
以Docker为代表的容器技术已经持续成为话题好几年了,本以为在没有历史包袱的创业公司中,Docker应该会成为生产环境上部署和管理服务的标准配置,然而最近发现一些友商在得知我们在生产上使用Docker和Kubernetes之后,居然表现出了一些惊讶。我想对于这些团队没有采纳Docker而是继续使用传统运维方案,还是觉得即使多做一些繁琐的运维工作,也希望对系统有更多的掌控度。
Docker所依赖的LXC容器技术,早在十多年前就被Google这类大厂使用了,国内的一些大厂也在很早开始投入研发和使用了,对他们来说,使用容器能够充分利用计算资源,节省硬件开销。然而对于小公司来说,把10台服务器压缩到5台服务器并不能帮助公司活下去。
容器技术真正开始广泛产生影响是从Docker的诞生开始,Docker刚出来的时候,官网上的slogan:“Build Ship Run”,准确的阐述了Docker的定位,从打包到部署,传统运维的这一套流程,由于语言,环境,平台的不同在各个公司千差万别,几乎每个公司都会开发一套自己的发布系统。有了Docker之后,这些居然都可以标准化了,并且相对于笨重的虚拟机,Docker几乎就是一个进程简单的包装,只有很少的额外开销,启动速度也几乎相当于直接启动应用进程。
对于没有专职运维的即刻团队,很自然的从项目开始就使用Docker来做服务的发布工具了:
由于一个Docker容器只是一个(或一组)进程的封装,一个容器想要向宿主机之外的网络提供服务,就只能绑定宿主机的端口了,端口的管理也是一件大部分情况下都不希望人去操心的麻烦事,为了避免端口冲突,对于需要暴露端口的容器,Docker会随机绑定一个宿主机端口,这个时候我们就需要服务发现机制来帮助不同机器上的服务来进行通信了。
我们使用了一个简单的方案,一套开源的工具:docker-discover和docker-register,它包含两个组件:
1. 每台worker node虚拟机上运行一个docker-register容器,用来扫描本地容器,把他们的服务名(用镜像名作为服务名)和端口(包括容器内端口和宿主机端口)注册到etcd上。
2. 一个docker-discover容器用来做中心代理,它内部包含了一个HAProxy,每隔几秒钟扫描Etcd上的注册服务,并生成配置文件,刷新HAProxy,生成backend配置的模版如下:
{% for service in services %}
listen {{ service }}
bind *:{{services[service].port}}
{% for backend in services[service].backends %}
server {{ backend.name }} {{ backend.addr }} check inter 2s rise 3 fall 2{% endfor %}
{% endfor %} {% for service in services %} listen {{ service }} bind *:{{services[service].port}} {% for backend in services[service].backends %} server {{ backend.name }} {{ backend.addr }} check inter 2s rise 3 fall 2{% endfor %} {% endfor %}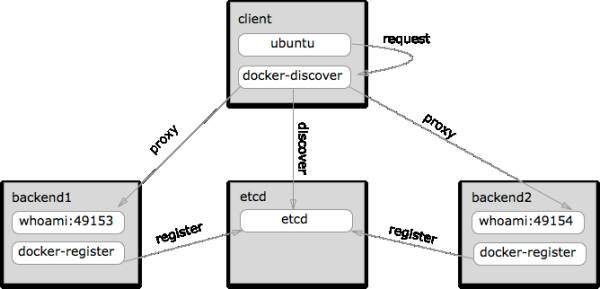
这个方案给我们提供了一套系统的几个基本功能:应用发布,服务发现,负载均衡,进程守护,其中应用发布是执行脚本去各个worker node上拉取最新镜像,进程守护则是由Docker daemon的restarts=always来提供。
除了提供一致的运行环境使服务的发布和回滚比较可控,这套简单的系统在发布流程上还是像传统运维一样需要远程执行脚本,功能比较简单,随着我们后端系统成长起来,很快就不够用了。
Docker本身只是提供了一个运行环境,除了把服务跑起来之外,要让多个服务容器协同起来工作,我们还需要一个容器编排(Orchestration)系统,一般来说我们期望编排系统能帮我们实现几个目的:
基本发布自动化功能
编排过程包含分配机器,拉取镜像,启动/停止/更新容器,存活监控,容器数量扩展和收缩。
声明式定义服务栈
提供一种机制,可以用配置文件来声明服务的网络端口,镜像及版本,在需要的时候通过配置可再现的创建出一整套服务。
服务发现
提供DNS和负载均衡,一个容器启动之后,需要其他服务能够访问到它,一个容器终止运行之后,需要保证流量不会再导向它。
状态检查
需要持续监控系统是否符合配置中声明的状态,比如一台宿主机挂了,需要把上面运行的容器在其他健康的节点上启动起来,如果一个容器挂了,需要把它重新启动。
从设计思路,社区活跃度等因素来看,Kubernetes无疑是编排工具最好的选择,但由于组件较多,学习成本并不低,还有墙的因素,在国内甚至安装都不是件容易的事。
这个时候我们发现Rancher正式发布了,虽然没有Kubernetes那么热门,但它提供了所有我们需要的功能,还有一个简单容易上手的Web UI。在早期我们的机器和服务数量都比较少,又急需一个编排工具好把有限精力都投入到开发上,所以迅速的把服务都迁移到Rancher上了。
准确的说,Rancher是一套容器管理打包方案,支持三种编排引擎:Kubernetes,Swarm,还有Rancher自己开发的Cattle(最近好像换成了Mesos)。从功能的完整性和易用性来看,Rancher甚至可以算得上一个商业软件了,部署极其简单,这也是我们选择它作为入门级容器管理平台的原因。
Rancher组件图,中小企业常用的软件功能都能找到:
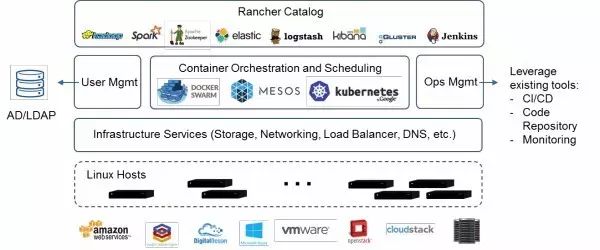
后来围绕Rancher,也使用了一些Catalog里提供的服务栈,我们逐步搭建起来了一套完整的容器运维系统,包含了日志收集,性能监控,配合AWS的Auto Scaling Group,应用扩展也是很方便的事情。
虽然Rancher非常的易用,但随着我们后端机器和项目数量的增加,它的一些问题也暴露出来了,UI卡顿,发布速度越来越慢,1.3之后甚至经常出现服务的预期状态(容器数量,版本)无法被保证,卡在发布中或者完成中状态,真正让我们下定决心要迁移的是一次重大故障,疑似网络雪崩引起,集群所有机器都在重复断开连接,本来按一般编排系统的设计,worker node上的容器之间通过Overlay网络通信,node和Rancher server的连接即使断开也不会影响已经启动的容器运行。但在1.3之后的Rancher中,不知是有意设计还是bug,worker node重新连接上Rancher server之后,节点上所有的容器会被重新Schedule,这就导致集群中所有容器都不断的被销毁又重新创建。
在Rancher上碰到大大小小的问题,我们发现大部分都很难找到社区提供的解决方案,我们很可能是不幸比较早踩坑的人,虽然Rancher是开源的,但技术上的文档相比使用文档明显欠缺很多,想通过了解他的实现来排查问题比较困难,也很少有Rancher公司之外的contributor,这点是和Kubernetes很明显不同的。
和Rancher提供了一整套解决方案不一样,Kubernetes提供的是一个框架,对于Rancher,即使不熟悉其中各个组件,也可以直接用预设的配置安装,拿来当一个发布工具使用,Kubernetes则要求使用者对他的组件有一定程度了解,社区提供了很多帮助部署的installer,但使用前都需要不少配置工作。
DevOps同事画的Kubernetes架构图:
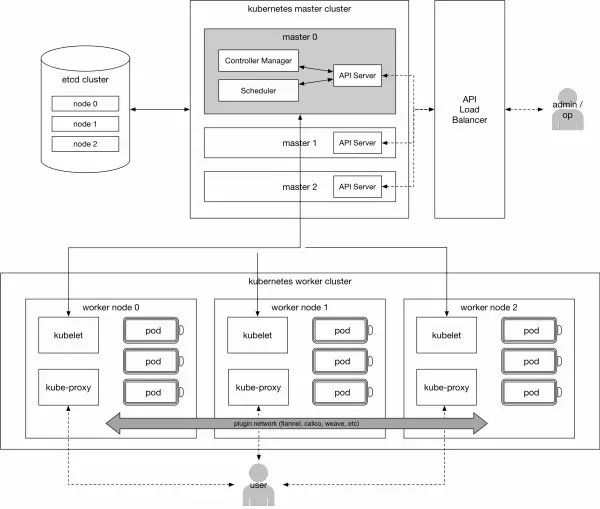
在Rancher上积累了一些容器编排的经验之后,我们对使用Kubernetes做编排也有了一些信心,于是开始迁移到性能更好,社区更活跃的Kubernetes上。
我们将线上服务一点点从Rancher上把流量切换到Kubernetes集群,起初发现流量稍微增涨便丢包严重,定位到问题是DNS解析缓慢,观察kernel log发现宿主机conntrack count到达上限,出现丢包。
这里解释一下iptable里的conntrack:我们在使用iptable做面向连接的防火墙时,要允许与一个ip地址建立特定连接,除了让该连接下的包能进来,还要让回复的包能出去,由于ip是个无状态协议,这个时候就需要一个session表来记录有状态的连接,conntrack就是用来记录这些session的。在微服务下,服务间调用频繁,会产生大量DNS查询,Linux默认的conntrack_max很容易突破限制,所以在部署有DNS service的机器上设置一个较高的conntrack_max值基本上是必须的。
前面介绍了我们使用容器来做服务编排,除了这些,相对于传统架构,使用容器我们还获得了一整套日志和监控的解决方案,比如日志采集,部署在容器中的日志可以直接打印到标准输出中,Docker本身支持多种logging driver,可以将日志直接发到Graylog,AWS CloudWatch等日志平台,也可以让Fluentd等日志采集工具来采集Docker默认输出的json-file,相比之下传统架构可能需要在应用中使用专门配置的logger输出到收集系统,或者配置专门的采集器去采集不同的日志文件。
小公司对基础设施的投入不足,一般没有专人去熟悉Kubernetes这种大型开源项目,但即刻算是一个对技术持开放态度,愿意让工程师去踩坑、尝试的公司。相对于采用传统架构,因为容器编排系统都是以提高本身的复杂性来覆盖繁琐的配置和脚本编写工作,本身复杂了就会导致出现问题的时候会比较难排查。但做过运维工作的应该了解,一般自己编写的脚本很难具有通用性,很可能环境稍有改变就不能使用了,运维是比较枯燥的工作,有了编排系统帮助处理这些,我们可以把更多的精力放到更有意义的工作上。

本次培训涉及:DevOps、需要解决的问题、回归、微服务那些事儿、Spring Cloud简介、服务发现 Eureka、客户端负载均衡 Ribbon、声明式的客户端 Feign、使用断路器实现微服务容错 Hystrix、微服务网关 Zuul、统一配置管理 Spring Cloud Config、微服务跟踪 Spring Cloud Sleuth、Spring Cloud常见问题总结等,点击下面图片即可查看具体培训内容。

点击阅读原文链接可直接报名。






