
本文长度为6843字,建议阅读7分钟
本文为你介绍CVPR 2017 大会情况。
备受瞩目的 CVPR 2017 刚刚公布了最佳论文归属:康奈尔大学和清华大学DenseNet和苹果首次公开的视觉方向论文。同时CVPR其他各项大奖也全面揭晓。我们第一时间为你介绍获奖论文,同时献上本届大会导览,包括以下内容:
全部 783 篇接收论文中的最热关键词及体现的技术趋势,深度学习依然是主流,Image、Object、Video 等词出现频率也很高;
三场主旨演讲(包括沈向洋);
近 30 个 workshop 及相关竞赛结果(下一个ImageNet会是哪个?);
参会企业大盘点。
华人学者在这届大会表现格外亮眼,不仅接收论文数量超过了全部的 45%,在会议的 81 名主席名单中,也有多位华人面孔,比如张正友、陈熙霖、华刚(2019 年 CVPR 程序主席)、贾佳亚、孙剑、吕乐、周少华、朱松纯等老师。
CVPR 2017 大会导览
2017 年的 CVPR 还没有召开便获得了极大的关注。
根据会议官方网站的数据,今年,CVPR 共收到2680篇有效投稿,是有史以来最多的一届。其中,一共有 783 篇论文被接收。
在参会人数方面,今年的参会人数为4950人,逼近5000人。根据参会者在 Twitter 上的“爆料”,近5000人规模的会场在 21 号签到时早早排起了长龙。去年,CVPR总共参会人数3600人,其中有34.35%是学术,28.62%学术界,37.03%来自产业界。
同样是在官方宣布的数据中,我们看到,2017年产业界的参与数量众多,全球共有约 90 家企业参与到本次大会中。除了大家熟知的谷歌、微软、Facebook、亚马逊、苹果、英特尔、英伟达等巨头,中国的腾讯、阿里巴巴、京东、滴滴等大型互联网公司,还有众多初创企业,比如驭势、格灵深瞳以及 Momenta 等等。
感受一下CV界的春晚有多热闹:


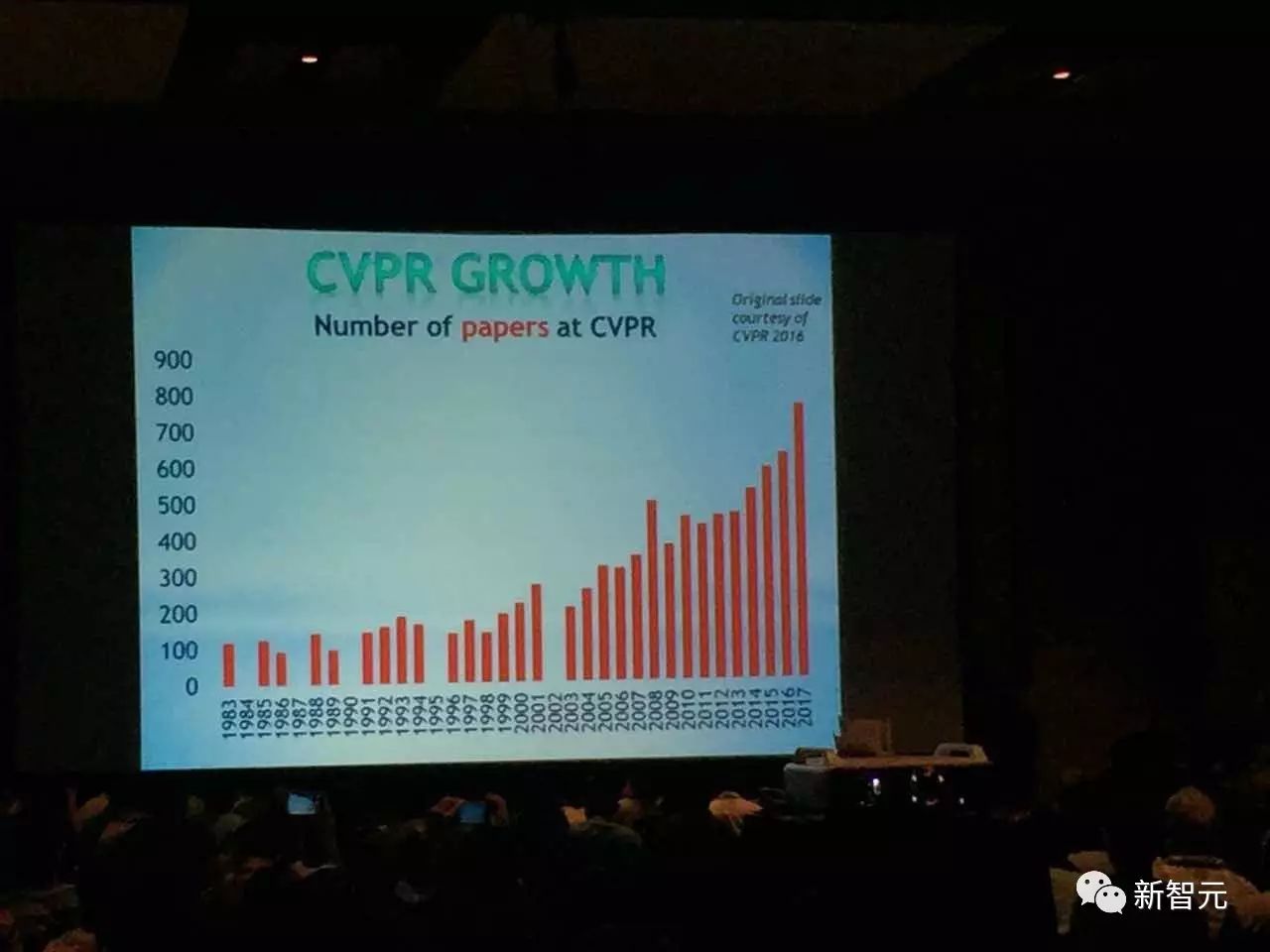
下图:CVPR历年论文数量变化。可以看到,2017年论文数量有一个非常大的提升,论文总数为783篇,历史最高。也可以看出计算机视觉在整个研究领域的热度。
所有783篇论文下载地址:http://openaccess.thecvf.com/CVPR2017.py
CVPR 2017 最佳论文:DenseNet 和苹果合成图像论文

后台回复关键词“CVPR”,下载最佳论文合集。
CVPR 2017 共评出5 大论文奖:
最佳论文(2 篇)
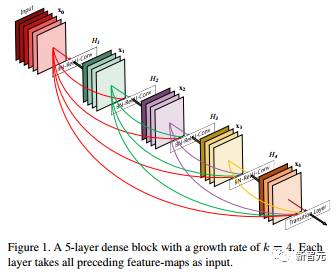
论文一:Densely Connected Convolutional Networks
作者:Gao Huang, Zhuang Liu, Kilian Q. Weinberger, Laurens van der Maaten
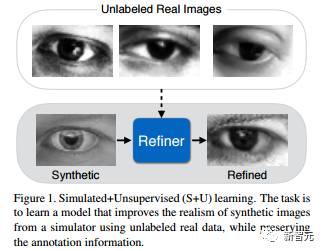
论文二:Learning from Simulated and Unsupervised Images through Adversarial Training
作者:Ashish Shrivastava, Tomas Pfister, Oncel Tuzel, Josh Susskind, Wenda Wang, Russ Webb
最佳论文提名(优秀论文)(2 篇)
论文一:YOLO9000: Better, Faster, Stronger
作者:Joseph Redmon, Ali Farhadi
论文二:Annotating Object Instances with a Polygon-RNN
作者:Lluis Castrejon, Kaustav Kundu, Raquel Urtasun, Sanja Fidler
最佳学生论文(1 篇)
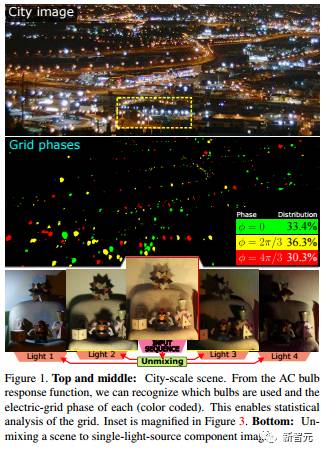
Computational imaging on the electric grid
Mark Sheinin, Yoav Y. Schechner. & Kiriakos. N. Kutulakos
其中,DenseNet 论文是康奈尔大学的 Gao Huang 和清华大学的 Zhuang Liu 等人在 2016 年发表的。DenseNet 可以看做是 ResNet 的一个变体。不同于 ResNet 将输出与输入相加,形成一个残差结构,DenseNet 将输出与输入相并联,实现每一层都能直接得到之前所有层的输出。另一篇最佳论文则来自苹果。不得不说,这家公司不鸣则已一鸣惊人,公开发表论文不久便斩获 CVPR 最佳。今后苹果的表现值得期待。
下面,我们简单介绍最佳论文。
最佳论文一:密集连接卷积网络

摘要
最近的研究显示,如果卷积网络中分别接近输入端和输出端的层之间包含更短的连接,那么该卷积网络可以显著地实现更深、更准确,并且更高效。在本研究中,我们同意这一观察,并提出DenseNet(Dense Convolutional Network),它以前馈的方式将所有层连接起来。一个L层传统卷积网络具有L个连接——即每一层和它的后一层之间都有一个连接,我们提出的DenseNet网络具有L(L + 1)/2个直接连接。对于每个层,它的输入是所有前面的层的特征图,并且其自身的特征图被用作所有后面的层的输入。DenseNet的突出优点有几点:减轻了梯度消失的问题,加强了特征传播,鼓励特征重用,并且大大减少了参数数量。我们在4个高度竞争性的对象识别基准任务(CIFAR-10,CIFAR-100,SVHN和ImageNet)中对我们提出的架构进行了评估。结果显示,DenseNet 在大多数任务上相比以前的最优结果获得了显著的进步,并且在实现高性能的同时所需的内存和计算更少。相关代码和模型可以在这里找到:https://github.com/liuzhuang13/ DenseNet
最佳论文二:通过对抗训练从模拟图像和无监督图像学习

摘要
随着图形学最近得到的进步,使用合成的图像训练模型变得更加容易了,这能免除对数据进行注释的昂贵花费。但是,由于合成的图像和真实图像分布之间存在差距,从合成的图像学习可能无法实现期望的性能。为了缩小这一差距,我们提出模拟+无监督(Simulated+Unsupervised,S + U)学习,它的任务是学习一个模型,以使用未标记的真实数据来改善模拟器的输出的真实感(realism),同时保留来自模拟器的注释信息。我们为S + U学习开发了一种使用对抗网络的方法,类似生成对抗网络(GAN),但我们的方法使用合成的图像(而非随机向量)作为输入。我们对标准GAN算法进行了几个关键的修改,以保留注释信息,避免失真(artifacts)并保持训练稳定:(i)一个“自正则化”项,(ii)一个局部对抗损失( local adversarial loss),以及(iii)使用改善后的图像的历史信息来对判别器进行更新。我们的研究表明,这一方法能够生成高度逼真的图像,并且通过定性研究和用户研究证实了这一点。我们通过训练模型进行视线估计(gaze estimation)和手势估计(hand estimation)进行了定量评估。我们的研究显示,这一方法在使用合成图像方面实现了显著提升,并在没有任何已标注数据的情况下,在 MPIIGaze 数据集得到了 state-of-the-art 的结果。
最佳学生论文:电网计算成像(Computational Imaging on the Electric Grid)

摘要
交流电(AC)照明带来了夜的节拍。 通过对这种节拍的感受,我们揭示了新的场景信息,包括:场景中的灯泡类型,城市规模的电网分段(phase)以及光传输矩阵。这种信息区分了反射和半反射,夜间高动态范围以及在采集期间未观察到的灯泡的场景渲染(scene rendering)。 后者由我们收集并提供的来源丰富的灯泡响应函数数据库促成。为了实现以上工作,我们构建了一种新颖的 coded- exposure 高动态范围成像技术,专门设计用于在电网交流照明上运行。
大会还公布了Longuet-Higgins 奖和PAMI 年轻研究员奖:
Longuet-Higgins 奖是 IEEE 计算机协会模式分析与机器智能(PAMI)技术委员会在每年的 CVPR 颁发的“计算机视觉基础贡献奖”,表彰十年前对计算机视觉研究产生了重大影响的 CVPR 论文。奖项以理论化学家和认知科学家 H. Christopher Longuet-Higgins 命名。
2017 年的Longuet-Higgins 奖被授予了 J. Philbin 等人在 2007 年发表的 CVPR 论文“Object retrieval with large vocabularies and fast spatial matching”。根据谷歌学术搜素引擎,这篇文章的被引次数高达 2122 次。
另一个奖项是“PAMI 年轻研究员奖”(PAMI Young Researcher Award),这个奖项授予那些博士毕业不超过 7 年并在计算机视觉方面有卓越研究贡献的的年轻研究人员。PAMI 年轻研究员奖自 2013 年起颁发,继承了 2012 年IVC 的“杰出青年研究员奖”(Outstanding Young Researcher Award)。
2017 年的 PAMI 年轻研究员奖得主是 Ross Girshick(Facebook AI Research,FAIR) 和 Julien Mairal(INRIA)。
从以上多个奖项的获奖者来看,虽然华人学者在CVPR的论文提交数量和竞赛上有出色表现,但是获奖的比例并不算高。
接收论文:华人学者的半壁江山依然稳固,“深度学习”稳坐关键词第一把交椅
今年,CVPR 共收到2680篇有效投稿,其中2620篇经过完整评议(其余60篇有一些是出于技术或伦理方面的原因被委员会拒绝,有一些则在评议前退出)。
最终,一共有783篇论文被接收(接收率为29%)。其中有71篇获得长篇口头报告的展示机会,144篇获得短报告(spotlights)的机会。
CVPR 2017的接收论文有三种展示形式:两种形式的口头展示(长篇与短篇,即Oral 与 Spotlights),以及海报展示。新智元统计发现,大会一共有107个Session。
ORALS:与传统的CVPR orals 一样,CVPR 2017 上进入 orals 环节的论文数量比例与此前几届CVPR一致。每一个orals 报告的时间是12分钟。
SPOTLIGHTS: 每一个spotlight的报告者有4分钟的口头报告时间,来强调论文的主要贡献和创新之处,以及报告论文的主要研究成果。
POSTERS: 口头报告之外的论文将会得到海报展示的机会。此外,所有的口头报告之外的论文也会出现在接下来的海报展示环节中。
全部论文名单地址:http://www.cvpapers.com/cvpr2017.html
经过统计,全部 783 篇论文中,华人学者参与并署名的论文约为356篇,占比45.47%。(人眼统计,可能会存在微小误差)

我们根据接收论文的题目做了粗略的热词统计(见上面这张云图)——“深度学习”毫无意外地是最热关键词。同时,Image、Object、Video 等词出现频率也很高,这很好理解,因为 CVPR 是计算机视觉会议。同样,识别、检测、分类和卷积、残差(网络)等也是高频词。
Face 的出现证明了人脸识别的火热,相较 hand、pose ,尤其是 hand,还不到 Face 的五分之一。在模型的选择中,GAN 和生成模型十分突出,与 2017 年以来视觉界对 GAN 的关注离不开关系。实际上,这次被接收的论文中出现了多种 GAN 的变体。
接下来,让我们看看更加详细的分类。
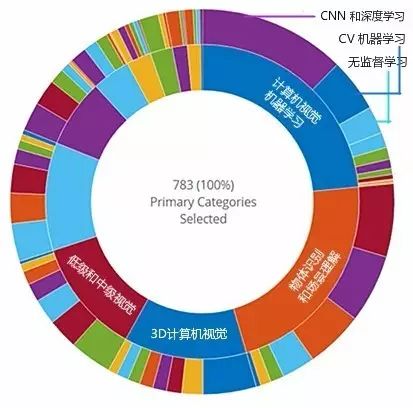
CVPR 2017 接收论文领域分布情况。本次大会共接受 783 篇论文,内环表示主要分领域,外环表示次要分领域。内环右上角开始,顺时针依次显示了论文数量从多到少的主要分领域。最大的蓝色部分代表机器学习,接下来的红色代表物体识别和场景理解,再接着的蓝色表示 3D计算机视觉。其他颜色对应内容详见下面列表。
在这届 CVPR 接收的全部 783 篇论文中,机器学习是主要分领域中论文最多的,占了 23.5%,计算机视觉理论最少,占1.40%。各个主要分领域论文分布情况如下:
计算机视觉中的机器学习 184篇(23.5%)
物体识别和场景理解 172篇(22%)
3D 计算机视觉 99篇(12.6%)
低级和中级视觉 93篇(11.9%)
分析图像中的人类 87篇(11.1%)
视频分析 55篇(7.02%)
图像动态及追踪 31篇(3.96%)
应用 20篇(2.55%)
计算摄影 18篇(2.30%)
生物医药图像分析 12篇(1.53%)
计算机视觉理论 11篇(1.40%)
而在机器学习论文当中,最多的是 CNN 和深度学习(外环右上角紫色部分),其次是计算机视觉中的机器学习(外环右上角蓝色部分),再次是非监督学习、离散优化、连续优化等。
3大主旨演讲:从基础研究到应用再到未来研究方向
2017 年的 CVPR 共有 3 场主旨演讲,分别在当地时间 22 日、23 日和 25日举行。主题从基础——了解灵长类视觉系统从而更好地设计深度神经网络——到应用,再到未来研究方向,为为期一周的大会奠定了基调。

摘要:神经科学和认知科学的一大难题是人类思维的反向工程。与其他科学领域相比,这个领域仍处于起步阶段。旨在模拟人工系统里的人类智能(AI)的正向工程方法也还是起步阶段。但是,在人类行为中显见的智能和认知的灵活性是存在的证据,证明机器可以被设计来模仿人类思维并与人类一起工作。在这个演讲中,我将提出,通过结合脑科学和认知科学家的研究(生成和数据采集),以及旨在模拟思维(实例化和数据预测)的正向工程,思维的反向工程可以解决。为了支持这个论点,我将重点关注感知智能(对象分类和检测),我将讲述脑科学,认知科学和计算机科学中如何融合以创造可以支持这些任务的深度神经网络。这些网络不仅在图像任务上达到人类的表现,而且它们的内部运作机制也大量模拟理论灵长类动物视觉系统的内部机制。但是,灵长类视觉系统(NI)表现仍然超出当前的深度神经网络(AI),我将展示一些神经科学方面的新线索。更广泛地说,这只是这一伟大人类科学追求的开始——理解自然智能,我希望激励更多人与我们一起参与这一领域。
主旨演讲二:沈向洋博士,微软全球执行副总裁
演讲题目:计算机视觉的商业化:成功故事和经验教训
摘要:对于所有的计算机视觉研究者和实践者来说,这是一个令人兴奋的时代。我们已经看到,将多年的技术进展转化为市场化技术这一方面获得了空前增长。微软多年以来一直致力于开发新的计算机视觉技术,向所有的开发者开放,并把它们融入各种产品当中。
在这一研究中,我将会简单地回顾计算机视觉在微软研究院过去25年的研究历史,强调微软研究院对计算机视觉领域的贡献,并且着重介绍长期投入在企业中成功打造产业研究院的重要意义。
在介绍微软商业化的成果之前,我还会介绍一些我们在计算机图学、图学理解、视觉和语言等方面的最新研究成果,具体地,我将介绍微软在开发三款产品上的经验:微软Pix,HoloLens和认知服务,三者分别以不同的方法在利用计算机视觉系统和技术。
Pix 是一个基于AI的照相APP,它会让你更轻松有趣地拍出“伟大的照片”,“聚焦、拍照、完美!”它融合了微软研究院几十个CVPR、ICCV和SIGGRAPH的研究成果。HoloLens是市场上第一个商业可用的混合现实系统。认知服务则能让你在只使用几行代码的情况下,在不同的设备和平台上,搭建起基于AI的、实用的APP。
在本次演讲中,我将展示IRIS,这是一个交互式的视觉学习服务,让开发者可以创建图像识别应用程序。我还将展示一些关于HoloLens最新的demo,其中包括Holoportation 项目。Holoportation 是一个新的3D捕捉技术,允许对高质量的人物3D模型进行重建、压缩和变换,随时随地都能进行。推动从研究到产品循环,其中有不少挑战。我将会讨论,从生产Pix, HoloLens 和 认知服务中所获得的经验。
摘要:我会在大会上介绍我们实验室在计算机从语言中提取社会意义的研究,也就是考虑人与人之间的社交关系的研究。我们研究了在交通信号灯前,经常和社区成员之间的互动情况。我们自动地测量了语言交互的质量,研究了交流过程中种族的角色,并为这一领域的一些未来研究提供了建议。
另一方面,我们将科学论文的语言与由科学家及其研究领域组成的网络进行计算建模,以更好地了解科学创新进展情况以及跨学科的作用。我将讲述上述研究对科学史,特别是人工智能的影响。这两项研究都强调了社会语境和社会模式在解释我们使用的词语背后潜在含义的重要性。
14场竞赛,各路英雄现场比拼
本届 CVPR 有超过 50 个workshop,其中“超越 ILSVRC”workshop 将正式宣布ImageNet 竞赛的完结。ImageNet 之所以不再正式举办,是因为在 2016 年 ILSVRC 的图像识别错误率已经达到 2.9% 左右,远远超越人类(5.1%),今后再进行这类竞赛意义就不大了。未来,计算机视觉的重点在图像和视频的理解。由此,便产生了一个值得关注的问题——继 ImageNet 之后成为计算机视觉界标志性竞赛的是什么。
据不完全统计,本届 CVPR workshop 中有 14 场竞赛:
ActivityNet大规模活动识别竞赛2017
超越ImageNet大型视觉识别竞赛
视频对象分割的DAVIS竞赛2017
2017年视觉问题回答竞赛
YouTube-8M大规模视频理解竞赛
Look into Person(LIP)竞赛
自动驾驶竞赛
“In-the-wild”人脸竞赛
大规模场景理解(LSUN)竞赛
交通监控竞赛
运动非刚体结构(NRSfM)竞赛
NTIRE 2017单图像超分辨率竞赛
开放领域行动识别竞赛
PASCAL in Detail 竞赛
可以看出,从场景理解到自动驾驶,本届 CVPR 举办了各种竞赛。其中,我们获得独家消息,Look into Person(LIP)竞赛,中国中科院信息工程研究所刘偲副研究员带领的S-Lab团队与三星电子北京研究院合作夺得行人图像分割项目冠军。这一竞赛为CVPR2017 workshop的竞赛单元,其独家发布了LIP人体图像数据集,通过海量的图片、丰富的标注类别、多样的数据,有效地填补了图像分割领域行人数据集的空白。

竞赛分为行人图像分割、人体姿态检测等项目,信工所S-Lab与三星合作团队即是夺得了行人图像分割项目的冠军。这一项目要求参赛者对真实行人图片进行像素级别的类别预测,从而完成图像分割,赛题难度较大,吸引了海内外众多团队参与。S-Lab与三星合作团队在竞赛中针对行人图像视角多样化的特点,提出了基于视角的图像分割模型VS-Net,极大地提升了图像分割的精确程度,为后续的学术研究与业界应用提供了新的思路。
信工所研究员对新智元介绍说,在本届CVPR,来自中科院信工所的Si Liu, Ruihe Qian, Han Yu, Renda Bao, Yao Sun 和今日头条Changhu Wang合作发表的论文《Surveillance Video Parsing with Single Frame Supervision》,利用视频中的时序上下文信息,有效的缓解了视频中语义分割标注难的问题。文章提出利用一套端到端的Single frame Video Parsing (SVP)网络,在每个视频只标注一帧的极端情况下,依然取得很好的性能。课题组同时还发表了论文《Learning Adaptive Receptive Fields for Deep Image Parsing Network》,该论文同样针对图像分割问题,进行了视野域方面的研究。
有关竞赛的更多详细介绍,敬请关注后续报道。

赞助企业:BAT之外,涌现大量创业企业
大会的赞助商从一定程度上反映了与产业界的联系,从中也能看出学术成果的产业转化情况。2017 年 CVPR 的企业赞助可谓盛况,全球共有约 90 家企业参与到本次大会中。除了大家熟知的谷歌、微软、Facebook、亚马逊、苹果、英特尔、英伟达等巨头,中国的腾讯、阿里巴巴、京东、滴滴等大型互联网公司,还有众多初创企业,比如驭势、格灵深瞳以及 Momenta 等等。

其中,大会白金赞助商有谷歌、微软、Facebook、亚马逊、苹果、英特尔、英伟达,也有中国的腾讯、阿里巴巴、京东、滴滴和驭势、格灵深瞳以及 Momenta。

大会金牌赞助商

大会银牌赞助商


铜牌赞助商

初创企业赞助商

其他赞助商
CVPR 上的华人主席:31名
CVPR 2017 共设置有大会主席、程序主席、Workshop主席、Corporate主席、Doctoral Consortium主席、Finance主席、学生志愿者主席、技术主席、出版主席和领域主席等。共有81位主席,其中华人学者人数在30位左右。
根据视觉求索的介绍,CVPR 大会领域主席(Area Chair or AC)是由大会程序主席指定的。Area Chair起着极其重要的作用,某种程度上具有投稿的直接“生杀大权”。因此,Area Chair一般都是领域内颇有建树的专家学者。
我们主要介绍在本次大会上担任主席的华人学者们:
大会主席
张正友 (微软)。张正友博士是世界著名的计算机视觉和多媒体技术的专家,是ACM Fellow和IEEE Fellow。他在立体视觉、三维重建、运动分析、图像配准、摄像机自标定等方面都有开创性的贡献。目前,正从事人机交互和远程实景临场等领域的一些核心技术研究。他发明的平板摄像机标定法在全世界被普遍采用,被称之为“张氏方法”。
程序主席
刘燕西(宾夕法尼亚州立大学)
吴郢(西北大学)
Workshop 主席
陈梅(奥尔巴尼大学)
Corporate Relations Chairs
颜水成(奇虎360)
韩玫(Google)
Demos Chair
吕乐(NIH)
Website Chair
袁浚菘(南洋理工大学)
Publicity Chair
龚怡宏(西安交通大学)
领域主席
陈熙霖(中国科学院)
华刚(微软亚洲研究院)
贾佳亚(香港中文大学)
李伏欣(俄勒冈州立大学)
刘策(Google)
刘小明(密歇根州立大学)
刘自成(微软研究院)
吕乐(NIH)
罗杰波(罗彻斯特大学)
史建波(宾夕法尼亚大学)
孙剑(旷视科技)
田奇(圣安东尼奥得克萨斯大学)
王井东(微软亚洲研究院)
王晓刚(香港中文大学)
吴建鑫(南京大学)
杨睿刚(肯塔基大学)
尹朝征(密苏里科技大学)
虞晶怡(特拉华大学 / 上海科技大学)
袁浚菘(南洋理工大学)
张察(微软研究院)
周少华(西门子企业研究所)
朱松纯(UCLA)
编辑:王璇
校对:闵黎
为保证发文质量、树立口碑,数据派现设立“错别字基金”,鼓励读者积极纠错。
若您在阅读文章过程中发现任何错误,请在文末留言,或到后台反馈,经小编确认后,数据派将向检举读者发8.8元红包。
同一位读者指出同一篇文章多处错误,奖金不变。不同读者指出同一处错误,奖励第一位读者。
感谢一直以来您的关注和支持,希望您能够监督数据派产出更加高质的内容。

公众号底部菜单有惊喜哦!
企业,个人加入组织请查看“联合会”
往期精彩内容请查看“号内搜”
加入志愿者或联系我们请查看“关于我们”










