本文来源于Eugenio Culurciello's blog
作者
:
Eugenio Culurciello
Linkedin:
https://www.linkedin.com/in/eugenioculurciello
翻译
:
郭昕 (蚂蚁金服 – 人工智能部)
原文标题:
Neural Network Architectures
接上文,感兴趣的童鞋可以翻到小天的上一篇文章《Eugenio Culurciello的神经网络结构解析(Part 1)》。此外,
本篇将分享
Eugenio Culurciello的
深度学习课程(含视频&文档)
,感兴趣的小伙伴可以拉到文末查看学习。
我们的神经网络结构之旅来到了现代工业级应用中最常见的结构——Google的Inception系列模型以及微软的ResNet。
Google实验室的Christian Szegedy开始了一系列致力于降低深度学习模型的尝试(例如VGG)的计算压力,这一系列尝试的第一篇文章就是Going Deeper with Convolutions。
(
https://arxiv.org/abs/1409.4842
)
截止2014年秋天,深度学习模型在图片以及视频帧内容的分类里已经取得了极大进展,大部分对深度学习和神经网络的质疑也基本上偃旗息鼓了。鉴于这类技术取得的巨大成功,像Google这样的科技巨头开始探索这类模型结构在他们服务器集群上的高效以及大规模部署。
Christian思考了很多方法来降低计算压力,同时还能保持最好的分类效果;或者能够在同样的计算资源下,可以获得更好的图像处理效果。
他以及他在Google的组提出了Inception模型:
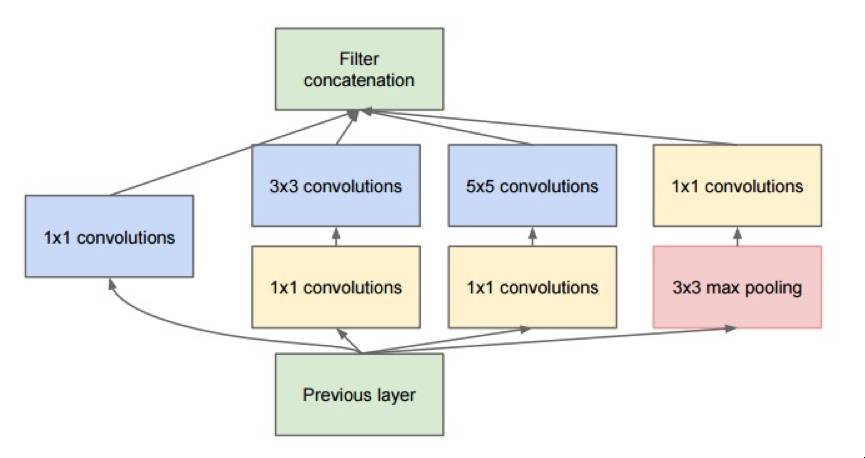
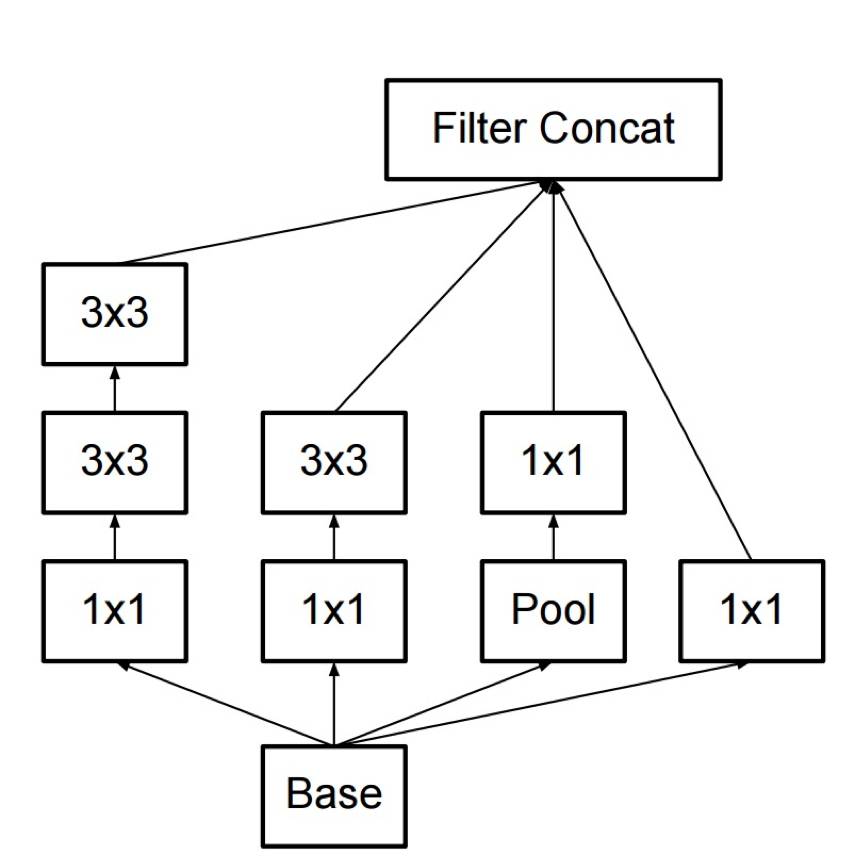
这个模型第一眼看起来,基本上是一个对1x1,3x3以及5x5卷积滤波器的并行归并,但是Inception模型一个最重要的直觉,是在于通过使用1x1卷积滤波器(NiN)来大大减少了在并行模块前的大量特征,这一思想一般我们称之为”bottleneck”, 关于这一思想,我们会在Bottleneck Layer这一章节来详细介绍。
GoogLeNet使用了一个不包含Inception模块的主干来作为初始层,然后使用了类似NiN的平均pooling以及softmax分类器的结构。这一模型相比于AlexNet以及VGG,也是属于使用了极少的可训练参数的模型之一,具体的细节可以参见我们的论文:
https://arxiv.org/abs/1605.07678
受到NiN的模型设计的启发,Inception模型的Bottleneck Layer在每一层减少了使用的特征,这也减少了所需要的计算操作,所以在运行时所花费的时间能保持在一个较少的水平。在传输数据到计算量较大的卷基层之前,特征的数目被减少了大约4倍。这一设计大大减少了计算耗时,使得这一模型得到了成功的工业级应用。
下面让我们来看看Bottleneck Layer的设计细节。假设你有256维特征输入,256维特征输出,Inception层仅进行3x3的卷积运算,那么将要进行 256x256 x 3x3 的卷积操作(这个大约是589000多的MAC基础操作),这可能已经超过了我们所能提供的计算资源预算(假设对这一层计算,使用Google的服务器,我们需要在0.5毫秒内完成)。那么如果我们不是直接对这256维特征做直接的卷积计算,而是减少特征维度,比如减少到64维(256 / 4)。针对这个方式,我们需要 256 –> 64 的1x1 卷积,然后这64维特征进入Inception的全部并行分支进行计算,然后再通过 1x1的卷积操作来恢复256维的输出 64 –> 256,那么我们所要进行的全部操作数据可以计算如下:
λ 256x64 x 1x1 = 16000
λ 64x64 x 3x3 = 36000
λ 64x256 x 1x1 = 16000
这总计是大约70000的操作数量,相比我们之前接近600000的操作数量,我们获得了接近10倍的加速。
虽然我们进行了更少的操作,但是我们并没有在这一层损失什么泛化性能,实时上,Bottleneck Layer在ImageNet的实验中取得了非常好的结果,同时这一结构也被应用于ResNet等下一代架构中。
这一设计之所以会成功,主要的原因还是在于输入的数据特征是相互关联的,他们之间的冗余性可以通过1x1的卷积来去除并大致模拟他们的基本特性。而使用较少数量的特征经过真正的卷积操作之后,他们还能通过1x1的卷积来恢复出有意义的特征用于下一层的输入。
Christian以及他的团队是非常高效的研究者,在2015年2月,他们提出了批量归一化(Batch-normalized)版本的Inception模型,并命名为Inception V2 (
https://arxiv.org/abs/1502.03167
) 批归一化(batch normalization)通过计算每一层输出特征的均值以及标准差,来归一化这些输出值,这相当于对数据做了”白噪声化”的处理,这能够把所有神经网络输出层的数据限制在同样的范围内,同时保持均值为0。这一设计帮助神经网络在训练的过程中不需要关注如何对数据做平移等问题,而仅仅专注在如何更好的拟合特征,可以加速训练。
在2015年12月,他们又发表了一个新版本的Inception模型以及对应结构 (
https://arxiv.org/abs/1512.00567
) 。在这篇文章中,涉及到更多对原始GoogLeNet结构的解释,对更多设计的选择给出了详尽的解答。其中一些原创性的工作列举如下:
1. 通过合理设计网络的深度和广度来最大化网络中的信息流;在每一层pooling之前,都需要增加特征映射数量
2. 当深度增大的时候,相应的广度(即特征的维度)也需要相应增加
3. 每一层广度的增加都能够增加更多的特征组合,然后用于下一层的作为输入
4. 尽量使用3x3的卷积操作,因为5x5或者7x7的卷积操作都可以通过3x3卷积的级联来获得,具体可以见下图:
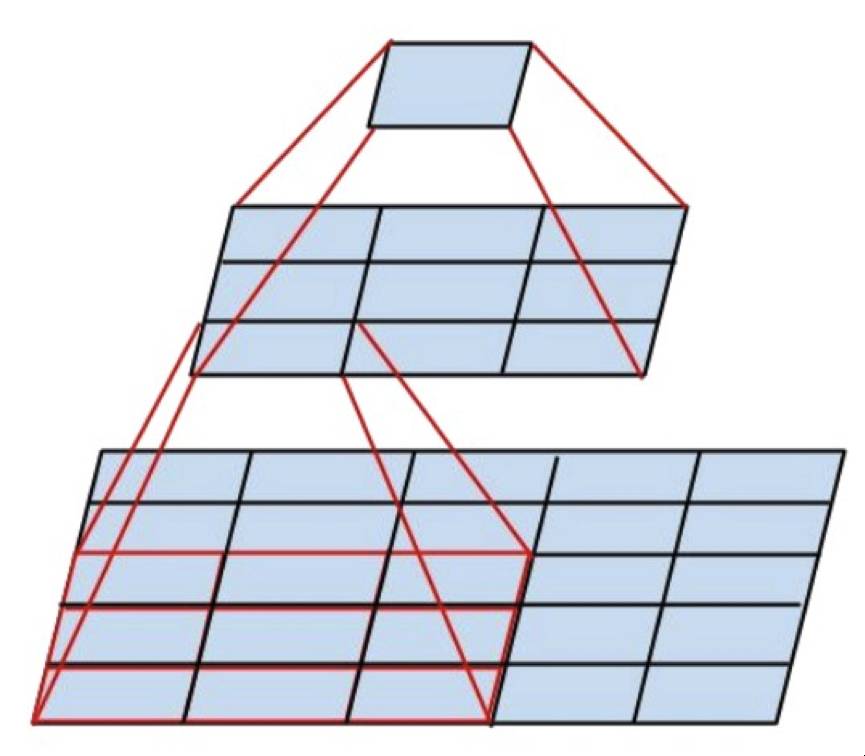
5. 于是新的Inception模块就如下图所示: