险、生命科学、制造业、石油和天然气、零售业及快消行业、通讯业、以及公用事业等各个行业。
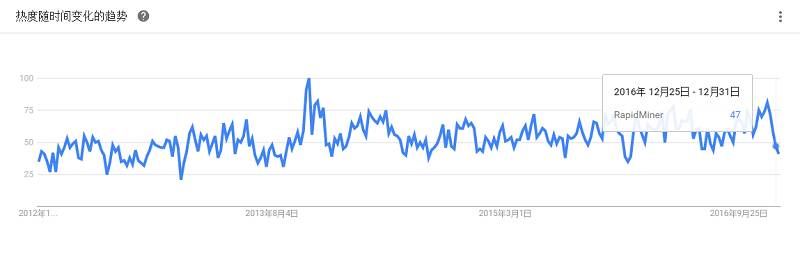
目的是“为快速创建可扩展、高性能的机器学习应用程序而打造一个环境”,主要特点是为可伸缩的算法提供可扩展环境、面向Scala/Spark/H2O/Flink的新颖算法、Samsara(类似R的矢量数学环境),它还包括了用于在MapReduce上进行数据挖掘的众多算法。
本文系「大数据杂谈」原创文章,已经授权InfoQ公众号转发传播。ID:「BigdataTina2016」
今日荐文
点击下方图片即可阅读

Apache Beam的前世今生:谷歌已经不再使用MapReduce了










