编者按:本书节选自图书《深度学习轻松学》第十章部分内容,书中以轻松直白的语言,生动详细地介绍了深层模型相关的基础知识,并深入剖析了算法的原理与本质。同时还配有大量案例与源码,帮助读者切实体会深度学习的核心思想和精妙之处。
又双叒叕赠书啦!请关注文末活动。
本章将为读者介绍基于深度学习的生成模型。前面几章主要介绍了机器学习中的判别式模型,这种模型的形式主要是根据原始图像推测图像具备的一些性质,例如根据数字图像推测数字的名称,根据自然场景图像推测物体的边界;而生成模型恰恰相反,通常给出的输入是图像具备的性质,而输出是性质对应的图像。这种生成模型相当于构建了图像的分布,因此利用这类模型,我们可以完成图像自动生成(采样)、图像信息补全等工作。
在深度学习之前已经有很多生成模型,但苦于生成模型难以描述难以建模,科研人员遇到了很多挑战,而深度学习的出现帮助他们解决了不少问题。本章介绍基于深度学习思想的生成模型——VAE和GAN,以及GAN的变种模型。
本节将为读者介绍基于变分思想的深度学习的生成模型——Variational autoencoder,简称VAE。
生成式模型
前面的章节里读者已经看过很多判别式模型。这些模型大多有下面的规律:已知观察变量X,和隐含变量z,判别式模型对p(z|X)进行建模,它根据输入的观察变量x得到隐含变量z出现的可能性。生成式模型则是将两者的顺序反过来,它要对p(X|z)进行建模,输入是隐含变量,输出是观察变量的概率。
可以想象,不同的模型结构自然有不同的用途。判别模型在判别工作上更适合,生成模型在分布估计等问题上更有优势。如果想用生成式模型去解决判别问题,就需要利用贝叶斯公式把这个问题转换成适合自己处理的样子:
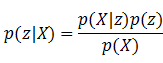
对于一些简单的问题,上面的公式还是比较容易解出的,但对于一些复杂的问题,找出从隐含变量到观察变量之间的关系是一件很困难的事情,生成式模型的建模过程会非常困难,所以对于判别类问题,判别式模型一般更适合。
但对于“随机生成满足某些隐含变量特点的数据”这样的问题来说,判别式模型就会显得力不从心。如果用判别式模型生成数据,就要通过类似于下面这种方式的方法进行。
第一步,利用简单随机一个X。
第二步,用判别式模型计算p(z|X)概率,如果概率满足,则找到了这个观察数据,如果不满足,返回第一步。
这样用判别式模型生成数据的效率可能会十分低下。而生成式模型解决这个问题就十分简单,首先确定好z的取值,然后根据p(X|z)的分布进行随机采样就行了。
了解了两种模型的不同,下面就来看看生成式模型的建模方法。
Variational Lower bound
虽然生成模型和判别模型的形式不同,但两者建模的方法总体来说相近,生成模型一般也通过最大化后验概率的形式进行建模优化。也就是利用贝叶斯公式:
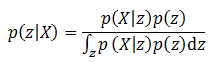
这个公式在复杂的模型和大规模数据面前极难求解。为了解决这个问题,这里将继续采用变分的方法用一个变分函数q(z)代替p(z|X)。第9章在介绍Dense CRF时已经详细介绍了变分推导的过程,而这一次的推导并不需要做完整的变分推导,只需要利用变分方法的下界将问题进行转换即可。
既然希望用q(z)这个新函数代替后验概率p(z|X),那么两个概率分布需要尽可能地相近,这里依然选择KL散度衡量两者的相近程度。根据KL公式就有:
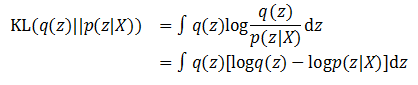
根据贝叶斯公式进行变换,就得到了:
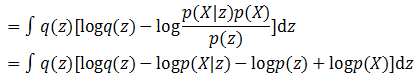
由于积分的目标是z,这里再将和z无关的项目从积分符号中拿出来,就得到了:
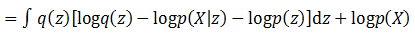
将等式左右项目交换,就得到了下面的公式:
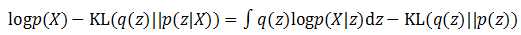
虽然这个公式还是很复杂,因为KL散度的性质,这个公式中还是令人看到了一丝曙光。
首先看等号左边,虽然p(X)的概率分布不容易求出,但在训练过程中当X已经给定,p(X)已经是个固定值不需要考虑。如果训练的目标是希望KL(q(z)||p(z|X))尽可能小,就相当于让等号右边的那部分尽可能变大。等号右边的第一项实际上是基于q(z)概率的对数似然期望,第二项又是一个负的KL散度,所以我们可以认为,为了找到一个好的q(z),使得它和p(z|X)尽可能相近,实现最终的优化目标,优化的目标将变为:
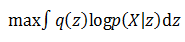
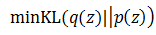
右边两个项目的优化难度相对变小了一些,下面就来看看如何基于它们做进一步的计算。
Reparameterization Trick
为了更方便地求解上面的公式,这里需要做一点小小的trick工作。上面提到了q(z)这个变分函数,为了近似后验概率,它实际上代表了给定某个X的情况下z的分布情况,如果将它的概率形式写完整,那么它应该是q(z|X)。这个结构实际上对后面的运算产生了一些障碍,那么能不能想办法把X抽离出来呢?
例如,有一个随机变量a服从均值为1,方差为1的高斯分布,那么根据高斯分布的性质,随机变量b=a-1将服从均值为0,方差为1的高斯分布,换句话说,我们可以用一个均值为0,方差为1的随机变量加上一个常量1来表示现在的随机变量a。这样一个随机变量就被分成了两部分——一部分是确定的,一部分是随机的。
实际上,q(z|X)也可以采用上面的方法完成。这个条件概率可以拆分成两部分,一部分是一个观察变量gϕ(X),它代表了条件概率的确定部分,它的值和一个随机变量的期望值类似;另一部分是随机变量ε,它负责随机的部分,基于这样的表示方法,条件概率中的随机性将主要来自这里。
这样做有什么好处呢?经过变换,如果z条件概率值完全取决于ε的概率。也就是说如果z(i)=gϕ(X+ε(i)),那么q(z(i))=p(ε(i)),那么上面关于变分推导的公式就变成了下面的公式:
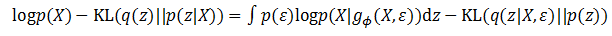
这就是替换的一小步,求解的一大步!这个公式已经很接近问题最终的答案了,既然ϵ完全决定了z的分布,那么假设一个ϵ服从某个分布,这个变分函数的建模就完成了。如果ϵ服从某个分布,那么z的条件概率是不是也服从这个分布呢?不一定。z的条件分布会根据训练数据进行学习,由于经过了函数gϕ()的计算,z的分布有可能产生了很大的变化。而这个函数,就可以用深度学习模型表示。前面的章节读者已经了解到深层模型的强大威力,那么从一个简单常见的随机变量映射到复杂分布的变量,对深层模型来说是一件很平常的事情,它可以做得很好。
于是这个假设ϵ服从多维且各维度独立高斯分布。同时,z的先验和后验也被假设成一个多维且各维度独立的高斯分布。下面就来看看两个优化目标的最终形式。
Encoder和Decoder的计算公式
回顾一下10.1.2的两个优化目标,下面就来想办法求解这两个目标。首先来看看第二个优化目标,也就是让公式右边第二项KL(q(z)||p(z))最小化。刚才z的先验被假设成一个多维且各维度独立的高斯分布,这里可以给出一个更强的假设,那就是这个高斯分布各维度的均值为0,协方差为单位矩阵,那么前面提到的KL散度公式就从:
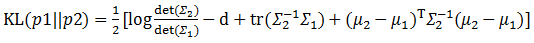
瞬间简化成为:
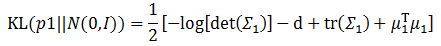
前面提到了一个用深层网络实现的模型gϕ(X,ϵ),它的输入是一批图像,输出是z,因此这里需要它通过X生成z,并将这一个批次的数据汇总计算得到它们的均值和方差。这样利用上面的公式,KL散度最小化的模型就建立好了。
实际计算过程中不需要将协方差表示成矩阵的形状,只需要一个向量σ1来表示协方差矩阵的主对角线即可,公式将被进一步简化:
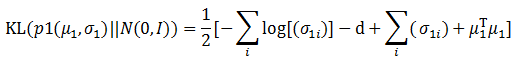
由于函数gϕ()实现了从观测数据到隐含数据的转变,因此这个模型被称为Encoder模型。
接下来是第一个优化目标,也就是让公式左边第一项的似然期望最大化。这一部分的内容相对简单,由于前面的Encoder模型已经计算出了一批观察变量X对应的隐含变量z,那么这里就可以再建立一个深层模型,根据似然进行建模,输入为隐含变量z,输出为观察变量X。如果输出的图像和前面生成的图像相近,那么就可以认为似然得到了最大化。这个模型被称为Decoder,也就是本章的主题——生成模型。
到这里VAE的核心计算推导就结束了。由于模型推导的过程有些复杂,下面就来看看VAE实现的代码,同时来看看VAE模型生成的图像是什么样子。
实现
本节要介绍VAE模型的一个比较不错的实现——GitHub - cdoersch/vae_tutorial: Caffe code to accompany my Tutorial on Variational Autoencoders,这个工程还配有一个介绍VAE的文章[2],感兴趣的读者可以阅读,读后会有更多启发。这个实现使用的目标数据集依然是MNIST,模型的架构如图10-1所示。为了更好地了解模型的架构,这里将模型中的一些细节隐去,只留下核心的数据流动和Loss计算部分。
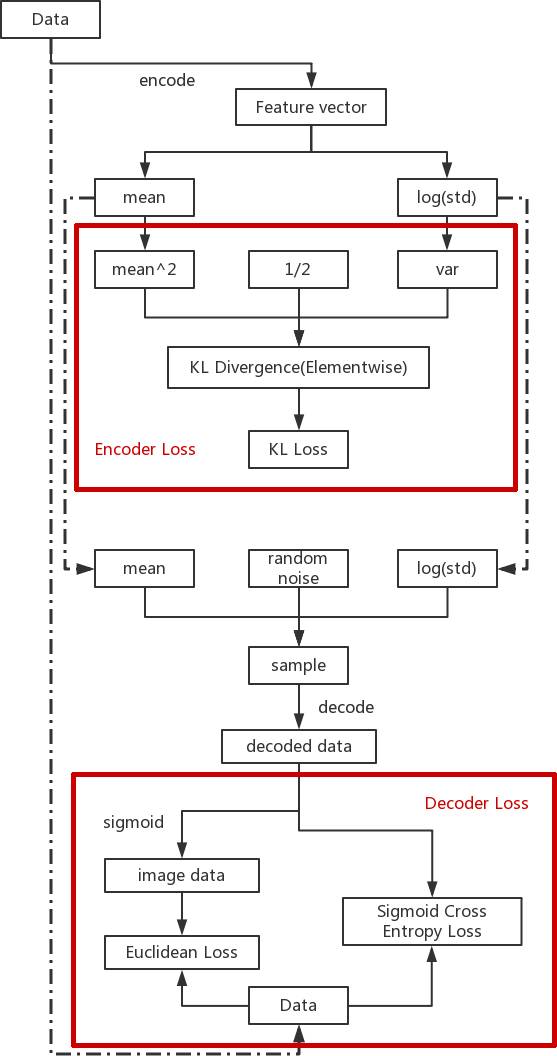
图10-1 VAE模型结构图
图中粗框表示求解Loss的部分。虚线展现了两个模块之间数据共享的情况。可以看出图的上半部分是优化Encoder的部分,下面是优化Decoder的部分,除了Encoder和Decoder,图中还有三个主要部分。
Encoder的Loss计算:KL散度。
z的重采样生成。
Decoder的Loss计算:最大似然。
这其中最复杂的就是第一项,Encoder的Loss计算。由于Caffe在实际计算过程中只能采用向量的计算方式,没有广播计算的机制,所以前面的公式需要进行一定的变换:
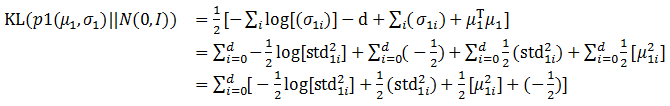
在完成了前面的向量级别计算后,最后一步就是完成汇总加和的过程。这样Loss计算就顺利完成了。
经过上面对VAE理论和实验的介绍,相信读者对VAE模型有了更清晰的认识。经过训练后VAE的解码器在MNIST数据库上生成的字符如图10-2所示。
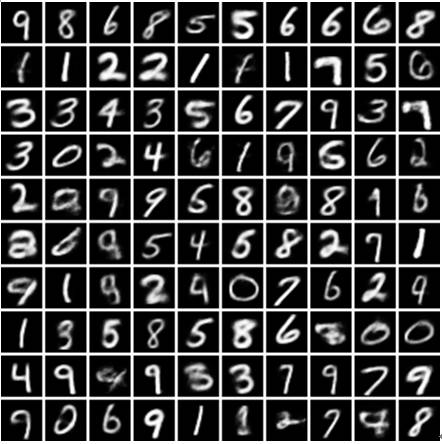
图10-2 VAE生成的数字图
MNIST生成模型可视化
除了直接观察最终生成的数字结果,实际上还有另一种观察数据的方式,那就是站在隐变量空间的角度观察分布的生成情况。实现这个效果需要完成以下两个工作。
隐变量的维度为2,相当于把生成的数字图片投影到2维平面上,这样更方便可视化观察分析。
由于隐变量的维度为2,就可以从二维平面上等间距地采样一批隐变量,这样这批隐变量可以代表整个二维平面上隐变量的分布,然后这批隐变量经过解码器处理后展示,这样就可以看到图像的分布情况了。
上面描述的算法的流程如图10-3所示。
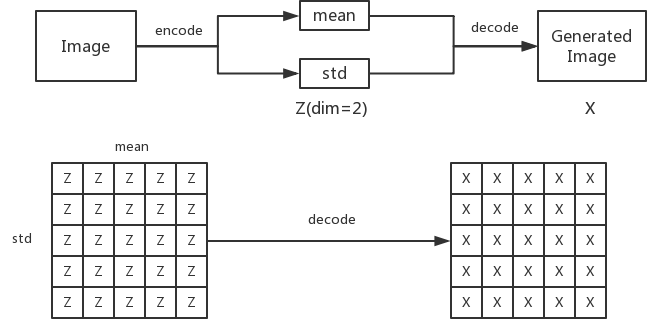
图10-3 模型可视化流程图。上图主要标识了模型的修改部分,下图介绍隐变量采样和生成的形式

图10-4 模型可视化结果
图10-4所示的模型很好地完成了隐变量的建模,绝大多数数字出现在了这个平面分布中,数字与数字一些过渡区域,这些过渡区域的图像拥有多个数字的特征,而这些数字的外形确实存在着相似之处。可以明显地感受到,图像随着隐变量变换产生了变换。
VAE的内容就介绍到这里,下面来看看另一个生成模型。
前面我们介绍了VAE,下面来看看GAN(Generative Adversarial Network)[3],这个网络组是站在对抗博弈的角度展现生成模型和判别模型各自的威力的,在效果上比VAE还要好些。
GAN的概念
同VAE模型类似,GAN模型也包含了一对子模型。GAN的名字中包含一个对抗的概念,为了体现对抗这个概念,除了生成模型,其中还有另外一个模型帮助生成模型更好地学习观测数据的条件分布。这个模型可以称作判别模型D,它的输入是数据空间内的任意一张图像x,输出是一个概率值,表示这张图像属于真实数据的概率。对于生成模型G来说,它的输入是一个随机变量z,z服从某种分布,输出是一张图像G(z),如果它生成的图像经过模型D后的概率值很高,就说明生成模型已经比较好地掌握了数据的分布模式,可以产生符合要求的样本;反之则没有达到要求,还需要继续训练。
两个模型的目标如下所示。
看上去两个模型目标联系并不大,下面就要增加两个模型的联系,如果生成模型生成的图像和真实的图像有区别,判别模型要给它判定比较低的概率。这里可以举个形象的例子,x好比是一种商品,D是商品的检验方,负责检验商品是否是正品;G是一家山寨公司,希望根据拿到手的一批产品x研究出生产山寨商品x的方式。对于D来说,不管G生产出来的商品多像正品,都应该被判定为赝品,更何况一开始G的技术水品不高,生产出来的产品必然是漏洞百出,所以被判定为赝品也不算冤枉,只有不断地提高技术,才有可能迷惑检验方。
基于上面的例子,两个模型的目标就可以统一成一个充满硝烟味的目标函数。
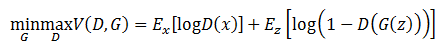
上面这个公式对应的模型架构如图10-5所示。
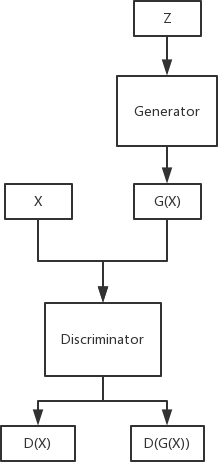
图10-5 GAN的基本形式
对应的模型学习算法伪代码如下所示:
def GAN(G,D,X):
# G 表示生成模型
# D 表示判别模型
# X 表示训练数据
for iter in range(MAX_ITER):
for step in range(K):
x = data_sample(X)
z = noise_sample()
optimize_D(G, D, x, z)
z = noise_sample()
optimize_G(G, D, z)
上面的代码只是从宏观的层面介绍了模型的优化方法,其中K表示了判别模型D的迭代次数,K一般大于等于1。从上面的公式可以看出,两个模型的目标是对立的。生成模型希望最大化自己生成图像的似然,判别模型希望最大化原始数据的似然的同时,能够最小化G生成的图像的似然。既然是对立的,那么两个模型经过训练产生的能力就可能有很多种情况。它们既可能上演“魔高一尺,道高一尺”,“道高一丈,魔高十丈”的竞争戏码,在竞争中共同成长,最终产生两个强大的模型;也可能产生一个强大的模型,将另一方完全压倒。
如果判别模型太过强大,那么生成模型会产生两种情况:一种情况是发现自己完全被针对,模型参数无法优化;另外一种情况是发现判别模型的一些漏洞后,它的模型将退化,不管输入是什么样子,输出统一变成之前突破了判别模型防线的那几类结果。这种情况被称为“Mode Collapse”,有点像一个复杂强大的模型崩塌成一个简单弱小的模型,这样的模型即使优化结果很好,也不能拿去使用。
如果判别模型不够强大,它的判别不够精准,而生成模型又是按照它的判别结果生产,那么生产出的产品不会很稳定,这同样不是我们想看到的结果。
总而言之,对抗是GAN这个模型要面对的一个大问题。虽然论文中作者试图将两个模型共同优化的问题转换成类似Coordinate Ascent那样的优化问题,并证明像Coordinate Ascent这样的算法可以收敛,那么GAN这个模型也可以。不过作者在完成证明后立刻翻脸,说证明结果和实验结果不符。所以这个问题在当时也就变成了一个悬案。
GAN的训练分析
关于GAN训练求解的过程,作者用了十分数学化的方式进行了推演。我们首先来证明第一步:当生成模型固定时,判别模型的最优形式。
首先将目标函数做变换:
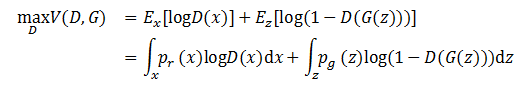
由于组成式子的两部分积分的区域不同,会对后面的计算造成困难,我们首先将两个积分区域统一。我们将生成图像G(z)的分布与真实图像x的分布做一个投射,只要判别式能够在真实数据出现的地方保证判别正确最大化即可,于是公式就变成了:
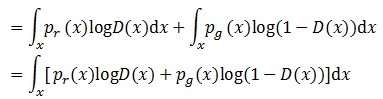
只要让积分内部的公式最大化,整个公式就可以实现最大化。这样问题就转变为最大化下面的公式:
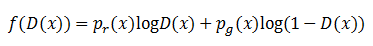
对它进行求导取极值,可以得到:
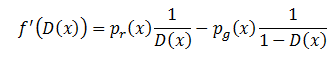
令上面的式子为0,我们可以得到结果:
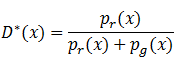
这就是理论上判别式的预测结果,如果一张图像在真实分布中出现的概率大而在生成分布中出现的概率小,那么最优的判别模型会认为它是真实图像,反之则认为不是真实图像。如果生成模型已经达到了完美的状态,也就是说对每一幅图像都有:
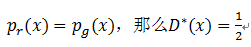
接下来就可以利用上面的结果,计算当生成模型达到完美状态时,损失函数的值。我们将D*(x)=1/2的结果代入,可以得到:
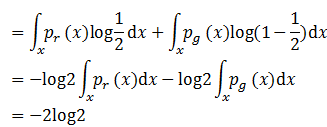
也就是说生成模型损失函数的理论最小值为-2log2。那么,一般情况下它的损失函数是什么样子呢?我们假设在某一时刻判别式经过优化已经达到最优,所以
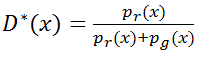
我们将这个公式代入之前的公式,可以得到:
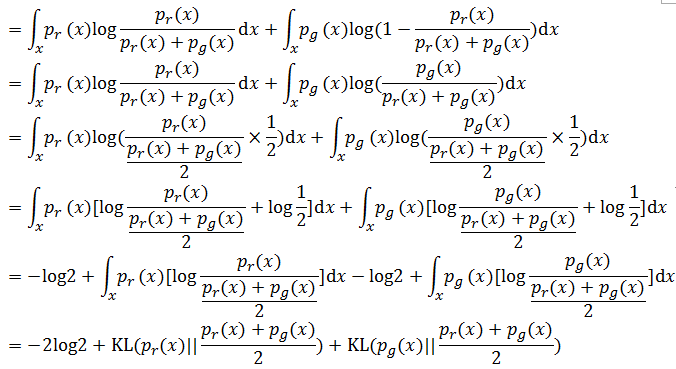
后面的两个KL散度的计算公式可以转化为Jenson-Shannon散度,也就是:
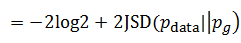
这其实是生成模型真正的优化目标函数。在介绍VAE时,读者已经了解了KL散度,也了解了它的一些基本知识,那么这个JS散度又是什么?它又有什么特性和优势?从最直观的角度,读者可以发现一个KL散度不具备的性质——JS散度是对称的:
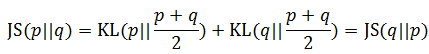
对称又能带来什么好处呢?它能让散度度量更准确。接下来将用一段代码展示这其中的道理。首先给出两个离散随机变量的KL散度和JS散度的计算方法:
import numpy as np
import math
def KL(p, q):
# p,q为两个list,里面存着对应的取值的概率,整个list相加为1
if 0 in q:
raise ValueError
return sum(_p * math.log(_p/_q) for (_p,_q) in zip(p, q) if _p != 0)
def JS(p, q):
M = [0.5 * (_p + _q) for (_p, _q) in zip(p, q)]
return 0.5 * (KL(p, M) + KL(q, M))
下面将用3组实验看看两个散度的计算结果。首先选定一个简单的离散分布,然后求出它的KL散度和JS散度。在此基础上,把两个分布分别做一定的调整。首先是基础的分布:
def exp(a, b):
a = np.array(a, dtype=np.float32)
b = np.array(b, dtype=np.float32)
a /= a.sum()
b /= b.sum()
print a
print b
print KL(a,b)
print JS(a,b)
# exp 1
exp([1,2,3,4,5],[5,4,3,2,1])
#以下为运行结果显示
[ 0.066 0.133 0.2 0.266 0.333]
[ 0.333 0.266 0.2 0.133 0.066]
0.521
0.119
接下来把公式中第二个分布做修改,假设这个分布中有某个值的取值非常小,就有可能增加两个分布的散度值,它的代码如下所示:
# exp 2
exp([1,2,3,4,5],[1e-12,4,3,2,1])
exp([1,2,3,4,5],[5,4,3,2,1e-12])
#以下为运行结果显示
[ 0.066 0.133 0.2 0.266 0.333]
[ 9.999e-14 4.000e-01 3.000e-01 2.000e-01 1.000e-01]
2.06550201846
0.0985487692551
[ 0.066 0.133 0.2 0.266 0.333]
[ 3.571e-01 2.857e-01 2.142e-01 1.428e-01 7.142e-14]
9.662
0.193
可以看出KL散度的波动比较大,而JS的波动相对小。
最后修改前面的分布,代码如下所示:
# exp 3
exp([1e-12,2,3,4,5],[5,4,3,2,1])
exp([1,2,3,4,1e-12],[5,4,3,2,1])
这回得到的结果是这样的:
[ 7.142e-14 1.428e-01 2.142e-01 2.857e-01 3.571e-01]
[ 0.333 0.266 0.2 0.133 0.0666]
0.742
0.193
[ 1.000e-01 2.000e-01 3.000e-01 4.000e-01 9.999e-14]
[ 0.333 0.266 0.2 0.133 0.066]
0.383
0.098
如果将第二个实验和第三个实验做对比,就可以发现KL散度在衡量两个分布的差异时具有很大的不对称性。如果后面的分布在某一个值上缺失,就会得到很大的散度值;但是如果前面的分布在某一个值上缺失,最终的KL散度并没有太大的波动。这个例子可以很清楚地看出KL不对称性带来的一些小问题。而JS具有对称性,所以第二个实验和第三个实验的JS散度实际上是距离相等的分布组。
从这个小例子我们可以看出,有时KL散度下降的程度和两个分布靠近的程度不成比例,而JS散度靠近的程度更令人满意,这也是GAN模型的一大优势。
GAN实战
看完了前面关于GAN的理论分析,下面我们开始实战。在实战之前目标函数还要做一点改动。从前面的公式中可以看出这个模型和VAE一样都是有嵌套关系的模型,那么生成模型G要想完成前向后向的计算,要先将计算结果传递到判别模型计算损失函数,然后将梯度反向传播回来。那么不可避免地我们会遇到一个问题,如果梯度在判别模型那边消失了,生成模型岂不是没法更新了?生成模型的目标函数如下所示:
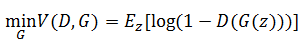
如果判别模型非常厉害,成功地让D(G(z))等于一个接近0的数字,那么这个损失函数的梯度就消失了。其实从理论上分析这个结果很正常,生成模型的梯度只能从判别模型这边传过来,这个结果接近0对于判别模型来说是满意的,所以它不需要更新,梯度就没有了,于是生成模型就没法训练了。所以作者又设计了新的函数目标:
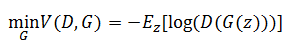
这样一来梯度又有了,生成模型也可以继续训练。当然,这个目标函数也有不足的地方。
下面来看一个具体的基于深层模型的实现——DC-GAN。全称是Deep Convolution GAN。也就是用深度卷积网络进行对抗生成网络的建模。在此之前,也有一些基于卷积神经网络的GAN实现,但是相对来说,DC-GAN的最终表现与同期的模型相比更优秀,在介绍它的论文中,作者也详细介绍了模型的一些改进细节。
下面将使用DC-GAN的模型进行实验,这个实验使用的数据集还是MNIST。由于Caffe并不是十分适合构建GAN这样的模型,因此这里使用另外一个十分流行且简单易懂的框架——Keras来展示DC-GAN的一些细节。代码来自https://github.com/jacobgil/keras-dcgan。由于Keras的代码十分直观,这里就直接给出源码。首先是生成模型:
def generator_model():
model = Sequential()
model.add(Dense(input_dim=100, output_dim=1024))
model.add(Activation('tanh'))
model.add(Dense(out_dim=128*7*7))
model.add(BatchNormalization())
model.add(Activation('tanh'))
model.add(Reshape((128, 7, 7), input_shape=(128*7*7,)))
model.add(UpSampling2D(size=(2, 2)))
model.add(Convolution2D(out_channel=64, kernel_height=5, kernel_width=5, border_mode='same'))
model.add(Activation('tanh'))
model.add(UpSampling2D(size=(2, 2)))
model.add(Convolution2D(out_channel=1, kernel_height=5, kernel_width=5, border_mode='same'))
model.add(Activation('tanh'))
return model
这里需要说明的一点是,这个实现和论文中的描述有些不同,不过对于MNIST这样的小数据集,这样的模型差异不影响效果。
判别模型的结构如下所示,仔细地读一遍就可以理解,这里不再赘述。
def discriminator_model():
model = Sequential()
model.add(Convolution2D(64, 5, 5, border_mode='same', input_shape=(1, 28, 28)))
model.add(Activation('tanh'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Convolution2D(128, 5, 5))
model.add(Activation('tanh'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(1024))
model.add(Activation('tanh'))
model.add(Dense(1))
model.add(Activation('sigmoid'))
return model
完成训练后,生成模型生成的手写数字如图10-6所示。

图10-6 GAN生成的图像
除了个别数字外,大多数数字生成得和真实数据很像。将图10-6和图10-2进行对比,我们可以发现,GAN模型生成的数字相对而言更为“清晰”,而VAE模型的数字略显模糊,这和两个模型的目标函数有很大的关系。另外,两个模型在训练过程中的Loss曲线如图10-7所示。
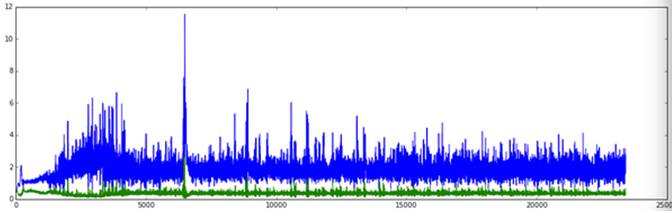
图10-7 GAN中生成模型和判别模型的损失函数
其中上面的曲线表示生成模型的Loss,下面的曲线是判别模型的Loss,虽然这两个Loss的绝对数值看上去不能说明什么问题,但是相信读者还是可以看出两个模型的Loss存在着强相关的关系,这也算是对抗过程中的此消彼长。
最终生成的数据还算令人满意,我们还很好奇,在模型优化过程中生成模型生成的图像都是什么样的呢?接下来就来观察生成图像的演变过程。在优化开始时,随机生成的图像如图10-8所示。

图10-8 GAN生成模型的初始图像
其实就是噪声图片,一点都不像数字。经过400轮的迭代,生成模型可以生成的图像如图10-9所示。

图10-9 GAN生成模型400轮迭代训练后的图像
可以看出数字的大体结构已经形成,但是能够表征数字细节的特征还没有出现。
经过10个Epoch后,生成模型的作品如图10-10所示。

图10-10 GAN生成模型经过10个Epoch迭代训练后的图像
这时有些数字已经成形,但是还有一些数字仍然存在欠缺。
20轮Epoch后的结果如图10-11所示。

图10-11 GAN生成模型经过20个Epoch迭代训练后的图像
这时的数字已经具有很强的辨识度,但与此同时,我们发现生成的数字中有大量的“1”。
当完成了所有的训练,取出生成模型在最后一轮生成的图像,如图10-12所示。

图10-12 GAN生成模型最终生成的图像
可以看出这里面的数字质量更高一些,但是里面的“1”更多了。
从模型的训练过程中可以看出,一开始生成的数字质量都很差,但生成数字的多样性比较好,后来的数字质量比较高但数字的多样性逐渐变差,模型的特性在不断发生变化。这个现象和两个模型的对抗有关系,也和增强学习中的“探索—利用”困境很类似。
站在生成模型的角度思考,一开始生成模型会尽可能地生成各种各样形状的数字,而判别模型会识别出一些形状较差的模型,而放过一些形状较好的模型,随着学习的进程不断推进,判别模型的能力也在不断地加强,生成模型慢慢发现有一些固定的模式比较容易通过,而其他的模式不那么容易通过,于是它就会尽可能地增大这些正确模式出现的概率,让自己的Loss变小。这样,一个从探索为主的模型变成了一个以利用为主的模型,因此它的数据分布已经不像刚开始那么均匀了。
如果这个模型继续训练下去,生成模型有可能进一步地利用这个模式,这和机器学习中的过拟合也有很相近的地方。
本节将要介绍GAN模型的一个变种——InfoGAN,它要解决隐变量可解释性的问题。前面提到GAN的隐变量服从某种分布,但是这个分布背后的含义却不得而知。虽然经过训练的GAN可以生成新的图像,但是它却无法解决一个问题——生成具有某种特征的图像。例如,对于MNIST的数据,生成某个具体数字的图像,生成笔画较粗、方向倾斜的图像等,这时就会发现经典的GAN已经无法解决这样的问题,想要解决就需要想点别的办法。
首先想到的方法就是生成模型建模的方法:挑出几个隐变量,强制指定它们用来表示这些特性的属性,例如数字名称和方向。这样看上去似乎没有解决问题,但这种方法需要提前知道可以建模的隐变量内容,还要为这些隐变量设置好独立的分布假设,实际上有些麻烦又不够灵活。本节的主角——InfoGAN,将从信息论角度,尝试解决GAN隐变量可解释性问题。
互信息
介绍算法前要简单回顾机器学习中的信息论基本知识。第2章已经介绍了熵和“惊喜度”这些概念,熵衡量了一个随机变量带来的“惊喜度”。本节要介绍的概念叫做互信息,它衡量了随机变量之间的关联关系。假设随机事件A的结果已经知道,现在要猜测某个事件B的结果,那么知道A的取值对猜测B有多大帮助?这就是互信息要表达的东西。
我们以掷骰子为例,如果我们知道手中的骰子是不是“韦小宝特制”骰子这件事,那么它会对我们猜测最终投掷的点数有帮助吗?当然有帮助,因为一旦确定这个骰子是“韦小宝特制”,那么骰子点数是几这个信息就变得没有“惊喜”了。同理,“美国第45届总统是谁”这个消息对我们手中骰子投掷出的点数这个事情就没那么多帮助了,所以这两件事情的互信息就低,甚至可以说这两个事件是相互独立的。
了解了上面比较直观的例子,下面就可以给出连续随机变量X,Y互信息的计算公式:
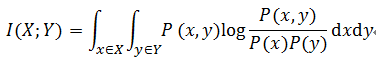
上面的公式可以做如下变换:
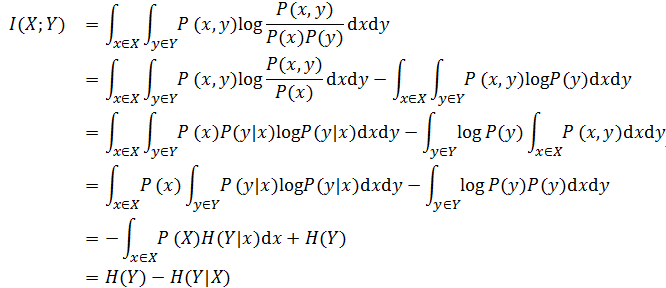
就可以发现互信息的进一步解释:它可以变为熵和条件熵的差。同样地,这个公式还可以转变为:I(X;Y)=H(X)-H(X|Y)
最终表示为熵和条件熵的差距。用通俗的话解释,两个随机变量的互信息就是在知道和不知道一个随机变量取值的情况下,另一个随机变量“惊喜度”的变化。互信息的计算方法的代码如下所示:
import numpy as np
import math
def mutual_info(x_var, y_var):
sum = 0.0
x_set = set(x_var)
y_set = set(y_var)
for x_val in x_set:
px = float(np.sum(x_var == x_val)) / x_var.size
x_idx = np.where(x_var == x_val)[0]
for y_val in y_set:
py = float(np.sum(y_var == y_val)) / y_var.size
y_idx = np.where(y_var == y_val)[0]
pxy = float(np.intersect1d(x_idx, y_idx).size) / x_var.size
if pxy > 0.0:
sum += pxy * math.log((pxy / (px * py)), 10)
return sum
下面随意给出一对随机变量和它们的概率分布,并用上面的代码分析这对变量的互信息:
a = np.array([0,0,5,6,0,4,4,3,1,2])
b = np.array([3,4,5,5,3,7,7,6,5,1])
print mutual_info(a,b)
# 0.653
a = np.array([0,0,5,6,0,4,4,3,1,2])
b = np.array([3,3,5,6,3,7,7,9,4,8])
print mutual_info(a,b)
# 0.796
很明显,下面一组数据的相关性更强,知道其中一个随机变量的取值,就会非常容易猜出同一时刻另外一个随机变量的采样值。如果我们进一步观察第二组数据,会发现任意一组数据的熵都是0.796,也就是说当知道其中一个随机变量的值后,它们的条件熵就变成了0,另一个随机变量变得完全“惊喜”了。虽然条件熵为0这个信息并没有展现在互信息的数值中,但互信息实际上就是在衡量一个相对的信息差距,并不像熵那样衡量信息绝对量。
其实数学包含了很多人生哲理和智慧。人的一生实际上一直在和熵作斗争,每个人的人生轨迹的熵意味着什么?一个人未来的不确定性?一个人未来的“惊喜”程度?有的人说自己“一辈子也就这样了”的时候,是不是表示这个人的未来已经从一个随机变量变成了常量,它的熵变成了0?为什么人们总是向往青春,是不是因为那些年华充满了各种不确定性与精彩,可以理解为熵很大?
“身体和灵魂,总有一个在路上”,是不是标榜追求最大熵的一个口号?“公务员这种稳定工作才是好工作”是不是一种追求最小化熵的行为呢?那么对于一个人来说,究竟是熵越大越好,还是熵越小越好?
回到问题,互信息在这个问题中有什么用?如果说隐变量的确定对确定生成图像的样子有帮助,那么隐变量和最终的图像之间的互信息就应该很大:当知道了隐变量这个信息,图像的信息对变得更确定了。所以InfoGAN这个算法就是要通过约束互信息使隐变量“更有价值”。
InfoGAN模型
那么,InfoGAN模型的具体形式是什么样的呢?如果把互信息定义为损失函数的一部分,这部分损失函数就是InfoGAN中基于经典GAN修改的部分。前面的小节已经推导出了互信息的公式,那么在具体计算时要使用哪个公式计算呢?
I(X;Z)=H(X)-H(X|Z)
I(X;Z)=H(Z)-H(Z|X)
最终的选择是后者,因为图像X的分布太难确定,求解它的熵肯定相当困难,所以前者的第一项非常难计算。当然,即使选择了第二项,这个公式也不是很好优化,因为其中还有一个后验项P(Z|X)需要求解,这也是个大麻烦,不过这里可以使用本书多次提到的方法——Variational Inference求解这个后验项。
在介绍VAE时我们曾经运用过Reparameterization Trick这个方法,这里将再次采用类似的方法。在VAE中,Trick公式是z(i)=gϕ(X+ε(i)),在Encoder的过程中,输入部分被分解成确定部分和不确定部分,然后利用一个高维非线性模型拟合输入到输出的映射。这里要求出的X,和VAE正好相反,需要的是这样的一个公式:X=gϕ([c,z]+ϵ)
其中c表示与图像有相关关系的隐变量,z表示与图像无关的隐变量。于是互信息计算公式就变成了:
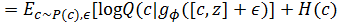
从实践上讲,ϵ项可以忽略,于是公式可以做进一步简化:
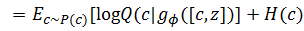
接下来将期望用蒙特卡罗方法代替,训练时可以通过计算大量样本求平均来代替期望值,于是公式又变成了:
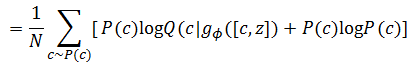
这个方程变简单了很多。当然,我们也看出上面的公式中我们有一个Q,这个Q函数可以理解为一个Encoder,这部分模型在经典GAN中并不存在,但是在实际建模过程中,由于Encoder和判别模型的输入相同,且模型目标比较相近,因此二者部分网络结构可以共享。论文的作者提供了InfoGAN的源码,代码的链接在https://github.com/openai/InfoGAN,代码使用的框架为TensorFlow,感兴趣的读者可以自行阅读。模型实现的结构如图10-13所示。
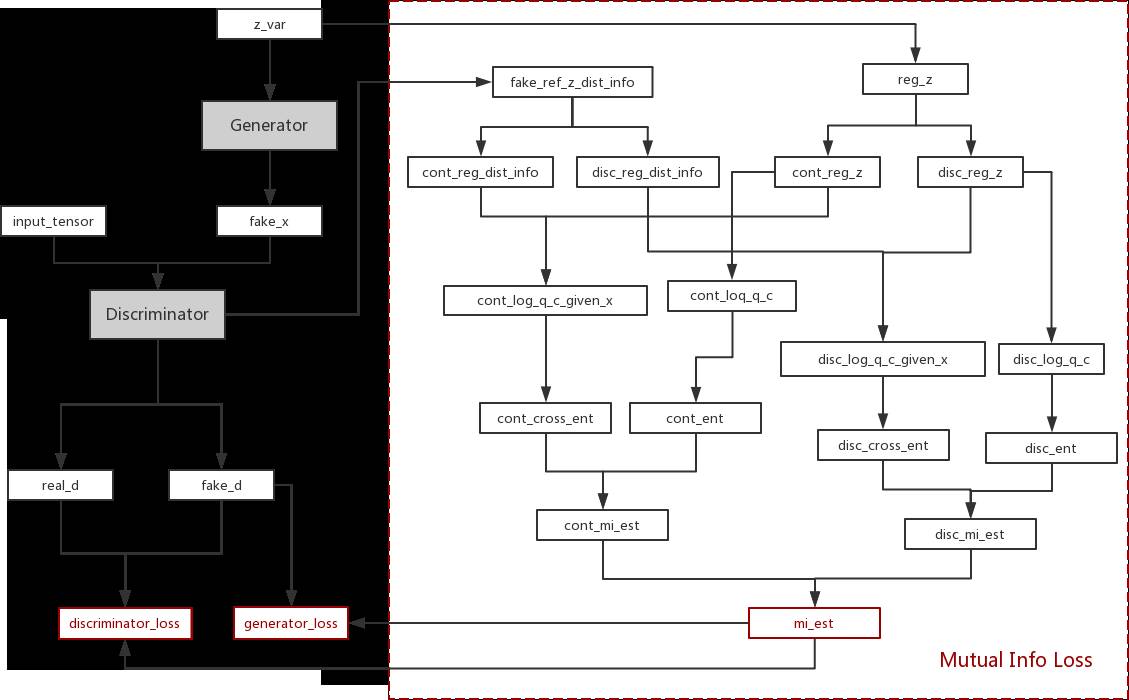
图10-13 InfoGAN模型结构图
虚线部分表示的就是计算互信息的目标函数,这部分内容看似比较复杂,实则不然。由于InfoGAN模型中定义了两种类型的随机变量——服从Categorical分布、用于表示数字内容的离散类型变量,和服从均匀分布用于表示其他连续特征的连续型变量,而两种类型的变量在计算熵的方法不同,因此上面的计算图对它们进行分情况处理。
互信息计算起始于如下两个变量。
接下来,根据连续型和离散型的分类,两个变量分成了以下四个变量。
cont_reg_z:reg_z的连续变量部分
cont_reg_dist_info:fake_ref_z_dist_info的连续变量部分
disc_reg_z:reg_z的离散变量部分
disc_reg_dist_info:fake_ref_z_dist_info的连续变量部分
接下来,四个变量两两组队完成了后验公式P(c)logQ(c|gϕ([c,z])的计算:
cont_log_q_c_given_x:连续变量的后验
disc_log_q_c_given_x:离散变量的后验
同时,输入的隐变量也各自完成先验P(c)logP(c)的计算:
cont_log_q_c:连续变量的先验
disc_log_q_c:离散变量的后验
由于上面的运算全部是元素级的计算,还要把向量求出的内容汇总,得到∑P(c)logQ(c|gϕ([c,z])和∑P(c)logP(c) 。
cont_cross_ent:连续变量的交叉熵
cont_ent:连续变量的熵
disc_cross_ent:离散变量的交叉熵
disc_ent:离散变量的熵
接下来,根据互信息公式两两相减,得到各自的互信息损失。
cont_mi_est:连续变量的互信息
disc_mi_est:离散变量的互信息
最后将两者相加就得到了最终的互信息损失。
模型在训练前定义了12个和图像有强烈互信息的随机变量,其中10个变量表示显示的数字,它们组成一个Categorical的离散随机向量;另外2个是服从范围为[-1,1]的连续随机变量。训练完成后,调整离散随机变量输入并生成图像,得到如图10-14所示的数字图像。

图10-14 10个离散随机变量对生成数字的影响
可以看出模型很好地识别了这些数字。调整另外两个连续随机变量,可以生成如图10-15所示的数字图像。

图10-15 2个连续随机变量对生成数字的影响
可以看出,这两个连续随机变量学到了数字粗细和倾斜的特征,而且这是在完全没有暗示的情况下完成的。可见InfoGAN模型的能力。
到此InfoGAN的介绍就结束了。从这个模型可以看出,在经典GAN模型基础上添加更多的内容会产生更多意想不到的效果。
本章主要介绍了基于深度学习的生成模型,它们在生成图像上有着很强的能力。
《深度学习轻松学》订购链接(或点击「阅读原文」):
https://item.jd.com/12106435.html#

又双叒叕赠书啦!!!
留言告诉头条宝宝你想获得这本书的理由,本宝宝结合有价值的评论和点赞选出3位同学赠送此书。
开奖截止时间8月14日(下周一)中午12点!











