在过去的两年间,Python一路高歌猛进,成功窜上“最火编程语言”的宝座。
惊奇的是使用Python最多的人群其实不是程序员,而是数据科学家,尤其是社会科学家,涵盖的学科有
经济学、管理学、会计学、社会学、传播学、新闻学
等等。
大数据时代到来,网络数据正成为潜在宝藏,大量商业信息、社会信息以文本等非结构化、异构型数据格式存储于网页中。非计算机专业背景的人也可借助机器学习、人工智能等方法进行研究。使用网络世界数据进行研究,面临两大难点:
数据获取需要借助Python编程语言设计网络爬虫,而获得的数据中有相当比例数据是非结构化数据,这就需要文本数据分析技术。爬虫市面上有很多爬虫课,这里我们举文本分析的一个应用。
使用Python
可以帮助我们加速洞察的
广度和速度
,假设你需要研究几千家公司数十年的报告,需要你标记出
-
公司发生重大政策变化的年份
-
外部环境发生重大变化的年份
如果靠人工去挖掘这两类信息,很难,不具有可实施性。但熟悉Python的人,
会借助Pandas粗略的绘制出每一个公司年报前后年份的相似性曲线
,再用人工去读图。就会很快的识别出或政策或环境发生变化的时间点。
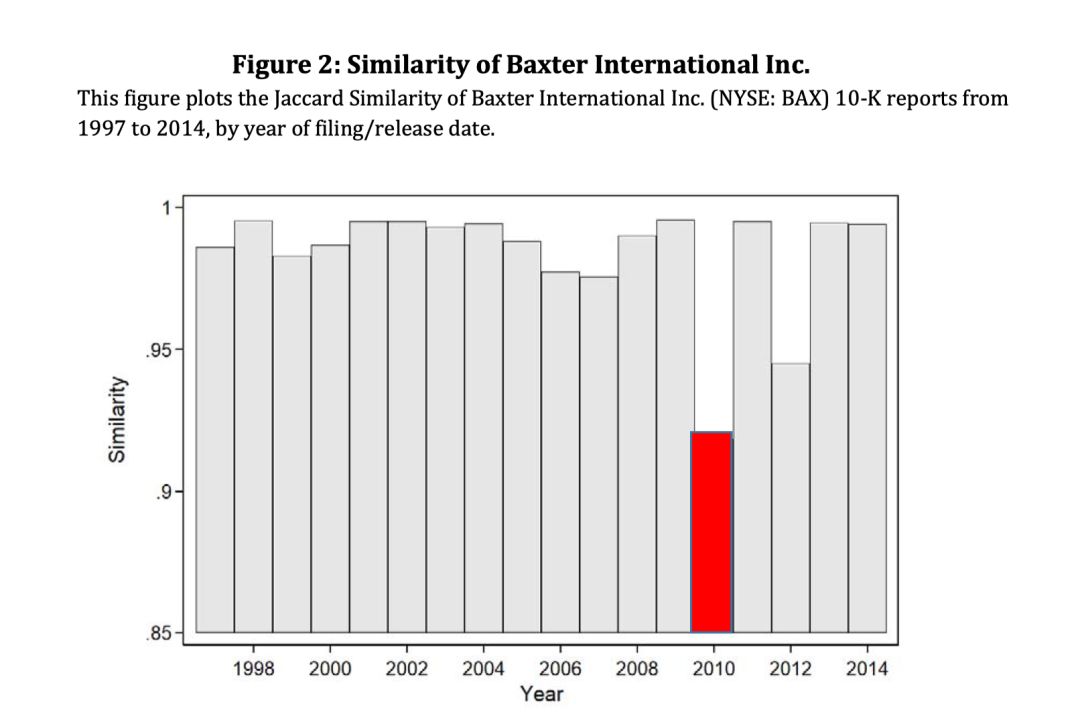
上图是
Cohen, Lauren, Christopher Malloy, and Quoc Nguyen.
Lazy prices
. No. w25084. National Bureau of Economic Research, 2018.
文中的一图。我们知道
前后年份年报相似性越小,说明该年份前后发生了很大的改变
。图中红色位置很辣眼睛,每家公司的海量的年报只需简单的读图就帮我们快速锁定2010年前后报告中含有某些重大变故,在这个案例中,工作效率说提高几十倍应该是妥妥的。
课程介绍
课程知识点分布
Mac环境配置
Windows环境配置
pip安装问题解决办法
jupyter notebook使用方法
python跟英文一样也是一门语言,这很文科
字符串
列表
元组
字典
集合
if条件语句
for循环语句
try-except异常处理语句
切片-对想要的数据字段进行切片
列表推导式
函数
csv文件存储库
os文件路径操作库
re正则表达式(文本分析利器)
python初学者常见错误
理解访问与请求
寻求网址规律
开发者工具的使用
requests访问库
pyquery网页解析定位库
静态网站-天涯论坛
静态网站-大众点评
静态网站-boss直聘
动态网站-百度企业信用
动态网站-京东评论
动态网站-B站弹幕
动态网站-B站评论
如何用pandas采集网页中的表格数据
如何从不同格式的文件中读取数据
jieba分词、词频统计与可视化
海量公司年报的情感分析(中文)
英文数据的情感分析
如何对excel、csv文件做数据分析(pandas数据分析库)
机器学习概论
用机器学习做文本分析的步骤
机器学习库scikit-learn
文本特征工程(描述数据的方式)
在线评论情感分类
了解聚类Kmeans算法
文本相似度计算
LDA话题模型
计算消费者异质性(特征向量)
文本分析在经管研究中的应用案例










