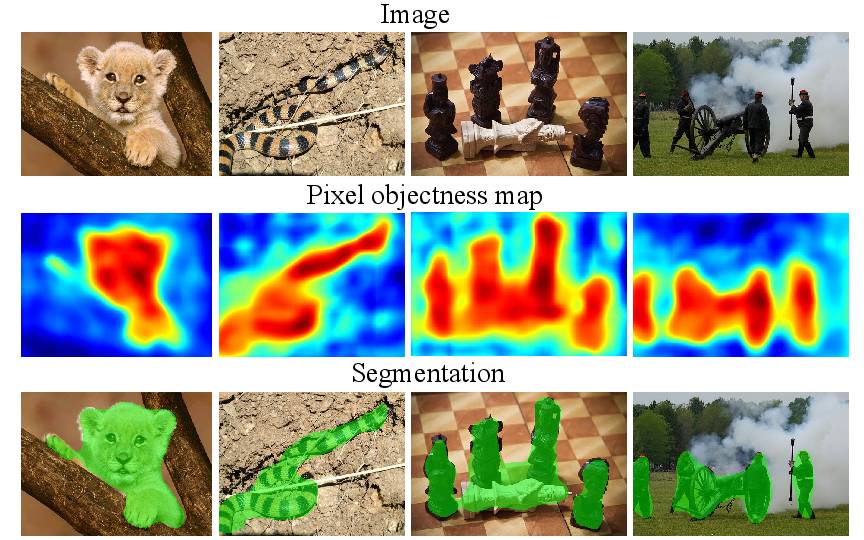
论文《Pixel Objectness》提出了一个用于前景对象分割的端到端学习框架。给定一个单一的新颖图像,我们的方法为所有“像对象”区域 -
即使对于在训练期间从未见过的对象类别,产生像素级掩码。我们将任务制定为使用深完全卷积网络实现的将前景/背景标签分配给每个像素的结构化预测问题。我们的想法的关键是采用训练与图像级对象类别示例,以及采用相对较少的注释的边界级图像合。我们的方法大大改善了ImageNet和MIT数据集上的前景分割的最先进的水平
-
在某些情况下,有19%的绝对改进。此外,在超过100万的图像,我们显示它很好地归纳到用于训练的前景地图中看不见的对象类别。最后,我们演示了我们的方法如何有利于图像检索和图像重定向,这两种方法在给定的高质量前景图的领域将会有好的效果。
摘要:
We propose an end-to-end learning framework for foreground object
segmentation.
Given a single novel image, our approach produces a pixel-level mask
for all "object-like" regions---even for object categories never seen
during training.
We formulate the task as a structured prediction problem of assigning a
foreground/background label to each pixel, implemented using a deep
fully convolutional network.
Key to our idea is training with a mix of image-level object category
examples together with relatively few images with boundary-level
annotations.
Our method substantially improves the state-of-the-art on foreground
segmentation on the ImageNet and MIT Object Discovery datasets---with
19% absolute improvements in some cases.
Furthermore, on over 1 million images, we show it generalizes well to
segment object categories unseen in the foreground maps used for
training.
Finally, we demonstrate how our approach benefits image retrieval and
image retargeting, both of which flourish when given our high-quality
foreground maps.
项目主页:
http://vision.cs.utexas.edu/projects/pixelobjectness/
原文链接:
http://weibo.com/5501429448/EuSzNw84L?from=page_1005055501429448_profile&wvr=6&mod=weibotime&type=comment#_rnd1486715763899



