当获得一份数据集时,你会怎么做?
立马撩起袖管进行分析么?这不是一个好建议。无数的经验告诉我们,如果分析师不先行了解数据集的质量,后续的推断分析是事倍功半的。
正确的处理方法是先使用描述统计。
什么是描述统计学
它是一种综合概括数据集的方式,包括数据的加工和显示,数据集的分布特征等。它与推断统计相呼应。
在进入统计学习前,先明确基础概念。
数据可以分为分类型数据和数值型数据。分类型数据是识别变量的类型,比如男女、地区、各种类别;数值型数据是表示数值的大小和多少,比如年龄中的18、19、20岁。
最明显的区分是,分类型数据不能使用加减法,而数值型数据可以。两者在一定程度可以互相转换。比如年龄,18岁是数值型数据,但它也可以转换成分类数据「青少年」。我们也能用数值表示分类数据,比如0代表女,1代表男,它依旧没有计算意义,更多是方便计算机存储而已。
分类数据和数值数据的具体应用,会在往后的学习中继续深入,本文先将主要精力放在数值型数据。
数据的度量
平均数是一种数据位置的度量,用以了解整体数据,这是小学就学到的内容。可是平均数并不是一个权威的衡量指标,当我们提到全国平均工资的时候,我们都是被马云爸爸王健林爸爸平均的普通人。
平均数容易受到极值的影响,因为数据集并不能保证「干净」,各类运营数据经常受到扰动,比如薅羊毛党就会拉高营销活动的平均值。一般而言,可以用调整平均数(trimmed mean)消除异常波动,在数据集中删除一定比例的极大值和极小值,比如5%,然后重新计算平均数。
它既然不靠谱,我们便请出中位数。将所有数据按升序排列后,位于中间的数值即中位数。当数据集是奇数,中位数是中间的数值,当数据集是偶数,中位数是中间两个数的平均值。这也是小学的内容。
另外一种度量是众数,它是数据集出现频次最多的数据,当有多个众数时,称为多众数。众数使用的频率低于前两者,更多用于分类数据。
平均数、中位数、众数构成了标准的衡量方法。但是还不够。
数据分析师常将数据划分为四个部分,每一部分包含25%的数据集,划分的分割点叫做四分位数。
依次将数据升序排列,位于第25%位置的叫做第一四分位数Q1,位于第50%位置的叫做第二四分位数Q2,即中位数,位于第75%的叫做第三分位数Q3。这三个点,能辅助衡量数据的分布状态。
数据的离散和变异
我们考虑一个新的问题,现在一家电商公司要卖两个同类型的商品,它们的一周销量(单位:个)如下:
商品A:10,10,10,11,12,12,12
商品B:3,5,6,11,16,17,19
它们的平均数一样,中位数也一样,可它们的真实情况呢?当然不。作为商品,我们更喜欢销量稳定的。
方差是一种可以衡量数据「稳定性」的度量,更通俗的解释是衡量数据的变异性,从图形上说,也叫离散程度。
方差的计算公式是各个数据分别与其平均数之差的平方和的平均数。
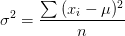
上述公式是总体数据集的方差计算,当数据近为部分抽样样本时,n应该改为n-1。数据集足够大时,两者的误差也可以忽略不计。
现在计算上文商品的方差。Excel中的方差公式为VARP( ),如果是样本数据,则为VAR( )。不同Excel版本,函数会有微小差异。
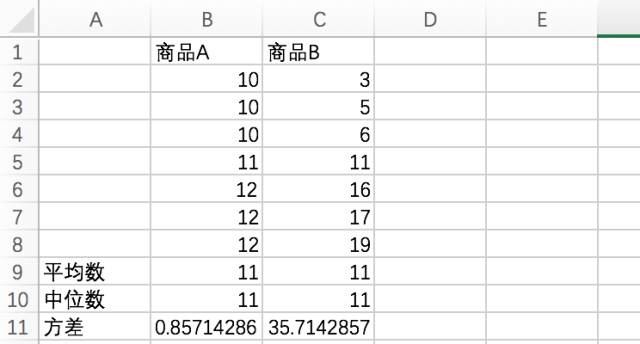
方差越大,说明数据集的离散程度越大,商品A的销量波动明显比商品B稳定。方差的计算中,因为涉及到了平方和,所以单位的量纲是平方(商品A和B的方差,单位为个^2),它很难有直观的诠释。于是我们又引入标准差。
标准差是方差的开平方:
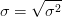
Excel中,标准差的计算函数为stdevp( ),如果是样本数据,则为stdev( )。
方差和标准差的意义是相同的,但是标准差与原始数据的单位量纲相同,它更容易与平均数等度量比较。比如商品A的平均销量为11个,标准差为0.85个,于是我们知道这个商品卖的比较稳。
切比雪夫定理指出,至少有75%的数据值与平均数的距离在2个标准差以内,至少有89%的数据与平均数在3个标准差之内,至少有94%的数据与平均数在4个标准差以内。这是一个非常方便的定理,能快速掌握数据包含的范围。
假设上海地区的平均薪资是20k,标准差是5K,那么大约有90%的薪资,都在5k~35k的区间内。
如果数据本身符合正态(钟形)分布,那么切比雪夫定理的估算将进一步准确:68%的数据落在距离平均数一个标准差内,95%的数据值落在距离平均数2个标准差之内,几乎所有的数据落在三个标准差内。
在Excel中,有一个重要的工具叫数据分析库(部分Excel版本需要安装,自行搜索),里面封装了大量的统计工具。
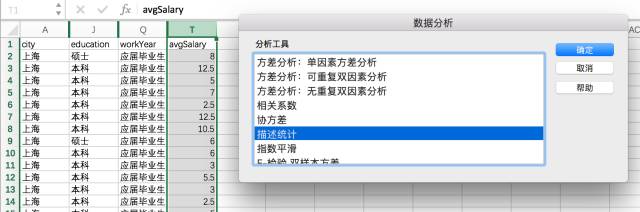
点击描述统计,选择需要计算的区域,设置为逐列,输出区域选择旁边U2区块。输出计算结果。










