编者按:昨天,在我们的文章《
机器语法纠错能力新突破,微软小英变身英语写作老师
》中,为大家介绍了微软小英最新上线的“作文打分”新功能,以及这一功能背后的最新研究突破。今天,微软亚洲研究院研究员葛涛将为大家从技术角度解读机器自动语法改错的最新研究成果。
机器自动语法改错
是自然语言处理领域的一个经典问题,也是近年来快速发展的一个研究方向,有着广泛的实际应用需求。随着相关数据集规模的逐渐增大以及深度学习技术的不断成熟,越来越多的学者开始研究利用
seq2seq
模型进行自动语法改错。
对于一个用于语法改错任务的
seq2seq
模型,其
基本的训练数据为一个由原始句子和正确句子所组成的改错句对
,如图
1(a)
所示。从理论上讲,只要有大量的训练数据,我们是能够得到一个相对完美的语法改错模型。然而实际上,这种
改错句对的数量规模相当有限
。因此,
在训练数据并不充足的情况下,
seq2seq
模型的泛化能力就会受到影响
,其导致的一个结果就是哪怕输入的句子稍稍变动一点,模型也可能会无法将其完全改正,如图
1(b)
所示。与此同时,我们还发现,
对于一个含有多个语法错误的句子,单次的
seq2seq
推断往往不能完全将其改正
,在这种情况下,我们可能需要用多轮
seq2seq
推断来对一个句子反复进行修改,如图
1(c)
所示。

图1
基于以上的几点想法,我们在传统
seq2seq
模型的基础上提出了
一种全新的
学习和推断机制
——
fluency boost learning and inference
,如图
2(a)
所示。
流畅度提升学习(
fluency boost learning
)的核心原理就是在训练模型的过程中,让
seq2seq
模型生成出多个结果
,然后将结果中流畅度不如目标端正确句子的生成句子和目标端正确句子配对,组成全新的流畅提升句对,作为下一轮训练的训练数据。
而
流畅度提升推断(
fluency boost inference
)则是利用
seq2seq
模型对句子进行多轮修改,直到句子的流畅度不再提升为止
。这种多轮修改的策略能够率先改掉句子的一部分语法错误,从而使句子的上下文更加清晰,有助于模型修改剩下的错误。

图
2
流畅度提升学习
(a)
与推断
(b)
对于语法改错任务来说,
一个合格的训练样本通常需要满足两个要求
:
(1)
源端句子和目标端句子的语义应当是一致的
,因为我们不希望修改过的句子改变原意;
(2)
目标端句子的流畅度能够得到提升
,这一点其实也是语法改错任务的终极目标。
而流畅度提升学习所生成出的流畅提升句对恰恰能够很好地满足上面的两个条件
。首先,由于我们的seq2seq模型是用改错句对作为训练数据训练得到的,所以流畅度提升学习所创造出的句对通常不会改变句子原意,在模型相对稳定后,n-best结果中的句子与原句通常只有1到2个词的差别,很少会改变句子原意;其次,我们所生成的流畅提升句对能够保证目标端的句子比源端句子有更高的流畅度。
在这个工作中,
我们用
f(x)
来定义句子的流畅度:
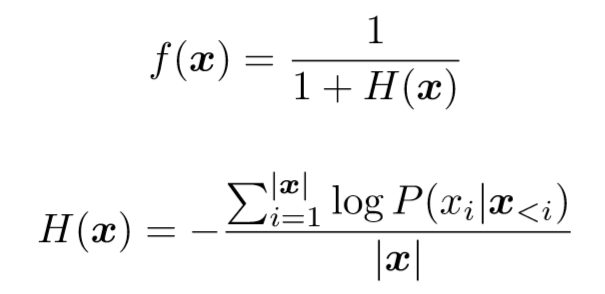
上式中
P(x
i
|x
)
为给定上文
x
,
P(x
i
)
的语言模型概率。
H(x)
实质上为句子
x
的交叉熵,其取值范围为
[0,+
∞
)
,因此
f(
x
)
取值范围为
(0,1]
。
图
3
流畅度提升学习
其实通过
数据增强(
data augmentation
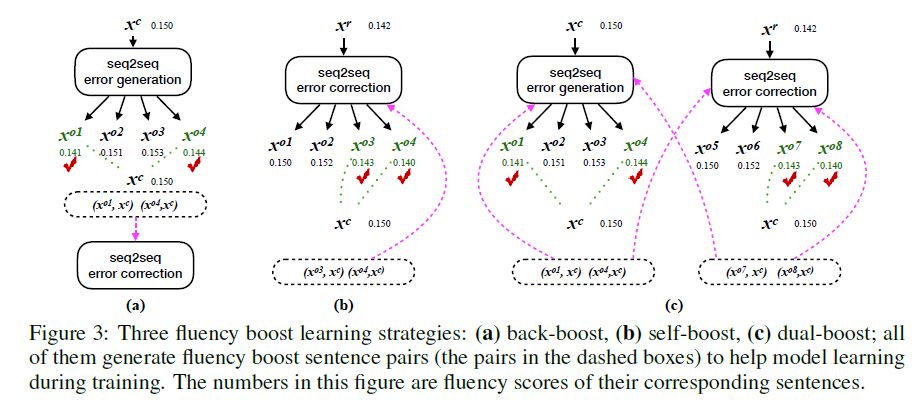
)方法来扩充训练集的做法以前就有研究者提出过,在
神经网络机器翻译领域
比较有代表性的工作就是
Sennrich
等人在
ACL 2016
上提出的
back-translation
方法(图
3a
),利用反转训练数据的源端和目标端来训练一个专门用来生成错误句子的模型。而我们的方法则是通过改错模型自身生成的
n-best
来作为错误句子
(
图
3b)
。
为了区分这两种不同的方法,我们
将利用
back-translation
来生成
流畅提升句对
的方法称之为
back-boost learning
,而
将利用改错模型自身来生成流畅句对的方法称为
self-boost learning
。对于
self-boost learning
,在不同的训练阶段,模型的不断迭代更新会导致对同一句子前后生成出的
n-best
也会不同,所以模型生成出的含有错误的句子更加多样化。
由于
back-boost
和
self-boost
是从完全不同的两个角度来生成流畅提升句对,这就意味着这两种方法能够互相补充、互相增强。因此,我们进一步将两种方法结合在一起,产生了最终的
dual-boost learning
方法。
Dual-boost learning
能够让
back-boost
和
self-boost learning
各自生成出流畅提升句对(如图
3c
)。
生成出的句对不仅可以帮助训练改错模型,让改错模型从更多的样例中知道如何去改正一个句子,反过来也可以帮助训练错误生成模型来生成更多样化的含有错误的句子
。
值得一提的是,我们的流畅度提升学习的方法也可以应用在大量的正确文本上。因为一个正确的句子可以看成是一个源端和目标端相同的改错句对,
将
流畅度提升学习
应用到正确文本可以帮助我们极大地扩充训练数据的规模以及内容多样性
。
流畅度提升推断利用了语法改错这个任务的特殊性——输入输出本质上是相同的,因此我们可以将输出的结果句子作为输入进行再修改。在多轮
seq2seq
推断的基础上,我们进一步提出了一种更加有效的方法——往返修改。
往返修改是指利用一个反向(右到左)解码器和一个正向(左到右)解码器交替地对一个句子进行修改
。因为正向和反向解码器对于不同的错误有着各自的优势,往返修改能够让这两个模型能够充分发挥自己的优势。

图
4
往返修改
例如上图中的句子,用反向模型能够很容易地把冠词错误改正,这是因为冠词错误的修正更加依赖于冠词位置右边的上下文。但是反向模型在检测主谓一致这种错误类型时会
存在一些劣势
,因为主致一致错误的改正往往需要依赖位于谓语动词左边的主语的人称和单复数。而这一类型的错误又可以被正向模型发现并改正。
我们
利用
Lang-8
、
CLC
、
NUCLE
这几个知名的语法改错数据集以及额外从
Lang-8
收集到的
287
万训练句对作为原始训练数据
。我们的基本
seq2seq
模型是一个
7
层卷积
seq2seq
模型
。
对于流畅度提升学习,我们从
10-best outputs
中来筛选构造流畅提升句对,并且使用英语维基百科的语料作为正确文本来生成流畅句对
。在实际模型训练过程中,我们强制规定在每一轮训练迭代过程中,用于训练的流畅句对数量不超过原始训练句对的数量。
对于流畅度提升推断,我们使用了往返修改的策略
,在流畅度提升的前提下,用反向和正向的
seq2seq
模型交替对句子进行修改。此外,我们使用了
5
元组语言模型和编辑特征对于
beam search
选出的
12-best
句子进行重排序,从而选出最好的结果作为单轮推断的输出。
我们在
CoNLL-2014
和
JFLEG
两个基准测试集上对系统进行了评价,分别选用了两个数据集官方的评测指标
Max-match F_0.5
和
GLEU
。值得一提的是,
CoNLL-2014
数据集有两种不同的标注集。一种是原始标注集,由
2
名专业人员进行标注;而另一个标注集则是由
Bryant & Ng (2015)
后来对原始标注集的一个扩充,将标注数提到了
10
组。我们在这两个标注集下都进行了测试,分别区别这两种标注集,我们用
CoNLL-2014
代表原始
2
人标注集,
CoNLL-10
代表
10
人标注集。
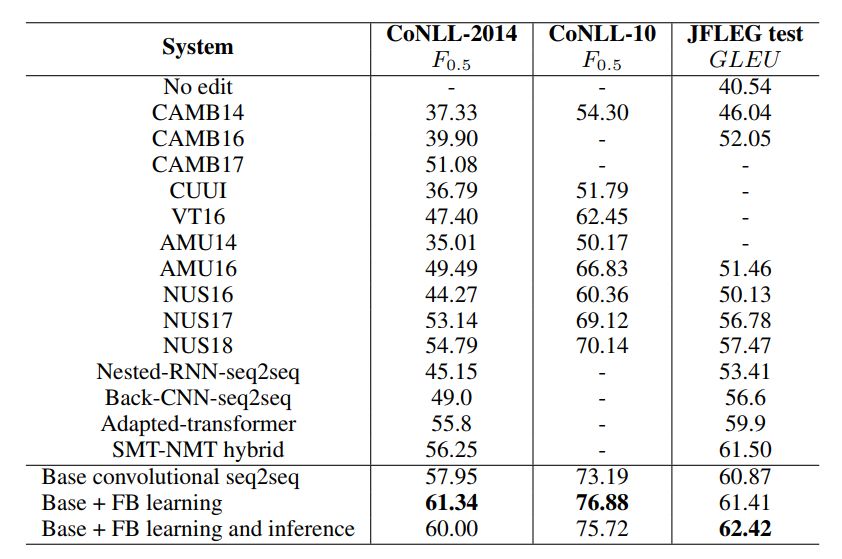
我们将
结合了流畅度提升学习和推断机制的
seq2seq
模型
和一些知名的语法改错系统进行了效果对比。从下表中可以看出,在使用了更多的训练数据之后,我们的基础模型就已经超越了多数先前的系统。当在基础模型上加入流畅度提升学习机制后,模型在三个基准上都有了显著的提高,在
CoNLL-2014
和
CoNLL-10
基准上达到了
61.34
和
76.88 F_0.5
,在
JFLEG
数据集上也达到了
61.41
的高分。当再加入流畅度提升推断机制以后,模型在
JFLEG
数据集上的得分提高到了
62.42
,但在
CoNLL
数据集上
F_0.5
的得分出现了下降。
通过分析发现,相比于基础
seq2seq
模型,流畅度提升学习能够提升模型在准确率、召回率、
F_0.5
、
GLEU
所有指标上的得分,有效地帮助模型更好地学习如何进行语法改错。流畅度提升推断能够显著提高召回率,但却会使准确率下降。由于
F_0.5
这个指标对准确率的权重要远大于召回率,因此模型在
F_0.5
的得分上出现了下降。而对于
JFLEG
数据集,加上流畅度提升推断后模型的
GLEU
得分能够从
61.41
提高到
62.42
,这也证实了流畅度提升推断能够更好地提升句子的流畅度。
在









