作者 | Ben Hoyt
翻译 |
雁惊寒
“
pygit是一个大约500行Python代码工具,实现了一些git功能,包括创建库、将文件添加到索引、提交、将自身推送到GitHub上去。 本文给出了一些代码编写过程,并详细介绍了相关代码。
”
Git因其具有非常简单的对象模型而着称。在学习git时,我发现本地对象数据库只是.git目录中的一堆普通文件。除了索引(.git/index)和打包文件(可有可无)外,这些文件的存放规则和格式相当的简单。
受Mary Rose Cook的程序启发,我也想看看是否能够编写出创建仓库,执行提交,并推送到服务器(比如GitHub)的git客户端。
Mary的gitlet程序有着很多可供学习的地方,而我的程序需要把自身推送到GitHub上去,所以具有更多的创新功能。在某些方面,她实现了更多的Git功能(包括基本的合并),但在其他方面实现的功能就比较的少。例如,她使用了一个简单的基于文本的索引格式,而不是用git使用的二进制格式。此外,虽然她的gitlet支持推送,但它只会推送到本地已经存在的仓库中,而不是到远程服务器上。
对于本文涉及的这个练习,我打算编写一个可以执行所有步骤的版本,包括推送到一个真正的Git服务器上去。我也会使用与git相同的二进制索引格式,这样,我就可以在每一步骤上都使用git命令来检查程序的功能。
我的程序叫pygit,用Python(3.5+)编写,并且只使用了标准库模块。它只有500行代码,包括空白行和注释。我至少需要实现init、add、commit和push命令,但pygit还实现了status,diff,cat-file,ls-files和hash-object等命令。后面的命令,本身也非常有用,并且在调试pygit的时候,也起到了帮助作用。
下面,让我们来看看代码吧!您可以在
GitHub
上查看pygit.py的所有代码,或者在下文中跟着我一起浏览各段代码。
初始化仓库
初始化本地Git仓库只需要创建.git目录以及目录下的几个文件和子目录即可。在定义了read_file和write_file这两个帮助函数之后,我们就可以编写init()了:

你可能注意到这段代码里没有进行优雅的错误处理。毕竟这整个代码只有500行啊。如果仓库目录已经存在,程序会终止,并抛出traceback。
取对象的散列值
hash_object函数用来获取单个文件对象的散列值,并写入.git/objects目录下的“数据库”中。在Git模型中,包含三种对象,分别是:普通文件(blob),提交(commit)和树(tree,也就是目录结构)。
每个对象都有一个文件头,包括文件类型和文件大小,大概几个字节的长度。之后是NUL字符,然后是文件的数据内容。所有这些都使用zlib压缩并写入到文件.git/objects/ab/cd…中,其中ab是40个字符长的SHA-1散列的前两个字符,而cd…则是剩余的部分。
请注意,这里使用了Python标准库(os和hashlib)。

还有个find_object()函数,它通过散列(或散列前缀)找到某个文件对象,然后用read_object()函数读取这个对象及其类型。这实际上是hash_object()的反向操作。最后,cat_file是一个与git cat-file具有相同功能的pygit函数:它将对象的内容(或者大小和类型)进行格式化并打印到标准输出。
git索引
接下来我们要做的事情就是要将文件添加到索引或暂存区中。索引就是文件列表,按路径名排序,每个路径都包含路径名,修改时间,SHA-1散列等等。需要注意的是,索引列出了当前树中的所有文件,而不仅仅是在暂存区中等待提交的文件。
索引以自定义的二进制格式存储在.git/index文件中。这个文件虽然并不是很复杂,但它还是涉及到了结构体的用法,通过一定规则的字节偏移,可以在长度可变的路径名称字段之后获得下一个索引条目。
文件的前12个字节是文件头,最后20个字节是索引的SHA-1散列,在这中间的字节是索引条目,每个索引条目为62个字节加上路径的长度再加上填充的长度。下面是namedtuple类型的IndexEntry和read_index函数:

这个函数后面是ls_files,status和diff函数,这些是打印索引状态的几个不同的方法:
-
ls_files函数只是打印索引中的所有文件(如果指定了-s,则连同一起打印它们的模式和散列)
-
status函数使用get_status()来比较索引中的文件和当前目录树中的文件是否一致,打印有哪些文件被修改,新增或删除
-
diff函数打印每个修改过的文件中变动的地方,显示索引中的内容与当前工作副本中的内容的不同点(使用Python的difflib模块来完成这个功能)
git对索引的操作和这些命令的执行在效率上比我这个程序要高很多。我使用os.walk()函数来列出目录中的所有文件的完整路径,做一些设置操作,然后比较他们散列值。例如,这个是我用来获取有过修改的路径列表的代码:

最后还有一个write_index函数用于回写索引。它调用了add()函数将一个或多个路径添加到索引中。add()函数首先读取整个索引,将路径添加进去,然后重新排序并回写索引。
此时,我们已经将文件添加到索引中了,下面,我们可以开始实现commit操作了。
提交
执行提交操作需要编写两个对象:
首先是树对象,它是提交时当前目录(或者是索引)的一个快照。这棵树递归列出了目录中的文件和子目录的散列。
所以每个提交都是整个目录树的快照。 这种使用散列值来存储东西的好处是,如果树中的任意一个文件发生改变,则整个树的散列也会跟着发生改变。相反,如果一个文件或子目录没有改变,则散列也不会改变。所以你可以高效地存储目录树中的变更。
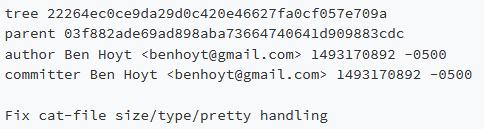
这是一个用cat-file pretty 2226命令打印出来的树对象的示例(每一行打印的内容为:文件模式、对象类型、散列和文件名):

函数write_tree用于写树对象。Git文件格式的奇怪之处在于它混合了二进制和文本,例如,树对象中的每一“行”首先是文本:“模式、空格、路径”,然后是NUL字节,然后是二进制SHA-1散列。 这是我们的write_tree()函数:

其次是提交对象。 它记录了树的散列值、父提交、作者、时间戳,以及提交信息。合并功能是Git的优点之一,但是pygit只支持单一的线性分支,所以只有一个父提交(如果是第一次提交,则没有父提交)。
这是一个提交对象的例子,再次使用cat-file pretty aa8d命令打印出来:
这个是我们的提交函数,再次感谢Git的对象模型,相当的简单:

与服务器交互
接下来是稍微有点困难的部分了,因为我们要让pygit与一个真正的Git服务器进行通信(我将把pygit自身推送到GitHub,但它也适用于Bitbucket和其他服务器)。
其基本思想是首先查询服务器上即将要提交的主分支,然后确定等待提交的本地对象集,最后,更新远程的提交散列值,并发送包含所有缺少的对象的“打包文件”。
这被称为“智能协议”。直到2011年,GitHub才
停止了对“愚蠢”传输协议的支持
,该协议是将.git目录中的文件直接传输过去,所以实现起来更加容易。这里,我们必须得使用“智能协议”将对象打包到一个文件中。
在最后的工作阶段,我使用了Python的
http.server
模块实现了一个小型的HTTP服务器,这样,我就可以运行其他的git客户端与这个服务器进行交互,以此来查看真正的请求与相应数据。
pkt-line格式
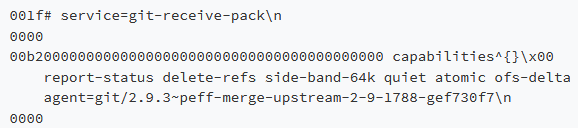
传输协议的关键部分之一是“pkt-line”格式,它是用于发送元数据(如提交散列)的数据报文格式。报文的开头是长度值。每“行”开头是4个十六进制字符表示的长度值(所表示的长度要包含这个长度值字段),所以,包的长度必须小于这4个字符表示的数值。 每行的最后都有一个LF字符。数据结尾的0000是段结束标记。
例如,这个是GitHub对git-receive-pack GET请求的响应报文。请注意,额外的换行符和缩进并不是报文的一部分。
很明显,我们需要两个转换函数:一个将pkt-line数据转换为一行一行的数据,另一个则是反过来,将一行一行的数据转换为pkt-line格式:

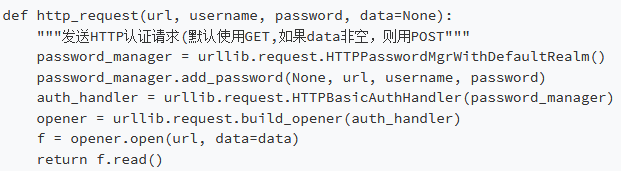
实现HTTPS请求
由于我只想使用标准库, 所以接下来的代码就是在不使用
requests
库的情况下实现身份验证HTTPS请求:
以上这段代码说明了requests库的存在是非常有意义的。你可以使用标准库的urllib.request模块来实现这些操作,但有时候会很痛苦。大多数Python标准库是很好用的,有一些则不是,虽然数量并不多。如果使用request的话,甚至都不需要帮助函数:

我们可以使用上面的函数来向服务器询问它的主分支到哪个版本了,代码如下(这个功能还比较脆弱,但是可以很容易地修改的更为通用一点):

确定丢失的对象
接下来,我们需要确定:服务器需要,但是在服务器上又不存在的对象。 pygit假定所有东西都在本地(它不支持“pulling”),所以,我写了read_tree函数(与write_tree相反),然后,用以下这两个函数在指定的树和指定的提交中递归寻找对象散列集合:

然后,我们需要做的就是获取本地提交引用的对象集合,用这个集合减去远程提交中引用的对象集。这两者的差异是远端丢失的对象。虽然肯定还有更加有效率的方式来生成这个对象集合,但这个逻辑对于pygit来说已经足够了:

推送自身
在推送之前,我们需要发送一条pkt-line请求来说明“将主分支更新为此提交散列”,然后发送包含上述所有缺失对象的打包文件。
打包文件有一个12个字节长的头(从PACK开始),接着是各个对象,每个对象包括长度以及用zlib算法压缩的对象数据,最后是整个打包文件的散列值,长度是20个字节。虽然,基于对象差异的算法可以让数据报文来得更小,但对我们而言就是过度设计了:

然后,最后一步,push()自身,为了简洁起见,我删除了一点代码:

命令行解析
pygit,包括子命令(pygit init,pygit commit等),是一个使用标准库
argparse
模块的例子。我没有把代码复制到这里,你可以查看源代码中
argparse
的相关部分。
pygit用法
在大多数地方,我尽量让pygit命令行语法与git语法相同或接近相同。以下是将pygit提交到GitHub的命令:

结束语
这些就是所有的代码逻辑了!如果你从头阅读到这里,那你仅仅只是浏览了500行Python代码,并没有任何价值。哦,等等,除了受到教育和工匠精神的价值。希望你学到了有关Git内部逻辑方面的知识。





