(点击
上方蓝字
,快速关注我们)
来源:voidking
segmentfault.com/a/1190000008241040
如有好文章投稿,请点击 → 这里了解详情
前言
本文整理自《Python开发简单爬虫》,将会记录爬取百度百科“python”词条相关页面的整个过程。
抓取策略
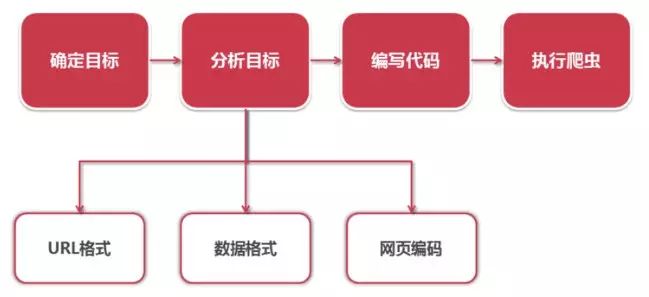
-
确定目标:确定抓取哪个网站的哪些页面的哪部分数据。本实例抓取百度百科python词条页面以及python相关词条页面的标题和简介。
-
分析目标:分析要抓取的url的格式,限定抓取范围。分析要抓取的数据的格式,本实例中就要分析标题和简介这两个数据所在的标签的格式。分析要抓取的页面编码的格式,在网页解析器部分,要指定网页编码,然后才能进行正确的解析。
-
编写代码:在网页解析器部分,要使用到分析目标得到的结果。
-
执行爬虫:进行数据抓取。
分析目标
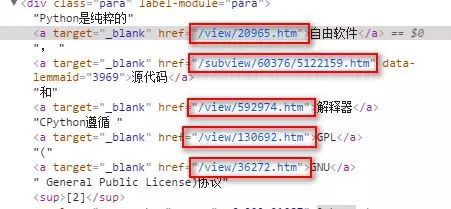
1、url格式
进入百度百科python词条页面,页面中相关词条的链接比较统一,大都是/view/xxx.htm。
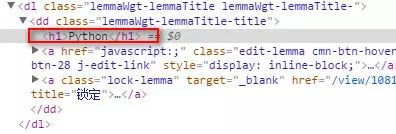
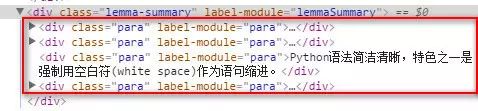
2、数据格式
标题位于类lemmaWgt-lemmaTitle-title下的h1子标签,简介位于类lemma-summary下。
3、编码格式
查看页面编码格式,为utf-8。

经过以上分析,得到结果如下:

代码编写
项目结构
-
在sublime下,新建文件夹baike-spider,作为项目根目录。
-
新建spider_main.py,作为爬虫总调度程序。
-
新建url_manger.py,作为url管理器。
-
新建html_downloader.py,作为html下载器。
-
新建html_parser.py,作为html解析器。
-
新建html_outputer.py,作为写出数据的工具。
最终项目结构如下图:
spider_main.py
# coding:utf-8
import
url_manager
,
html_downloader
,
html_parser
,
html_outputer
class
SpiderMain
(
object
)
:
def
__init__
(
self
)
:
self
.
urls
=
url_manager
.
UrlManager
()
self
.
downloader
=
html_downloader
.
HtmlDownloader
()
self
.
parser
=
html_parser
.
HtmlParser
()
self
.
outputer
=
html_outputer
.
HtmlOutputer
()
def
craw
(
self
,
root_url
)
:
count
=
1
self
.
urls
.
add_new_url
(
root_url
)
while
self
.
urls
.
has_new_url
()
:
try
:
new_url
=
self
.
urls
.
get_new_url
()
print
(
'craw %d : %s'
%
(
count
,
new_url
))
html_cont
=
self
.
downloader
.
download
(
new_url
)
new_urls
,
new_data
=
self
.
parser
.
parse
(
new_url
,
html_cont
)
self
.
urls
.
add_new_urls
(
new_urls
)
self
.
outputer
.
collect_data
(
new_data
)
if
count
==
10
:
break
count
=
count
+
1
except
:
print
(
'craw failed'
)
self
.
outputer
.
output_html
()
if
__name__
==
'__main__'
:
root_url
=
'http://baike.baidu.com/view/21087.htm'
obj_spider
=
SpiderMain
()
obj_spider
.
craw
(
root_url
)
url_manger.py
# coding:utf-8
class
UrlManager
(
object
)
:
def
__init__
(
self
)
:
self
.
new_urls
=
set
()
self
.
old_urls
=
set
()
def
add_new_url
(
self
,
url
)
:
if
url
is
None
:
return
if
url
not
in
self
.
new_urls
and
url
not
in
self
.
old_urls
:
self
.
new_urls
.
add
(
url
)
def
add_new_urls
(
self
,
urls
)
:
if
urls
is
None
or
len
(
urls
)
==
0
:
return
for
url
in
urls
:
self
.
add_new_url
(
url
)
def
has_new_url
(
self
)
:
return
len
(
self
.
new_urls
)
!=
0
def
get_new_url
(
self
)
:
new_url
=
self
.
new_urls
.
pop
()
self
.
old_urls
.
add
(
new_url
)
return
new_url
html_downloader.py
# coding:utf-8
import
urllib
.
request
class
HtmlDownloader
(
object
)
:
def
download
(
self
,
url
)
:
if
url
is
None
:
return
None
response
=
urllib
.
request
.
urlopen
(
url
)
if
response
.
getcode
()
!=
200
:
return
None
return
response
.
read
()
html_parser.py
# coding:utf-8
from
bs4
import
BeautifulSoup
import
re
from
urllib
.
parse
import
urljoin
class
HtmlParser
(
object
)
:
def
_get_new_urls
(
self
,
page_url
,
soup
)
:
new_urls
=
set
()
# /view/123.htm
links
=
soup
.
find_all
(
'a'
,
href
=
re
.
compile
(
r
'/view/\d+\.htm'
))
for
link
in
links
:
new_url
=
link
[
'href'
]
new_full_url
=
urljoin
(
page_url
,
new_url
)
# print(new_full_url)
new_urls
.
add
(
new_full_url
)
#print(new_urls)
return
new_urls
def
_get_new_data
(
self
,
page_url
,
soup
)
:
res_data
=
{}
# url
res_data
[
'url'
]
=
page_url
#
Python
title_node
=
soup
.
find
(
'dd'
,
class_
=
'lemmaWgt-lemmaTitle-title'
).
find
(
'h1'
)
res_data
[
'title'
]
=
title_node
.
get_text
()
#
summary_node
=
soup
.
find
(
'div'
,
class_
=
'lemma-summary'
)
res_data
[
'summary'
]
=
summary_node
.
get_text
()
# print(res_data)
return
res_data
def
parse
(
self
,
page_url
,
html_cont
)
:
if
page_url
is
None
or
html_cont
is
None
:
return
soup
=
BeautifulSoup
(
html_cont
,
'html.parser'
)
# print(soup.prettify())
new_urls
=
self
.
_get_new_urls
(
page_url
,










