 「每周一起读」是由 PaperWeekly 发起的协同阅读小组。我们每周精选一篇优质好文,利用在线协同工具进行精读并发起讨论,在碎片化时代坚持深度阅读。
「每周一起读」是由 PaperWeekly 发起的协同阅读小组。我们每周精选一篇优质好文,利用在线协同工具进行精读并发起讨论,在碎片化时代坚持深度阅读。
从本周起,PaperWeekly 的
多模态小组
将开始发起
「每周一起读」
活动,我们将每周选定一篇优质文章,并提供可撰写读书笔记和在线协同讨论的阅读工具。如果你也希望和我们一起培养良好的阅读习惯,在积极活跃的讨论氛围中增长姿势,就请留意下方的招募信息吧:)
本期
「每周一起读」
,我们将一起精读下文并发起协同交流。参与者需具备
多模态(Image Capiton/VQA)
方向的研究背景,活动细则详见文末。
An Empirical Study of Language CNN for Image Captioning
文章来源:
https://arxiv.org/abs/1612.07086
推荐理由:
本篇论文提出了用 CNN 模型来对单词序列进行表达,该 CNN 的输入为之前时刻的所有单词,进而可以抓住对生成描述很重要的历史信息。其中总体架构如下图所示:
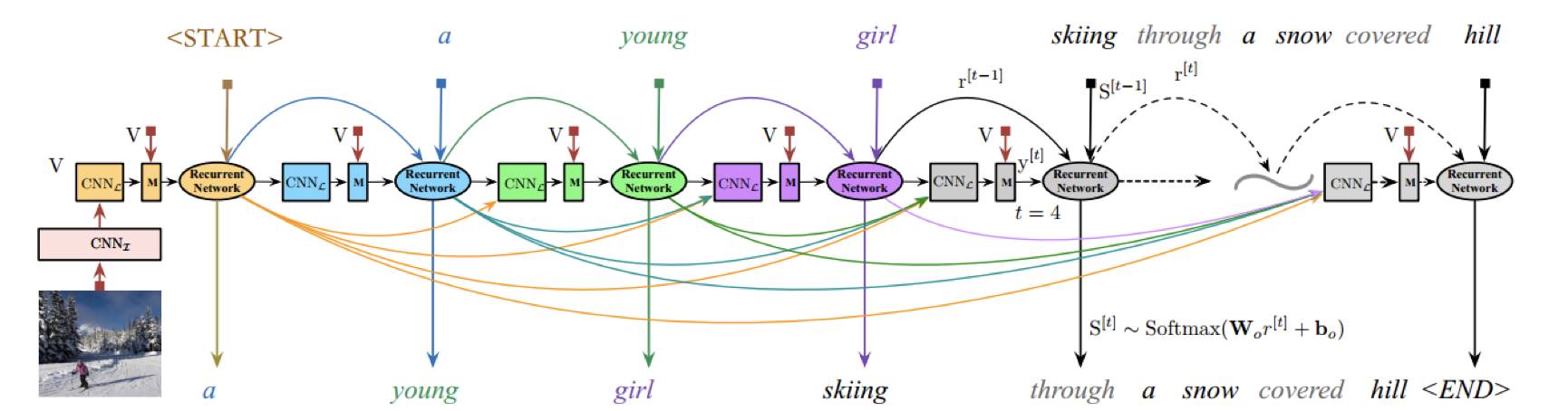
该模型主要由四部分组成,用于图像特征提取的 CNN_I,用于自然语言建模的 CNN_L,用于结合 CNN_I 和 CNN_L 信息的多模态层 M,和一个用于单词序列预测的递归神经网络。

总体过程如下:首先利用 CNN_I 提取图像特征,然后 CNN_L 利用之前时刻生成的单词对当前的单词信息进行表达,然后通过多模态层结合图像和单词信息,最后将融合的信息作为递归神经网络的输入来预测一下时刻的单词.该文与之前通过 one-hot 向量,然后经过词嵌入提取词向量的表达方法不同,利用了 CNN 网络来表达单词信息,进而能够很好的抓住过去的历史信息,用于指导当前时刻单词的生成。
1. 参与者需具备
多模态(Image Capiton/VQA)
方向的研究背景。
2.
扫描下方二维码添加主持人微信,注明
“多模态”
,报名截止时间为 4 月 19 日(本周三) 20:00。

关于PaperWeekly
PaperWeekly 是一个分享知识和交流学问的学术组织,关注的领域是 NLP 的各个方向。如果你也经常读 paper,喜欢分享知识,喜欢和大家一起讨论和学习的话,请速速来加入我们吧。
关注微博: @PaperWeekly
微信交流群: 后台回复“加群”





