
来源:Python开发者
ID:
PythonCoder
Google Ngram viewer是一个有趣和有用的工具,它使用谷歌从书本中扫描来的海量的数据宝藏,绘制出单词使用量随时间的变化。举个例子,单词
Python
(区分大小写)
:
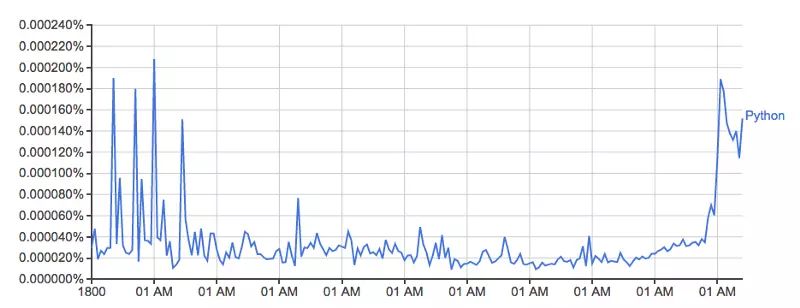
这幅图来自:books.google.com/ngrams/grap…,描绘了单词 'Python' 的使用量随时间的变化。
它是由谷歌的 n-gram 数据集驱动的,根据书本印刷的每一个年份,记录了一个特定单词或词组在谷歌图书的使用量。然而这并不完整(它并没有包含每一本已经发布的书!),数据集中有成千上百万的书,时间上涵盖了从 16 世纪到 2008 年。数据集可以免费从这里下载。
我决定使用 Python 和我新的数据加载库 PyTubes 来看看重新生成上面的图有多容易。
挑战

1-gram 的数据集在硬盘上可以展开成为 27 Gb 的数据,这在读入 python 时是一个很大的数据量级。Python可以轻易地一次性地处理千兆的数据,但是当数据是损坏的和已加工的,速度就会变慢而且内存效率也会变低。
总的来说,这 14 亿条数据(1,430,727,243)分散在 38 个源文件中,一共有 2 千 4 百万个(24,359,460)单词(和词性标注,见下方),计算自 1505 年至 2008 年。
当处理 10 亿行数据时,速度会很快变慢。并且原生 Python 并没有处理这方面数据的优化。幸运的是,numpy 真的很擅长处理大体量数据。 使用一些简单的技巧,我们可以使用 numpy 让这个分析变得可行。
在 python/numpy 中处理字符串很复杂。字符串在 python 中的内存开销是很显著的,并且 numpy 只能够处理长度已知而且固定的字符串。基于这种情况,大多数的单词有不同的长度,因此这并不理想。
Loading the data
下面所有的代码/例子都是运行在
8 GB 内存
的 2016 年的 Macbook Pro。 如果硬件或云实例有更好的 ram 配置,表现会更好。
1-gram 的数据是以 tab 键分割的形式储存在文件中,看起来如下:
Python 1587 4 2
Python 1621 1 1
Python 1651 2 2
Python 1659 1 1
每一条数据包含下面几个字段:
1. Word
2. Year of Publication
3. Total number of times the word was seen
4. Total number of books containing the word
为了按照要求生成图表,我们只需要知道这些信息,也就是:
1. 这个单词是我们感兴趣的?
2. 发布的年份
3. 单词使用的总次数
通过提取这些信息,处理不同长度的字符串数据的额外消耗被忽略掉了,但是我们仍然需要对比不同字符串的数值来区分哪些行数据是有我们感兴趣的字段的。这就是 pytubes 可以做的工作:
import tubes
FILES = glob.glob(path.expanduser("~/src/data/ngrams/1gram/googlebooks*"))
WORD = "Python"
one_grams_tube = (tubes.Each(FILES)
.read_files()
.split()
.tsv(headers=False)
.multi(lambda row: (
row.get(0).equals(WORD.encode('utf-8')),
row.get(1).to(int),
row.get(2).to(int)
))
)
差不多 170 秒(3 分钟)之后,
one
grams_ 是一个 numpy 数组,里面包含差不多 14 亿行数据,看起来像这样(添加表头部为了说明):
╒═══════════╤════════╤═════════╕
│ Is_Word │ Year │ Count │
╞═══════════╪════════╪═════════╡
│ 0 │ 1799 │ 2 │
├───────────┼────────┼─────────┤
│ 0 │ 1804 │ 1 │
├───────────┼────────┼─────────┤
│ 0 │ 1805 │ 1 │
├───────────┼────────┼─────────┤
│ 0 │ 1811 │ 1 │
├───────────┼────────┼─────────┤
│ 0 │ 1820 │ ... │
╘═══════════╧════════╧═════════╛
从这开始,就只是一个用 numpy 方法来计算一些东西的问题了:
每一年的单词总使用量
谷歌展示了每一个单词出现的百分比(某个单词在这一年出现的次数/所有单词在这一年出现的总数),这比仅仅计算原单词更有用。为了计算这个百分比,我们需要知道单词总量的数目是多少。
幸运的是,numpy让这个变得十分简单:
last_year = 2008
YEAR_COL = '1'
COUNT_COL = '2'
year_totals, bins = np.histogram(
one_grams[YEAR_COL],
density=False,
range=(0, last_year+1),
bins=last_year + 1,
weights=one_grams[COUNT_COL]
)
绘制出这个图来展示谷歌每年收集了多少单词:
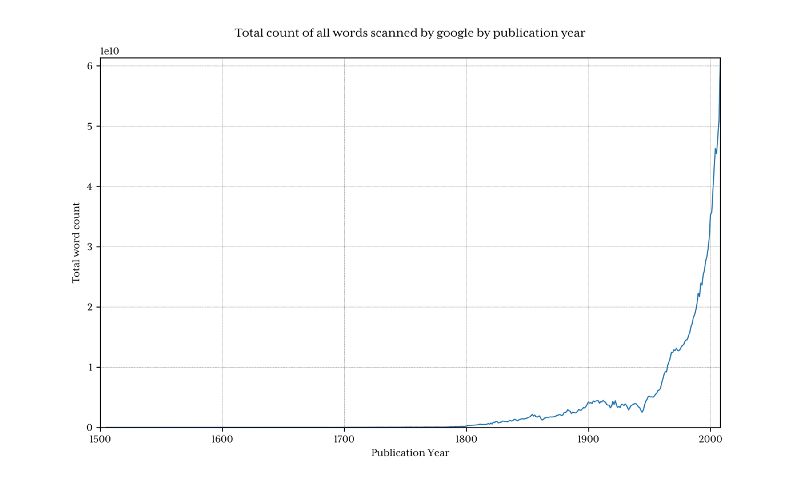
很清楚的是在 1800 年之前,数据总量下降很迅速,因此这回曲解最终结果,并且会隐藏掉我们感兴趣的模式。为了避免这个问题,我们只导入 1800 年以后的数据:
one_grams_tube = (tubes.Each(FILES)
.read_files()
.split()
.tsv(headers=False)
.skip_unless(lambda row: row.get(1).to(int).gt(1799))
.multi(lambda row: (
row.get(0).equals(word.encode('utf-8')),
row.






