
嵌入式机器视觉为什么重要?
目前深度学习如火如荼,而深度学习中最火的分支又是基于深度学习的机器视觉(computer vision,CV)。近几年机器视觉领域,相对于五年前,可谓有了革命性的发展,各种新应用层出不穷,例如使用人脸识别算法的自动打卡,使用人脸特征点识别算法的美颜相机自拍神器,使用深度神经网络的照片风格变换(如之前时光相册的新海诚风格滤镜等等)。
机器视觉算法的执行可以在云端服务器,也可以在嵌入式终端。在云端服务器执行需要把数据通过网络传到云端再执行算法,适合运算量大,对性能要求高的应用,典型例子包括对精确度要求非常高的人脸识别等等。算法在嵌入式终端执行的应用则适合一些对实时性要求很高的应用,例如驾驶辅助(ADAS)等。对于这些实时性很高的应用,把数据通过网络传到云端执行会带来很高的延迟,无法满足应用的需求。举例来说,在驾驶辅助应用中,一旦发生情况,则系统几毫秒的延迟可能就意味着是否能避免事故,导致完全不同的结果,所以必须在终端执行。另一个例子是无人机,之前大疆发布的Inspire 2无人机就使用了基于Xilinx Zynq SoC方案实现快速目标识别与跟踪,用户在手机app上可以在无人机视野中圈出需要跟踪的物体(人,车,甚至小狗也行),无人机就会跟着目标飞行拍摄,非常酷。无人机目标跟踪也必须使用终端执行的机器视觉算法,因为无人机不可能有良好的网络连接来传递数据,不能指望云端服务器帮忙,只能靠自力更生。
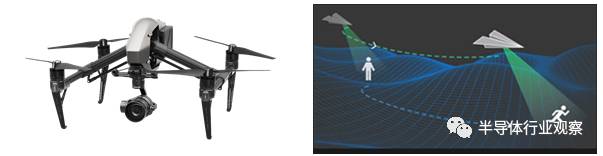
大疆Inspire 2无人机(左)与目标跟踪示意图(右)
随着物联网的兴起,在嵌入式终端执行的机器学习以及机器视觉算法也变得越来越重要。一方面,如前面说的,物联网中很多应用对于实时性要求高,无法在云端执行。另一方面,物联网的总网络带宽有限,每一个节点只能分到很有限的带宽(例如在NB-IoT中每个节点只有180 KHz的带宽),因此不可能把原始数据全部传输到云端。在物联网时代,嵌入式和云端机器视觉算法会结合起来,嵌入式终端完成原始数据的大部分处理,并把少量经过压缩的重要信息通过网络传到云端执行计算量很大或者需要大数据数据库支持的算法。
嵌入式机器视觉硬件的主要玩家
目前,用于云端机器视觉运算的硬件局势非常明朗,基于GPU的分布式运算占据主流位置,FPGA加速器也在获得越来越多地应用(如微软,亚马逊,腾讯和阿里巴巴的数据中心都在积极部署FPGA加速方案),ASIC则仍在探索阶段,只有谷歌在使用自己研发的TPU。
但是,用于执行嵌入式端机器视觉算法的硬件仍然处于起步阶段。嵌入式机器学习硬件需要提供足够的计算能力,并且要求满足非常高能效比,因为嵌入式平台往往使用电池供电,能效比很差的解决方案会导致电池快速耗尽。许多用户仍然在使用传统的嵌入式SoC平台,例如高通Snapdragon平台,甚至Raspberry Pi等更低端的平台执行算法。这些平台往往没有对机器学习算法执行进行过优化,因此执行速度慢,而且功耗不小。Nvidia推出了基于GPU的嵌入式机器学习平台TX系列(近日刚发布了最新的TX2),但是GPU的架构对于嵌入式机器视觉算法的执行并不是最好的架构,因此功耗仍然偏高,能效比偏低,成本也不低。
FPGA方案的优势
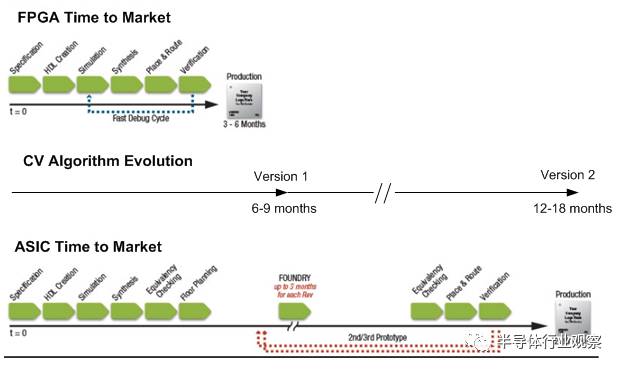
除了传统SoC嵌入式平台和GPU平台外,嵌入式机器视觉硬件解决方案还有ASIC和FPGA两种。就性能和能效比来说,设计得当的ASIC将会是终极解决方案。然而,随着先进工艺节点流片成本越来越高,硬件厂商对于设计制造ASIC往往非常谨慎,因为开一块芯片的成本是以数百万美元计的。另一个问题是,目前对于嵌入式机器学习ASIC的架构还处于研究阶段,并没有一个公认的最优架构。甚至嵌入式机器学习算法本身就处于高速发展阶段,最热门的算法往往过了半年就会被新算法超越很多。而ASIC的开发周期往往是以年为单位计算的,因此选择一种算法并为之而优化ASIC架构的风险很大,很可能等芯片开发完成了算法已经被淘汰了。
这时候,FPGA的灵活性优势就体现出来了。FPGA的开发周期可以短到几个月,因此能跟上算法的进化速度。另外,ASIC开发是一次性的,一旦设计定案了就很难更动,如果需要改动架构就需要再投入一遍数百万的开发资金重新设计流片,但是FPGA要改动架构只需要新的设计完成后重新写入即可,其更动成本相比ASIC来说可以忽略不计。正因为是这样,硬件厂商利用FPGA可以根据自身算法和应用的需求灵活而低成本低风险地定制设计最佳硬件架构,从而实现非常高的性能和非常好的能效比。
另外,FPGA除了灵活性之外,其在架构上也有非常适合深度学习的地方。来自MIT的陈喻新在2016年ISSCC发表的Eyeriss深度学习加速器论文中指出,深度学习加速器最需要优化的地方就在于内存访问,因为机器学习应用中有许多数据实际上是可以复用的,如果有足够多的片上缓存就可以把这些可复用数据放在缓存中随时以较快的速度和较低的能量消耗去访问,而不必存到片外访问速度慢且能量消耗大的DRAM中。基于GPU的方案通过多线程的方式来遮盖内存访问延迟,但是无法减小内存访问的能量消耗。因此,用于嵌入式深度学习硬件需要足够多的片上缓存来减小芯片访问DRAM的频率以及随之而来的能量消耗。与GPU片上缓存较小不同,FPGA用来实现逻辑是基于查找表(LUT),而LUT本身就是一种内存,因此片上的LUT资源既可以用于实现逻辑又可以当内存来用。另外,在Xilinx的FPGA上还有大规模的BRAM用来实现SRAM或者FIFO。因此,FPGA有足够多的片上缓存来减小内存访问来带的能量损耗。例如,在Xilinx的Zynq系列FPGA相比Nvidia同样针对嵌入式应用的TX1,其片上缓存容量多了18倍,从而能实现更高速的计算,但是能量消耗却更小。
最后,目前物联网的兴起除了人们日常能接触到的消费电子相关物联网之外,工业、汽车电子乃至军事应用的物联网也是巨大的市场。这些市场对于芯片有着高于消费电子芯片的标准,一般的硬件厂商,尤其是规模较小的厂商,想要自己开发这些市场的芯片并满足标准非常困难。但是,如果使用FPGA开发,则可以直接买到满足这些标准的FPGA,这就使得小公司也能快速开发针对这些市场的产品。
正是基于这些原因,目前许多针对嵌入式机器视觉硬件市场的公司在使用FPGA来做解决方案,例如之前提到的大疆就使用了Xilinx的FPGA,另外还有许多汽车电子相关的公司在使用FPGA来做辅助驾驶。
然而,之前FPGA虽然相对于传统嵌入式SoC平台和GPU平台有种种性能上的优势,却有一个很大的问题,就是开发环境和生态。传统的FPGA开发需要使用Verilog或者VHDL硬件描述语言去设计,这些语言对于软件开发者来说学习曲线非常不友好,而且就算能掌握这些语言,开发效率也非常低,C语言写10行代码可能这些硬件语言需要写100到1000行等效代码。相对而言,传统嵌入式SoC平台可以使用流行的C或者C++开发,而GPU平台也可以使用C并且调用CUDA库来开发。这就导致嵌入式设计师不太愿意使用FPGA,大家还是倾向于使用开发方便的传统嵌入式SoC或者GPU平台。FPGA开发的人少,社区建设就较弱,开源项目以及代码库也少,这就更进一步减小了其吸引力,大家都不愿意来玩FPGA。这是一个恶性循环,这时候光靠开发者社区是无法打破这个循环的,而是需要业界大公司的支持。Xilinx显然意识到了这一点,因此在去年的时候发布了用于服务器FPGA加速的Reconfigurable Acceleration Stack,而在近日又发布了用于嵌入式平台FPGA加速机器视觉应用的reVISION Stack,给FPGA加速嵌入式机器视觉应用带来了全新生态。
reVISION带来全新生态
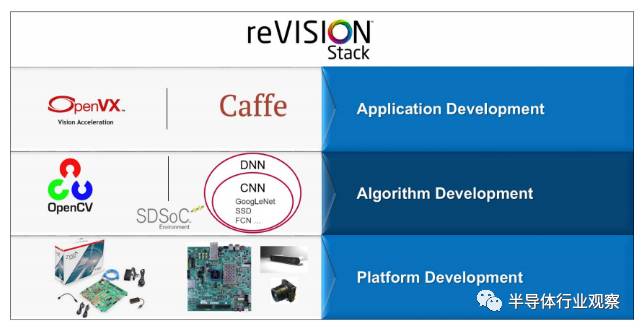
既然用硬件描述语言去编程FPGA很痛苦,那么有没有办法使用C语言之类的高级语言去编程FPGA?这样的工具是有的,就是Xilinx 几年前发布的Vivado HLS (High-Level Synthesis)高层次综合工具,可以直接把C语言自动转换成对应的硬件。然而,HLS仍然需要用户有许多硬件知识,使用起来对于大多数嵌入式开发者并不容易。为此, 一年半前,赛灵思又推出软件定义的SDSoC™ 开发环境,通过提供类似嵌入式 C/C++/OpenCL 应用的开发体验,其中包括简单易用的 Eclipse IDE 和综合设计环境及业界首款 C/C++/OpenCL 全系统优化编译器希望能为更多不熟悉硬件设计语言的嵌入式开发者开启使用FPGA进行设计的门槛, 而且据说也有真的有上千用户通过购买SDSoC 开启了其FPGA设计之旅。然而,面对面对行业对这种全可编程方案的需求, 这上千名新用户远远不是Xilinx 的目标,根据其之前的5年用户5倍增长的蓝图, 其目标是十几万软件和系统级用户,所以其 reVISION Stack的发布是更进类了一步,既然让用户去开发硬件对于用户太痛苦,那么我就帮你把硬件开发好,你直接调用相关硬件就好了,不需要用户任何对于硬件的知识。
详细地说,就是在Xilinx Zynq平台上,Zynq SoC包含了两部分,一部分是ARM核,另一部分是FPGA。在ARM核上可以直接跑C代码(所以做嵌入式开发非常方便),也可以与FPGA一起工作。例如,如果我们把FPGA配置成机器视觉加速器,那么我们就可以通过ARM核上的嵌入式程序在遇到机器视觉计算时调用FPGA上的机器视觉加速器去加速即可。在之前的开发流程中,给Zynq的ARM核写嵌入式程序是相当方便的,调用FPGA也不难,问题是如何把FPGA配置成相应的加速器?这对于不会写硬件描述语言的嵌入式开发者来说太难了。
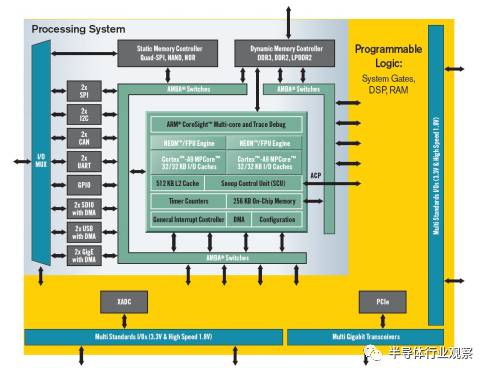
Zynq系列SoC架构图
现在,有了reVISION Stack,整个流程对于嵌入式开发者就方便多了。Xilinx reVISION Stack提供了一系列库函数,嵌入式开发者只要在嵌入式程序中调用了这些库函数,reVISION Stack就会自动在编译过程中把FPGA配置成相应的加速器。对于开发者来说,他看到的只是在Zynq上写程序时调用这些库函数会让应用跑得特别快,至于具体实现细节开发者不需要干预就会自动完成。
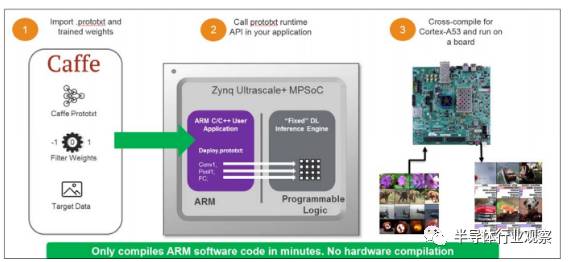
嵌入式开发者调用reVISION Stack实现硬件加速的流程非常方便
目前,reVISION Stack支持流行的Caffe深度学习框架,可以把Caffe中使用的prototxt网络描述文件直接翻译成硬件来实现高效机器视觉应用加速。另外,reVISION Stack对于流行的深度学习网络架构(如GoogleNet,SSD等等)做了进一步优化,这对于目前流行的适用预训练过的网络去做迁移学习来说也是个好消息。除了深度学习之外,reVISION Stack还提供硬件加速过的OpenCV库函数,这对于机器视觉开发者来说也是一件特别方便的事。
从技术上,reVISION Stack在库函数的硬件实现上也下了一番苦功最显著的一点就是Xilinx提供基于8位定点数的推断(Inference)。在今年的ISSCC上,几乎每一篇与机器学习相关的论文都会把数据精度压缩作为一个卖点。一方面,在推断应用上,不需要使用浮点数,而是使用位数较少的定点数也能基本满足应用的需求。另一方面,使用位数较短的定点数不仅可以减小加法器和乘法器的硬件开销,也可以减小对片上缓存容量的压力以及内存带宽的开销(相同的缓存容量如果存储8位定点数,则可以存储的数据量可以4倍于32位浮点数)。Xilinx为了提升8位定点数的计算表现,专门优化了对于定点数的DSP单元映射方法,可以说是跟上了硬件加速的技术趋势。
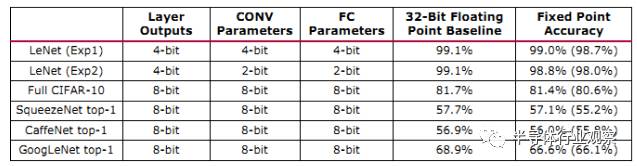
基于以上的硬件优化,以及本身FPGA架构上的优势,Xilinx的数据显示Zynq配合reVISION Stack在GoogleNet Benchmark上可以实现比Nvidia TX1 好6倍的能效比,以及1/5的延迟。在OpenCV benchmark上能实现相对于TX1 42倍的帧率。结合日前Nvidia发布TX2的最新参数(2倍TX1的能效比改善以及2倍TX1的计算能力),Zynq配合reVISION Stack仍然能实现3倍于TX2的能效比改善,以及20倍的帧率。这样的表现,可以说为FPGA在嵌入式机器视觉硬件的竞赛中树立了显著的优势。
结语
随着嵌入式机器视觉应用在未来物联网中越来越重要,FPGA的灵活架构以及海量片上缓存的优势正在慢慢凸现。其开发困难的劣势也在Xilinx以及开发者社区的一起努力下慢慢改善,reVISION Stack正是FPGA在嵌入式机器视觉生态方面的一个巨大进步,相信FPGA以其独特的优势会在未来的嵌入式机器视觉以及机器学习应用中获得越来越多的市场。










