作为一家互联网服务提供商,Twitter在建设通信软件服务时遇到的网络问题、软件系统架构问题、软件技术选型等等都值得我们学习。Twitter发表的文章有助于读者从整体理解互联网软件开发、发布、问题解决等整个体系结构相关知识,也帮助读者从侧面完成技术选型。
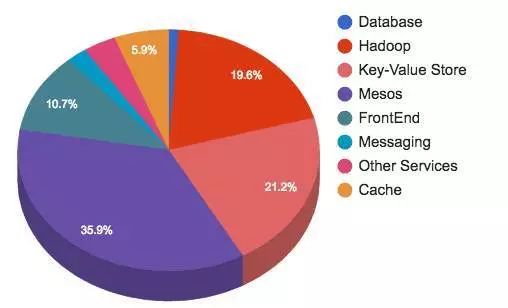
Twitter起步时正是服务器供应商统治数据中心的时代。自从那之后,Twitter团队没有停止前进的步伐,他们一直致力于使用开源社区的网络、软件技术和硬件,高效地提升集群性能,发布尽可能强的产品。Twitter目前的硬件使用情况分布如下:
2010年初,Twitter团队开始考虑将集群从第三方主机上迁出,这个决定和动作意味着Twitter团队需要学习如何构建和运行内部的基础设施,由于需要在有限的可视化情况下了解核心基础设施需求,团队开始调研各种网络设计、硬件,以及供应商。
到2010年下半年,Twitter团队完成了第一个网络体系结构设计,解决了科罗拉多主机集群遇到的扩展性和服务问题。该方案有深度缓冲设计,支持对于突发的流量请求以及确保电信核心交换机在网络层没有超载。这个方案支撑了Twitter的早期版本,创造了一些比较出名的业绩,例如打破了TPS数据记录的“天空之城”事件(每秒处理34000条记录)以及应对2014年世界杯。
此后的几年时间里,Twitter的数据中心运行在五大洲的成千上万的服务器,网络覆盖很广。从2015年上半年开始,Twitter开始遭受到了成长过程中的痛苦,由于不断变化服务系统架构和增加容量需求,最终达到了数据中心物理可扩展性的上线,网状拓扑结构不再支持通过增加新的机架提升性能,即不再支持增加额外的硬件。另外,Twitter现有的数据中心开始由于不断增加路由规模和复杂的网络拓扑结构导致出现不稳定异常情况。
为了解决这个问题,Twitter开始将现有的数据中心转换为Clos拓扑+BGP,这是一种必须在现场做的网络转换工作。尽管很复杂,但是Twitter在一个相对较短的时间内完成了这个转换,并且对服务影响最小。网络拓扑图看起来是这样的:
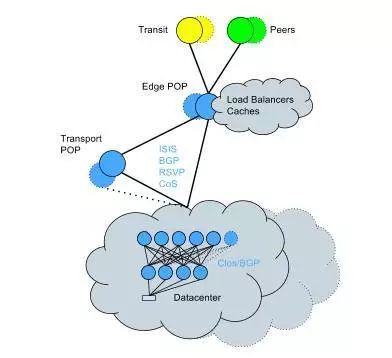
总结技术亮点如下:
Twitter的第一个数据中心是基于建模分析出的能力和已知系统的运行状态经验构建的。但是仅仅几年之后,数据中心比最初的设计扩大了400%。现在,随着Twitter应用程序堆栈的演变,Twitter正在变得更加分布式化,运行状态也在跟着变化。引导Twitter进行网络设计的最初假设场景已经不复存在了。
业务需求增长过快,导致针对整个数据中心进行重构已经不切实际。所以构建一个高可扩展的体系架构会让Twitter更容易增加能力,而不是采用叉车式的迁移方案。
高可扩展性的微服务需要高可靠性网络,可以支持处理各种业务。Twitter的业务范围从TCP长连接到离线的MapReduce任务,再到超短连接。针对这类多样性业务需求的应对方案是,部署具有深包缓冲区的网络设备,但是这样会带来一系列问题:更高的成本和更好的硬件复杂度。之后的设计Twitter使用了更加标准化的缓冲区大小,以及在提供切断开关功能的同时,提供了更好的TCP栈服务器,这样可以更好的处理网络风暴问题。
Twitter的骨干网流量每年都有大幅度正常,并且仍然可以看到数据中心之间的突发数据增长较正常状态的3-4倍情况存在。这种情况对于老的协议是一个特有的挑战,这些老的协议,例如MPLSRSVP协议,从来不是为应对突然爆发的网络风暴而设计的,它的目标是应对渐进式的缓慢的网络请求增长。为了获得尽可能快的响应时间,Twitter不得不花费大量的时间调整这些协议。此外,Twitter实现的优先次序可以处理网络高峰(特别是存储复制)情况。
Twitter需要确保在任何时候优先客户的传输流量,可以通过延迟低优先级的存储复制工作满足这个需求,存储复制这类工作有一天时间的SLA。这样就可以使用最大量的网络资源,让数据尽可能快速地移动。客户业务需求比低优先级的后台业务需求优先级高。而且,为了解决伴随着RSVP自动带宽而来的bin-packing问题,Twitter实现了TE++,这个工具当流量增加时创建额外的LSP,当流量下降时则会删除LSP。这使得Twitter可以有效地管理连接之间的网络业务,同时减少维护大量的LSP所造成的CPU负担。
然而主干网从最初开始就缺少任何业务工程设计,后来增加了帮助Twitter可以根据业务增长进行扩展的特性。为了实现这一点,Twitter完成了角色分离,使用单独的路由器分别处理核心和边缘路由请求。这也使得Twitter能够低成本效益地扩展,而不需要购买复杂的带边缘功能的路由器。
在边缘路由层,Twitter有一个核心连接所有网络,并且可以支持水平扩展,例如每个站点有很多路由器,不止两个,因为Twitter有一个核心层互联所有的设备。
为什么扩展路由器的RIB(路由信息库,即Routing InformationBase),Twitter引入了路由反射机制,这样就可以适配扩展需求,但是在做这个的过程中,需要移植到变更设计,Twitter也做了路由反射的客户端!
每天有数以百万计的的推文(微博)被发送出来。这些推文需要被处理、存储、缓存、服务以及分析。对于如此庞大的信息内容,Twitter需要一个稳定的基础设施。存储和消息占据了45%的Twitter的基础设施空间。
存储和消息团队提供了如下服务:





