

原文来源
:arXiv
作者:
Yusuf Aytar、Tobias Pfaff、David Budden、Tom Le Paine、Ziyu Wang、Nando de Freitas
「雷克世界」编译:嗯~是阿童木呀、EVA
导语:我们都知道,人们可以通过在线观看视频,学习从编织到跳舞再到玩游戏等许多任务。展示出将从在线演示中所学到的知识迁移到现实任务的能力。那人工智能中的智能体能否获得这种能力呢?最近,DeepMind的一些科学家提出了一种新方法,通过观看YouTube视频,指导智能体进行探索以赢得难以完成的游戏。
深度强化学习方法通常在环境奖励(environment reward)特别稀疏的任务中存在较大的困难。在这些领域中有一个成功的方法能够指导探索,就是去模仿人类演示者提供的轨迹。然而,这些演示通常是在人工条件下收集的,即可以访问智能体的精确环境设置和演示者的动作以及奖励轨迹。在本文中,我们提出了一种两个阶段的方法,它能够通过依赖没有访问过这些数据的嘈杂、未对齐的视频素材来克服这些限制。首先,我们学习使用在时间和模态(即视觉和声音)上构建的自监督目标(self-supervised objective),将来自多个来源的未对齐视频映射到一个共同表征上。其次,我们在该表征中嵌入一个YouTube视频以构建一个奖励函数,鼓励智能体模仿人类的游戏玩法。这种一次性模仿(one-shot imitation)的方法让我们的智能体在臭名昭著的难于完成的探索游戏《蒙特祖玛的复仇》(MONTEZUMA’S REVENGE)、《逃离险境》(PITFALL! )和《私人侦探》(PRIVATE EYE)中第一次令人信服地超越了人类水平的表现,即使智能体没有获得任何环境奖励。

图1:Atari学习环境与YouTube视频之间存在的域差距的图示,我们的智能体可以通过这些视频学习如何玩《蒙特祖玛的复仇》。请注意不同的尺寸、分辨率、宽高比、颜色以及文字和头像等视觉工件的添加。
人们通过在线观看视频,学习了从编织到跳舞再到玩游戏等许多任务。他们展示了能够将从在线演示中得到的知识迁移到手头任务的卓越能力,尽管在时间选择、视觉外观、传感模态(sensing modality)和身体差异方面存在巨大的差异。这种具有丰富无标签数据的设置促进了人工智能的研究议程,这可能会带来第三人称模仿(third-person imitation)、自监督学习(self-supervised learning)、强化学习(reinforcement learning,RL)和相关领域的重大进展。在本文中,我们展示了所提出的这个研究议程是如何使我们能够在对RL智能体的嘈杂演示序列的自监督队列中取得一些初步的进展,使在最复杂且之前未解决的Atari 2600游戏中取得人类水平的性能。
尽管在深度强化学习算法和架构方面取得了一些最新进展,但仍存在许多“艰苦探索”的挑战,其特点是环境奖励非常少,这依旧对现有的RL智能体提出了一个极具困难的挑战。一个典型的例子是Atari的《蒙特祖玛的复仇》,它需要一个像人类一样的化身来驾驭一系列的平台和障碍(其特性从空间到空间本质上发生了改变)以收集得分的物品。在这种任务中使用幼稚、贪婪的探索方法几乎是不可能的,因为在分离奖励的帧数中,可能的动作轨迹的数量呈指数增长。例如,在《蒙特祖玛的复仇》中获得第一个环境奖励需要大约100个环境步骤,相当于10018个可能的动作序列。即使随机遇到奖励,如果这个信号在特别长的时间范围内有所备份,那么折中权衡的RL就难以稳定地学习。
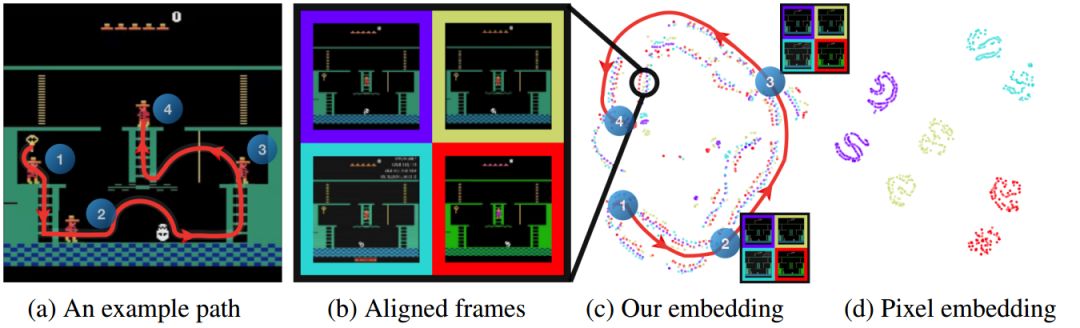
图2:对于(a)中所示的路径,使用(c)我们的嵌入与(d)原始像素形成的观察序列的t-SNE投影。在(b)中,四个不同的域在(b)中并排进行比较,以获得《蒙特祖玛的复仇》中的样本框架:(紫色)Atari学习环境,(青/黄)两个YouTube训练视频,以及(红色)未观看的YouTube视频。很显然,尽管(紫色)和(红色)在训练期间被搁置在一边,但在我们的嵌入空间中所有四条轨迹都很好地对齐。使用原始的像素值无法实现任何有意义的对齐。
可以这样说,试图克服稀疏奖励问题的成功性方法大致分为两类,即指导性探索。首先,内在动机方法提供了一种辅助奖励,鼓励智能体探索关于某些度量的“全新性”或“信息性”的状态或行动轨迹。这些方法倾向于帮助智能体重新探索那些看起来全新的、或不确定的已知部分状态空间(已知—未知),但往往无法提供关于这些状态在环境中的哪些地方可以首先被发现的指导(未知—未知)。因此,这些方法通常依赖于附加的随机组件来驱动初始的探索过程。另一类是模仿学习(imitation learning),藉于此,人类演示者生成状态—行为轨迹,用以指导探索朝着被认为具有归纳偏差的突出性区域前进。这些偏差在Atari环境中被证明是一个非常有用的约束,因为人类可以立即做出识别,例如,头骨代表危险,或者一把钥匙能够打开一扇门。
图3:我们的联合TDC + CMC自监督损失计算中所涉及的网络架构和交互。
在现有的模仿学习方法中,Hester等人所提出的DQfD已在Atari最难探索游戏中展示了最佳的性能表现。尽管取得了这些令人印象深刻的结果,但在DQfD和相关方法里面存在两个局限性。首先,他们假设智能体和演示者的观察空间之间没有“域差距”,例如,颜色或分辨率的变化,或其他视觉工件的引入。图1显示了《蒙特祖玛的复仇》(MONTEZUMA'S REVENGE)中“域差距”的一个例子,考虑了(a)我们的环境与(b)YouTube游戏画面相比的第一帧。其次,他们假设智能体可以访问确切的动作和奖励序列,而这些确切的动作和奖励序列导致了演示者的观察轨迹。在这两种情况下,这些假设限制了在人工条件下收集的那些有用的演示集,通常需要专门的软件堆栈以用于强化学习智能体训练的唯一目的。
为了解决这些局限性,本文提出了一种新方法,用以克服多个演示中观察序列之间的域差距,通过使用在时间(时间距离分类)和模态(跨模态时间距离分类)上构建的自监督分类任务来学习一个通用的表征(见图2)。与以前的方法不同,我们的方法既不需要(a)演示之间的逐帧对齐(frame-by-frame alignment),也不需要(b)类标签或其他注释,而这些类标签或注释可能是从一个对齐中间接推断出来的。我们还提出了一种新的度量(循环一致性)来评估这种已学习嵌入的质量。
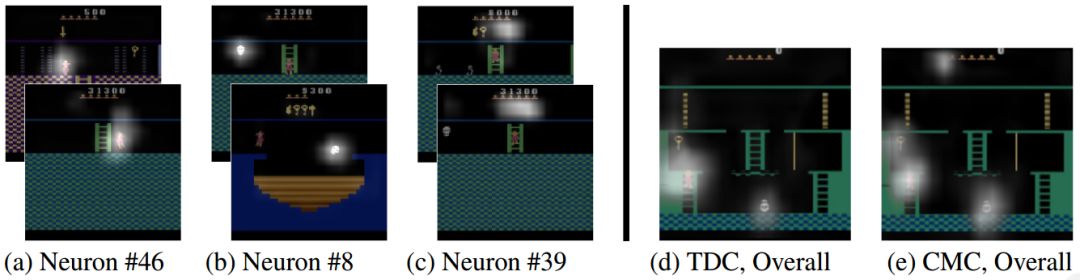
图4:(左)最后的卷积层中选择激活的可视化。单个神经元集中在例如(a)玩家、(b)敌人、和(c)库存。值得注意的是,不存在与干扰物或特定工件相关的激活。(右)在最后一层的所有渠道中对激活进行的总结式可视化。




