背景
随着流量业务的高速发展以及已经到来的5G时代,业务支撑系统的规模不断增大、服务不断增多,业务、应用和系统运行性能指标数据持续以指数级的速度增长,每日计费话单量已突破百亿。系统监控的实时性、准确性的能力不足成为运维工作的瓶颈。
江苏移动IT运维团队携手新大陆以SRE理念为指导
,结合实时监控“高并发写入”、“低查询延时,高查询并发”、“轻量级存储”等实际诉求,深入研究时序数据库的特性和适用程度,打造符合自身系统运维特点的性能管理平台,实现百亿级话单处理过程的实时全景监控分析。
时序库选型
目前市场较流行的时序数据库产品有Prometheus、Graphite、InfluxDB、OpenTSDB等,我们比对了这些产品的使用范围、优缺点。
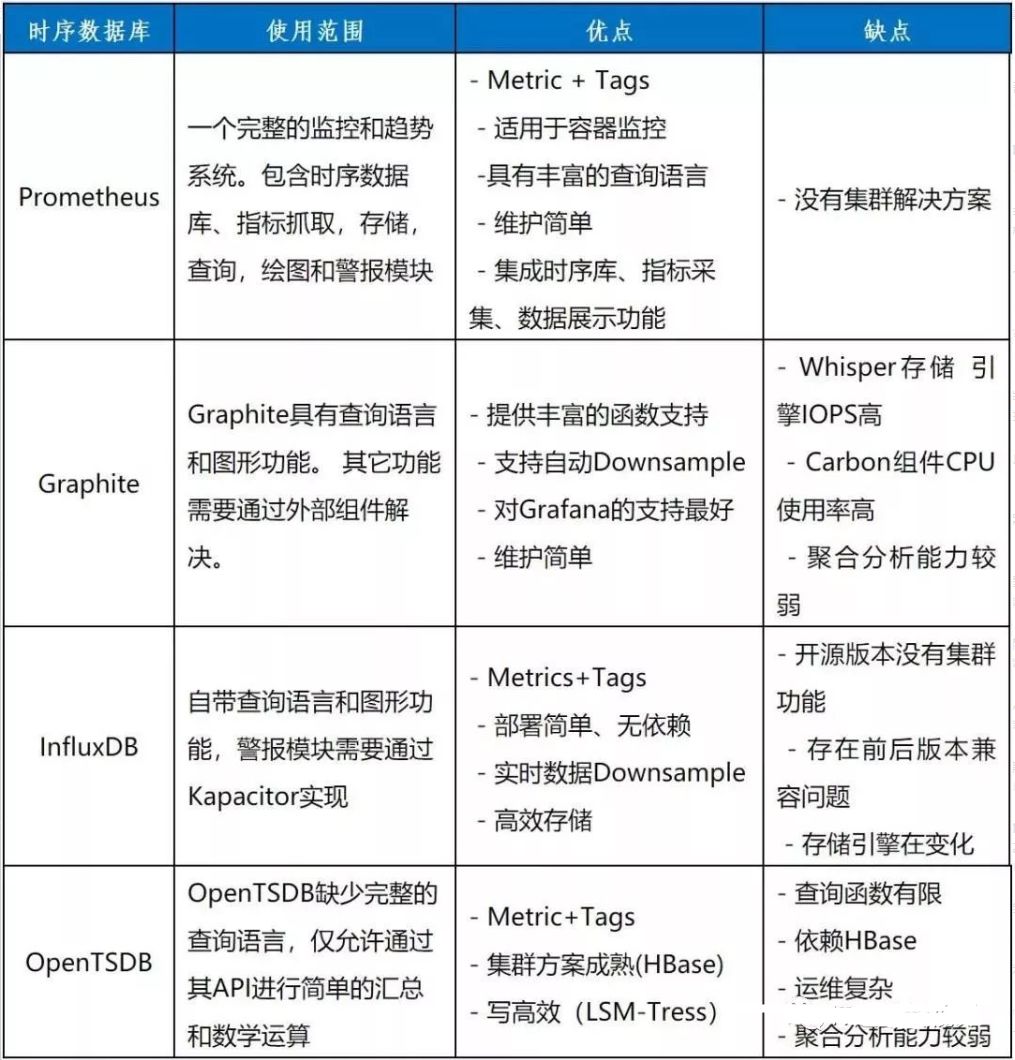
通过比较,我们发现 Prometheus 最适合搭建BOSS运维监控系统。单个的Prometheus实例就能实现每秒上百万的采样,同时支持对于采集数据的快速查询。Prometheus对于采样数据进行压缩存储,16字节的采样数据平均只需要1.37个字节的存储空间,极大减少了存储资源占用。查询实时数据时,磁盘I/O平均负载小于1%。
性能管理平台架构设计
本方案中运维人员以Prometheus时序库为中心,实现与应用相关的所有实时监控数据的采集、清洗、存储,并实时展现系统总体和各环节、各独立应用处理性能、趋势性的预测和智能分析,准确掌握系统运行健康度。
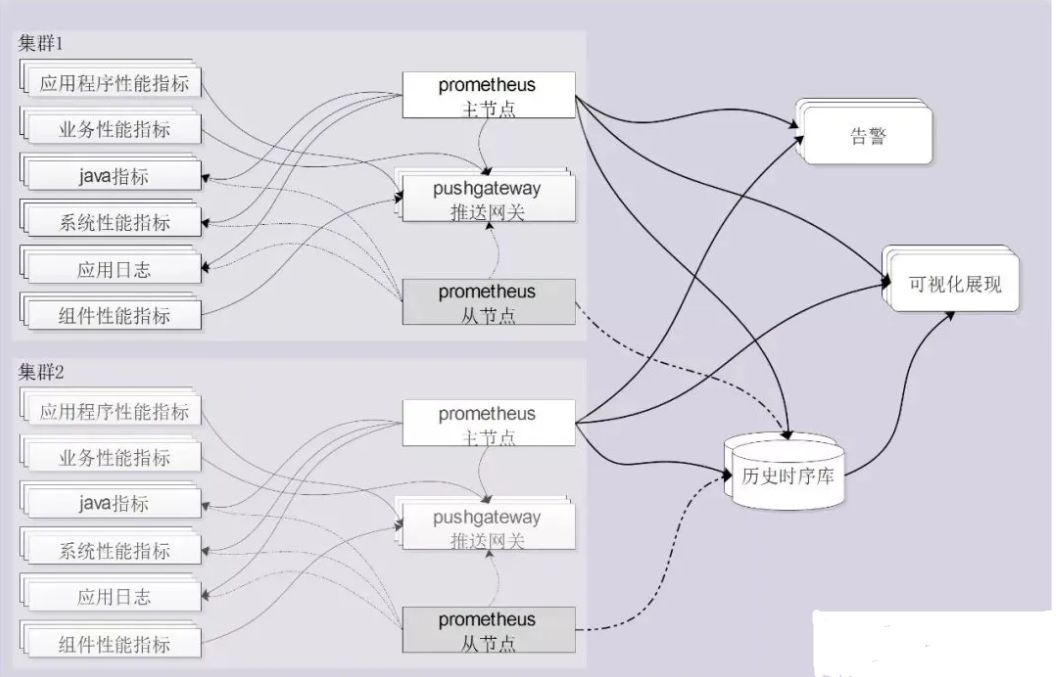
图1 系统架构
-
根据业务系统的部署,我们在双中心各部署一套Prometheus集群。
-
对于系统、应用日志、Java应用我们采用拉取方式采集指标数据;对于应用、业务、组件的性能指标数据采用推送网关(pushgateway)暂存数据,然后再由Prometheus拉取的方式采集。
-
为保证实时采集和查询的高性能,采集prometheus时序库中保存短期内较近数据,同时写入一份到远程的历史时序库中。
-
可视化展示和实时告警通过负载均衡从prometheus和历史库中采集数据。
适配性改造
在部署和使用过程中我们发现原生Prometheus存在一些不足,为此我们进行了一些适配改造工作。
1、
夯实高可用能力
:原生的Prometheus部署都是单点的,不足以保证数据可用性,为此我们通过服务注册的方式实现了Prometheus的高可用性。集群启动时每个节点都尝试获取锁,获取成功的节点成为主节点执行任务,若主节点宕机,从节点获取锁成为主节点并接管服务。
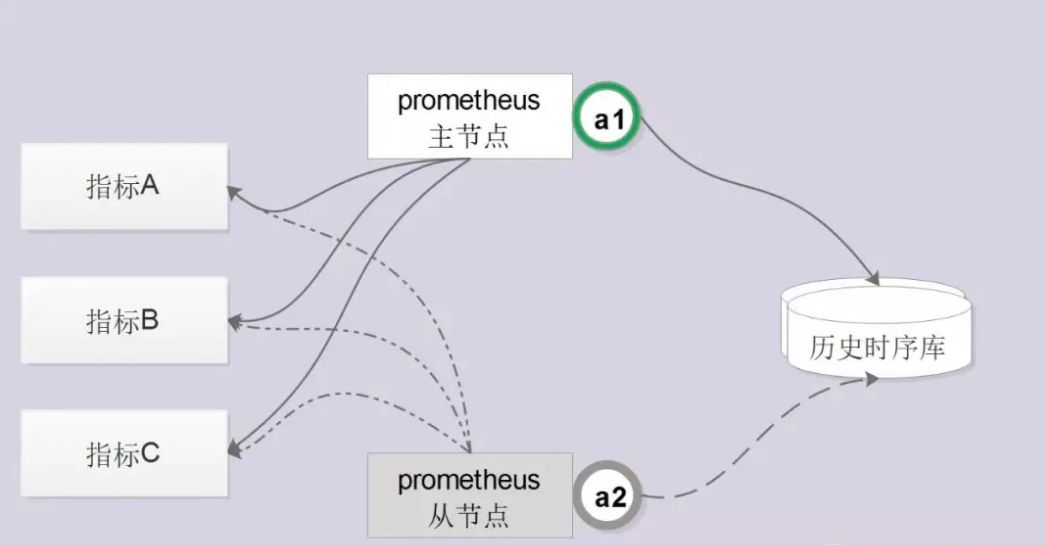
图2 高可用能力实现方式
2、
优化数据存储方式
:在Prometheus节点上保存短周期数据用于告警实时触发和展现,引入InfluxDB用于实时传输并保存长周期的历史数据,保证采集数据的连续性并为后续数据挖掘提供资源支撑。
3、
自研改造推送网关组件
:在实际使用过程中我们发现推送网关(pushgateway)中的数据有较大概率被重复采集到Prometheus中,容易产生错误的性能数据和误告警。为此我们在Prometheus的采集方法中增加从pushgateway拉取数据后主动删除数据的保障机制,确保数据采集的唯一性。





