七夜
,
Python
中文社区专栏作者,信息安全研究人员,比较擅长网络安全、逆向工程、
Python
爬虫开发、
Python Web
开发。
《Python爬虫开发与项目实战》
作者。
这次分享的文章是我的新书《Python爬虫开发与项目实战》基础篇-第七章的内容,关于如何手工打造简单分布式爬虫 (如果大家对这本书感兴趣的话,可以看一下 试读样章:
http://pan.baidu.com/s/1hrWEOYg
),下面是文章的具体内容。
本章讲的依旧是实战项目,实战内容是打造分布式爬虫,这对初学者来说,是一个不小的挑战,也是一次有意义的尝试。这次打造的分布式爬虫采用比较简单的主从模式,完全手工打造,不使用成熟框架,基本上涵盖了前六章的主要知识点,其中涉及分布式的知识点是分布式进程和进程间通信的内容,算是对Python爬虫基础篇的总结。
现在大型的爬虫系统都是采取分布式爬取结构,通过此次实战项目,让大家对分布式爬虫有一个比较清晰地了解,为之后系统的讲解分布式爬虫打下基础,其实它并没有多么困难。实战目标:爬取2000个百度百科网络爬虫词条以及相关词条的标题、摘要和链接等信息,采用分布式结构改写第六章的基础爬虫,使功能更加强大。爬取页面如下所示。
7.1简单分布式爬虫结构
本次分布式爬虫采用主从模式。主从模式是指由一台主机作为控制节点负责所有运行网络爬虫的主机进行管理,爬虫只需要从控制节点那里接收任务,并把新生成任务提交给控制节点就可以了,在这个过程中不必与其他爬虫通信,这种方式实现简单利于管理。而控制节点则需要与所有爬虫进行通信,因此可以看到主从模式是有缺陷的,控制节点会成为整个系统的瓶颈,容易导致整个分布式网络爬虫系统性能下降。
此次使用三台主机进行分布式爬取,一台主机作为控制节点,另外两台主机作为爬虫节点。爬虫结构如图7.1所示:
图7.1 主从爬虫结构
7.2控制节点ControlNode
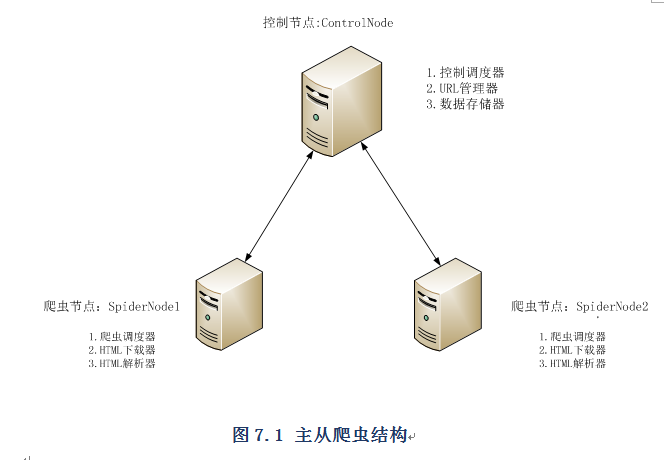
控制节点主要分为URL管理器、数据存储器和控制调度器。控制调度器通过三个进程来协调URL管理器和数据存储器的工作,一个是URL管理进程,负责URL的管理和将URL传递给爬虫节点,一个是数据提取进程,负责读取爬虫节点返回的数据,将返回数据中的URL交给URL管理进程,将标题和摘要等数据交给数据存储进程,最后一个是数据存储进程,负责将数据提取进程中提交的数据进行本地存储。执行流程如图7.2所示:
图7.2 控制节点执行流程
7.2.1URL管理器
URL管理器查考第六章的代码,做了一些优化修改。由于我们采用set内存去重的方式,如果直接存储大量的URL链接,尤其是URL链接很长的时候,很容易造成内存溢出,所以我们采用将爬取过的URL进行MD5处理,由于字符串经过MD5处理后的信息摘要长度可以128bit,将生成的MD5摘要存储到set后,可以减少好几倍的内存消耗,Python中的MD5算法生成的是32位的字符串,由于我们爬取的url较少,md5冲突不大,完全可以取中间的16位字符串,即16位MD5加密。同时添加了save_progress和load_progress方法进行序列化的操作,将未爬取URL集合和已爬取的URL集合序列化到本地,保存当前的进度,以便下次恢复状态。URL管理器URLManager.py代码如下:
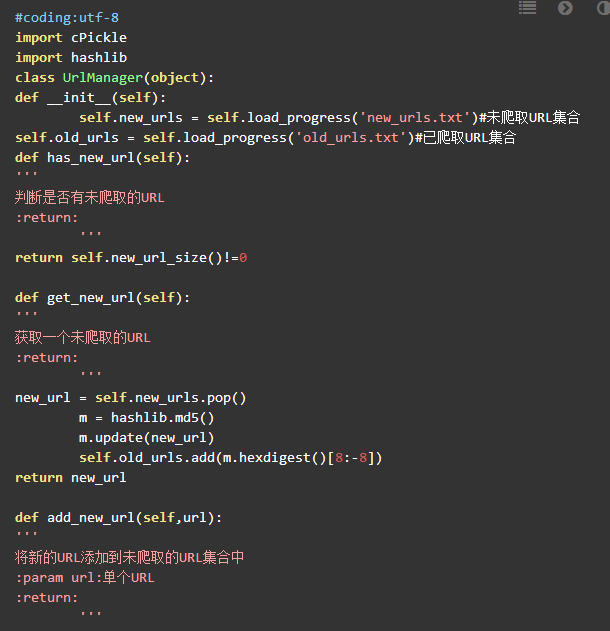
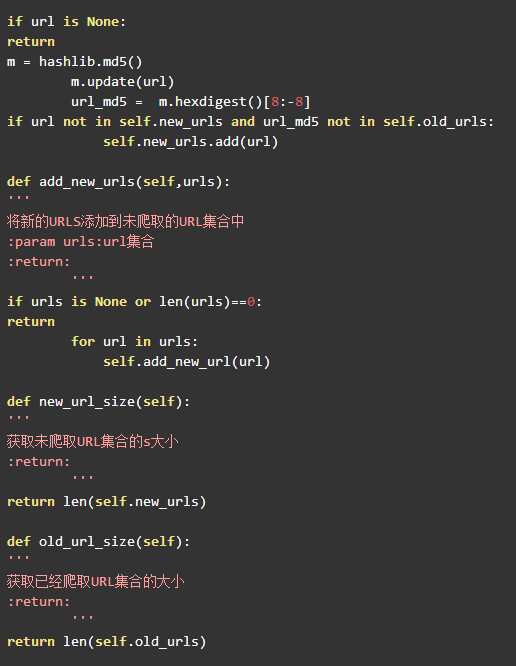
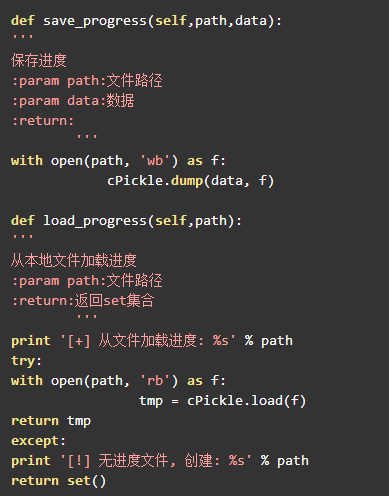
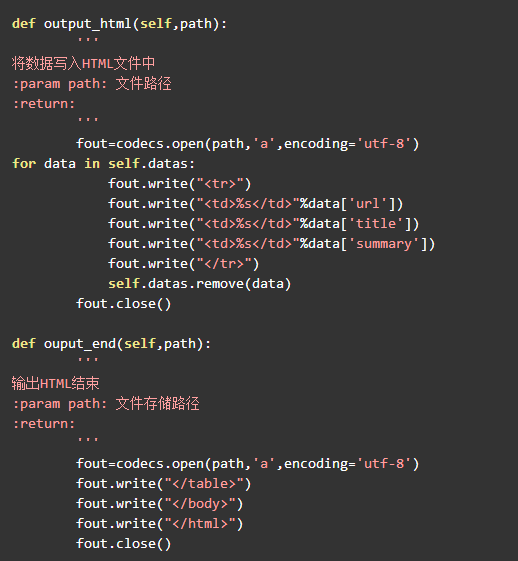
7.2.2数据存储器
数据存储器的内容基本上和第六章的一样,不过生成文件按照当前时间进行命名避免重复,同时对文件进行缓存写入。代码如下:
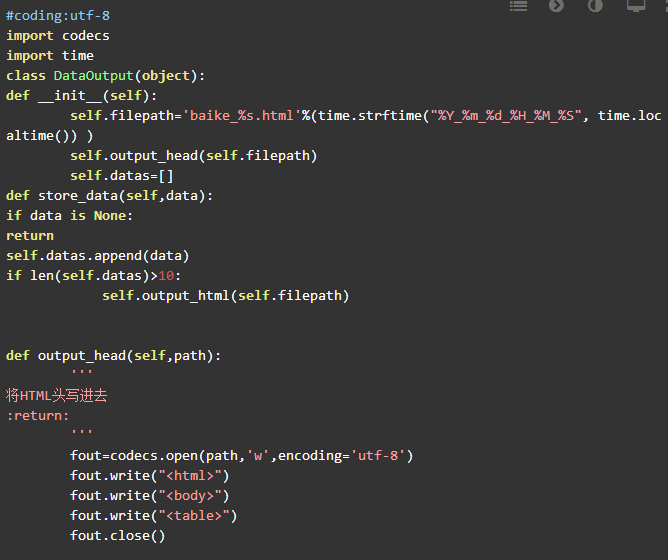
7.2.3控制调度器
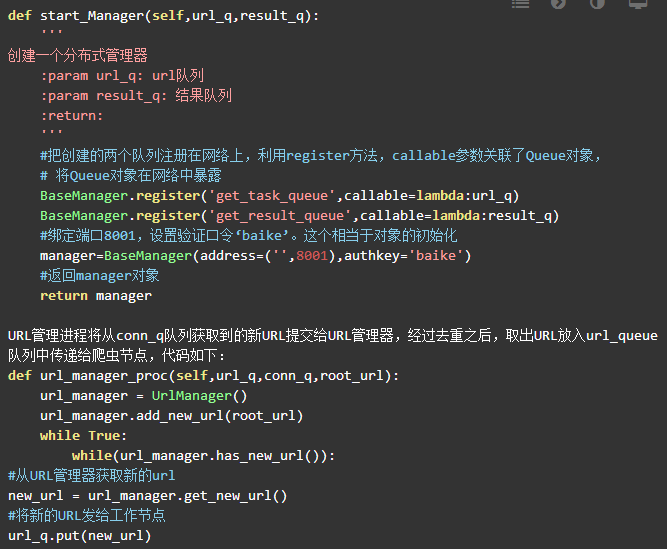
控制调度器主要是产生并启动URL管理进程、数据提取进程和数据存储进程,同时维护4个队列保持进程间的通信,分别为url_queue,result_queue,conn_q,store_q。4个队列说明如下:
url_q队列是URL管理进程将URL传递给爬虫节点的通道
result_q队列是爬虫节点将数据返回给数据提取进程的通道
conn_q队列是数据提取进程将新的URL数据提交给URL管理进程的通道
store_q队列是数据提取进程将获取到的数据交给数据存储进程的通道
因为要和工作节点进行通信,所以分布式进程必不可少。参考1.4.4小节分布式进程中服务进程中的代码(linux版),创建一个分布式管理器,定义为start_manager方法。方法代码如下:
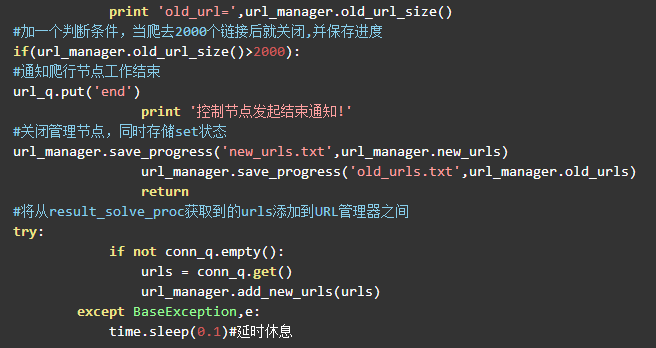
数据提取进程从result_queue队列读取返回的数据,并将数据中的URL添加到conn_q队列交给URL管理进程,将数据中的文章标题和摘要添加到store_q队列交给数据存储进程。代码如下:

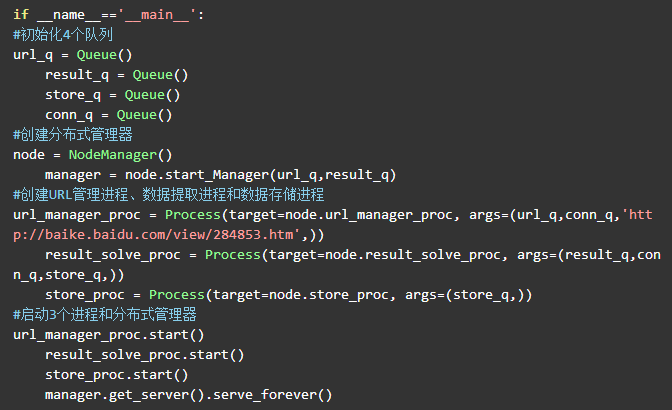
最后将分布式管理器、URL管理进程、数据提取进程和数据存储进程进行启动,并初始化4个队列。代码如下:
7.3爬虫节点SpiderNode
爬虫节点相对简单,主要包含HTML下载器、HTML解析器和爬虫调度器。执行流程如下:
爬虫调度器从控制节点中的url_q队列读取URL
爬虫调度器调用HTML下载器、HTML解析器获取网页中新的URL和标题摘要
最后爬虫调度器将新的URL和标题摘要传入result_q队列交给控制节点
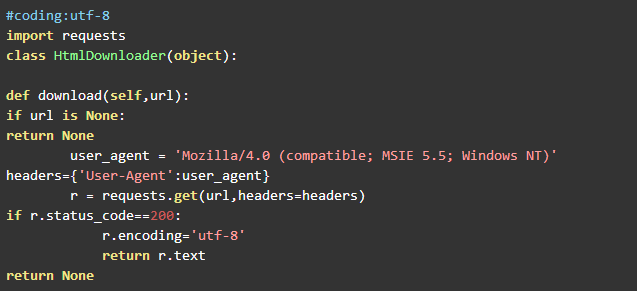
7.3.1HTML下载器
HTML下载器的代码和第六章的一致,只要注意网页编码即可。代码如下:
7.3.2HTML解析器
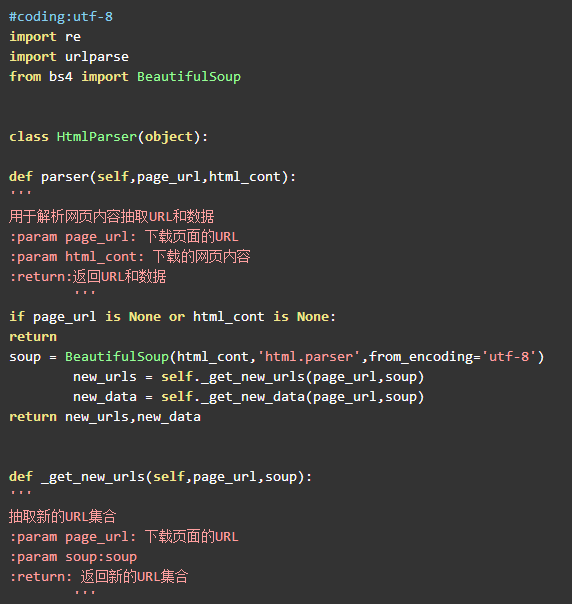
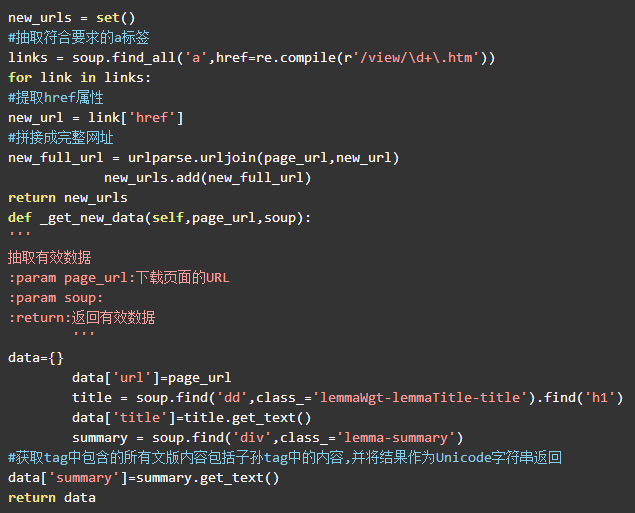
HTML解析器的代码和第六章的一致,详细的网页分析过程可以回顾第六章。代码如下:
7.3.3爬虫调度器
爬虫调度器需要用到分布式进程中工作进程的代码,具体内容可以参考第一章的分布式进程章节。爬虫调度器需要先连接上控制节点,然后依次完成从url_q队列中获取URL,下载并解析网页,将获取的数据交给result_q队列,返回给控制节点等各项任务,代码如下:
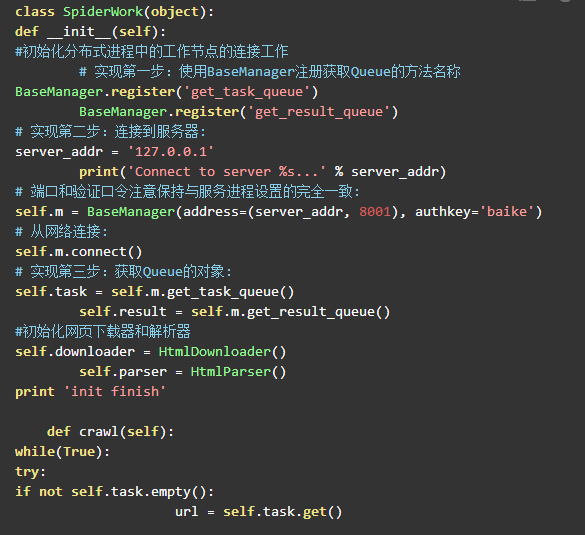
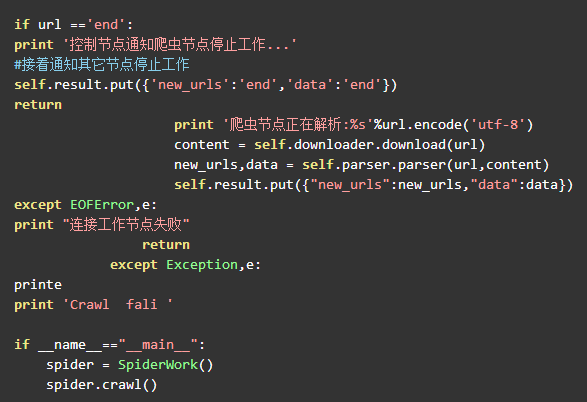
在爬虫调度器设置了一个本地IP:127.0.0.1,大家可以将在一台机器上测试代码的正确性。当然也可以使用三台VPS服务器,两台运行爬虫节点程序,将IP改为控制节点主机的公网IP,一台运行控制节点程序,进行分布式爬取,这样更贴近真实的爬取环境。下面图7.3为最终爬取的数据,图7.4为new_urls.txt内容,图7.5为old_urls.txt内容,大家可以进行对比测试,这个简单的分布式爬虫还有很大发挥的空间,希望大家发挥自己的聪明才智进一步完善。