前不久,我开始同时学习python和Selenium WebDriver(自动化测试工具软件),想看看我能否在Instagram上获得一些粉丝,我惊讶的发现我的第一个试运行的脚本程序竟然很有效!
只是通过对一些图片增加标签,我就得到了一些点zan、评论和甚至不少粉丝,而且粉丝的数量上升的非常快。
起初,我是把程序放在我的笔记本电脑上运行的。但是这很麻烦麻烦,因为我需要一直开着电脑。
我是从180个粉丝开始的,当我的粉丝数量达到350个的时候,我修改了我的脚本程序并将它放到了服务器上。然后效果就开始越来越好了。
在我开始讲我的InstaPy脚本程序的故事之前,我想说的是这几点:
如果你想要尝试,你可以去GitHub上去找你所需要的代码 。
如果你想学习python,这里可以找到很棒的书和安装包来帮助你开始学习!
https://www.humblebundle.com/books/python-book-bundle
我从做一些简单的分析(包括用线性回归来预估明天的增长情况)来开始寻找最佳的标签以及参数值。
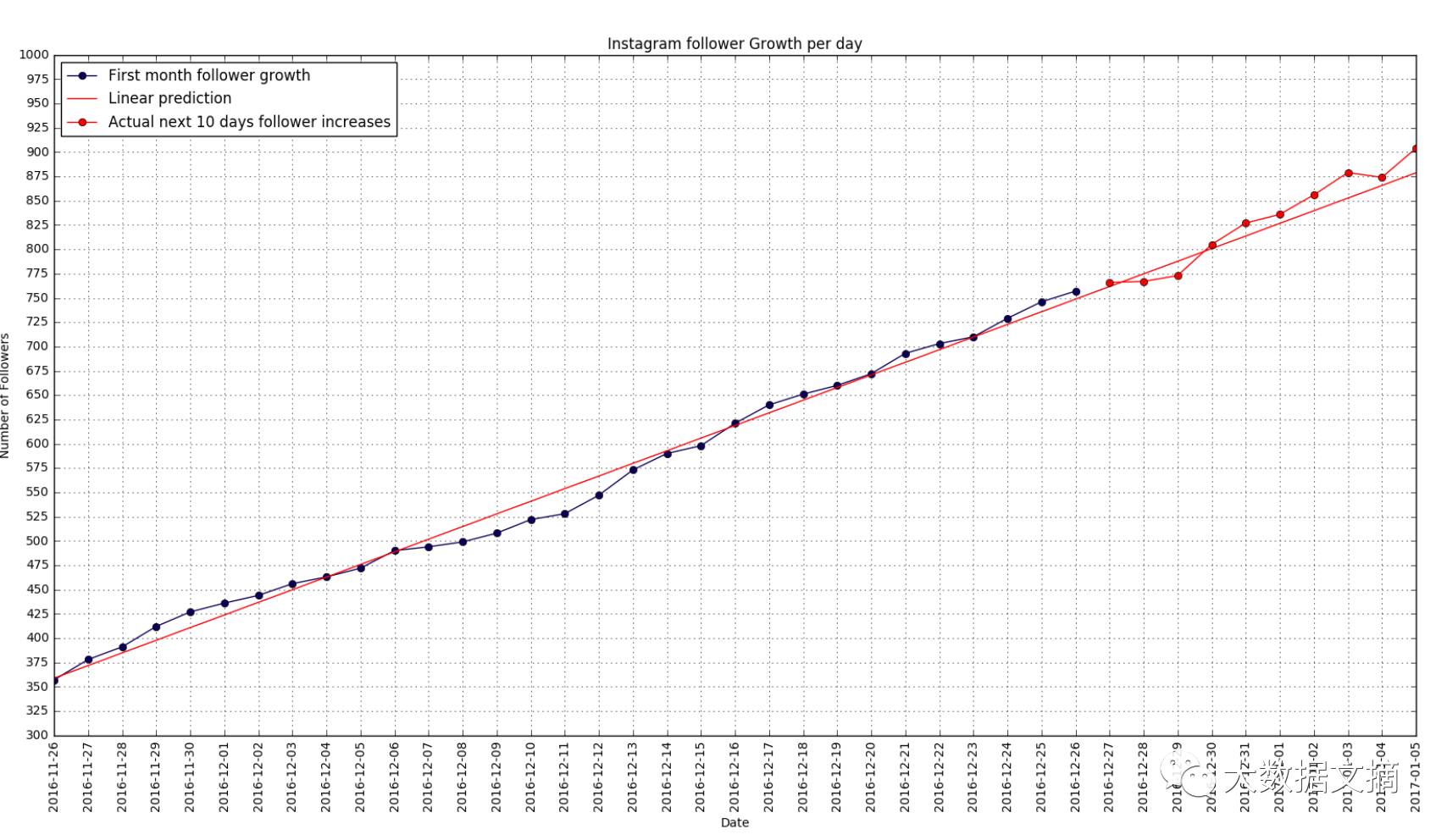
第一个月粉丝的增长情况
使用历史数据来画简单的线性图,那么我就能大概预估出9天后有多少个粉丝了。但是在第10天的时候,规律较之前又有比较大的变化。
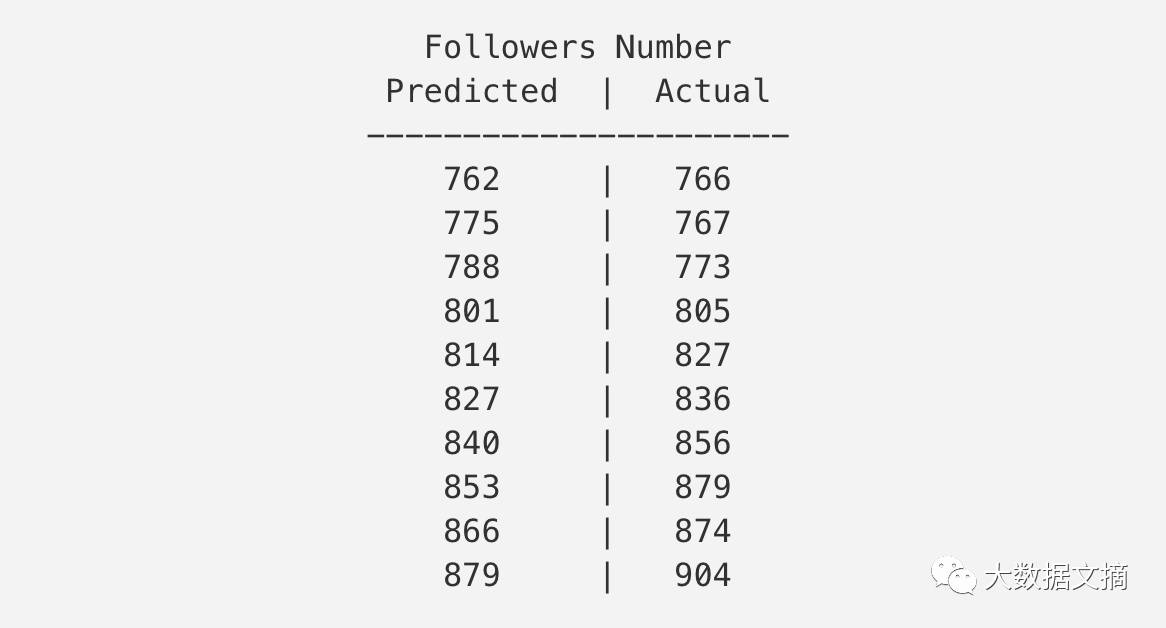
我按照这个方法试了,所以我之后就能去查看之前的数据增长是按照指数增长还是线性增长。
在第一个月的时候,约有13个新粉丝每天都会关注我。有趣的是,我在有几天的时候甚至失去了一些粉丝。这些粉丝都比较喜欢“身家百万的导师”和其他有百万粉丝的博主。
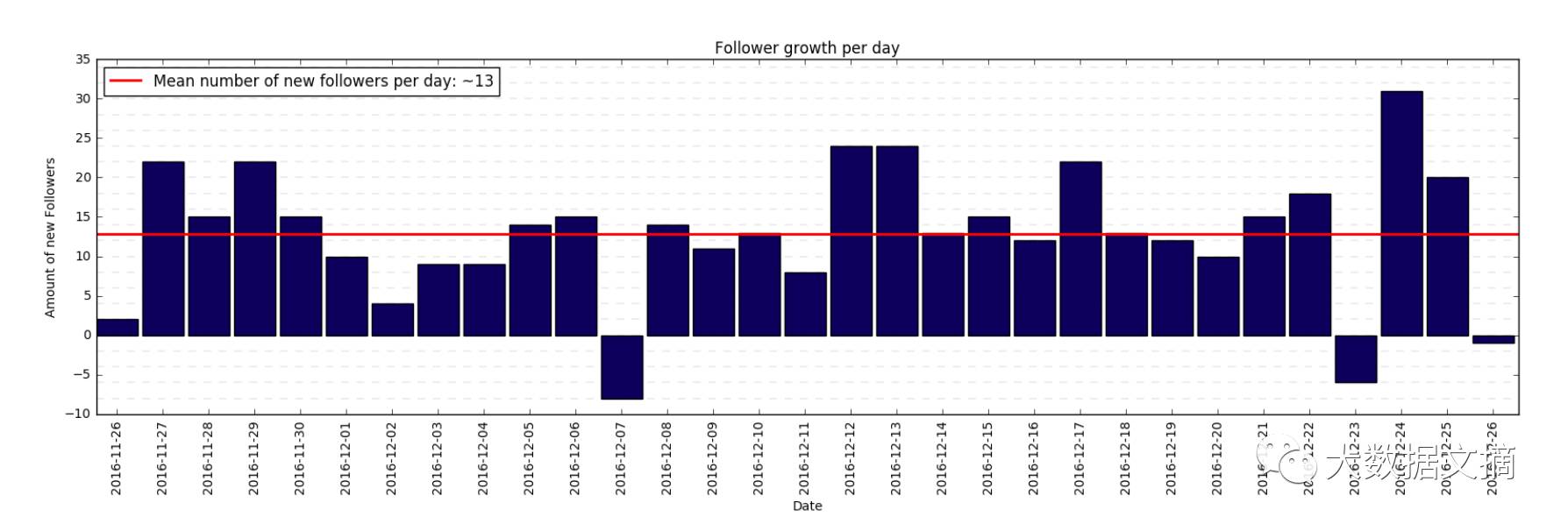
第一个月每天新的粉丝数量统计情况
当通过单独查看脚本的每次“运行”来更加仔细地观察日常增长,我们可以清楚的看到ins上会有些用机器人程序来运营的博客账户。
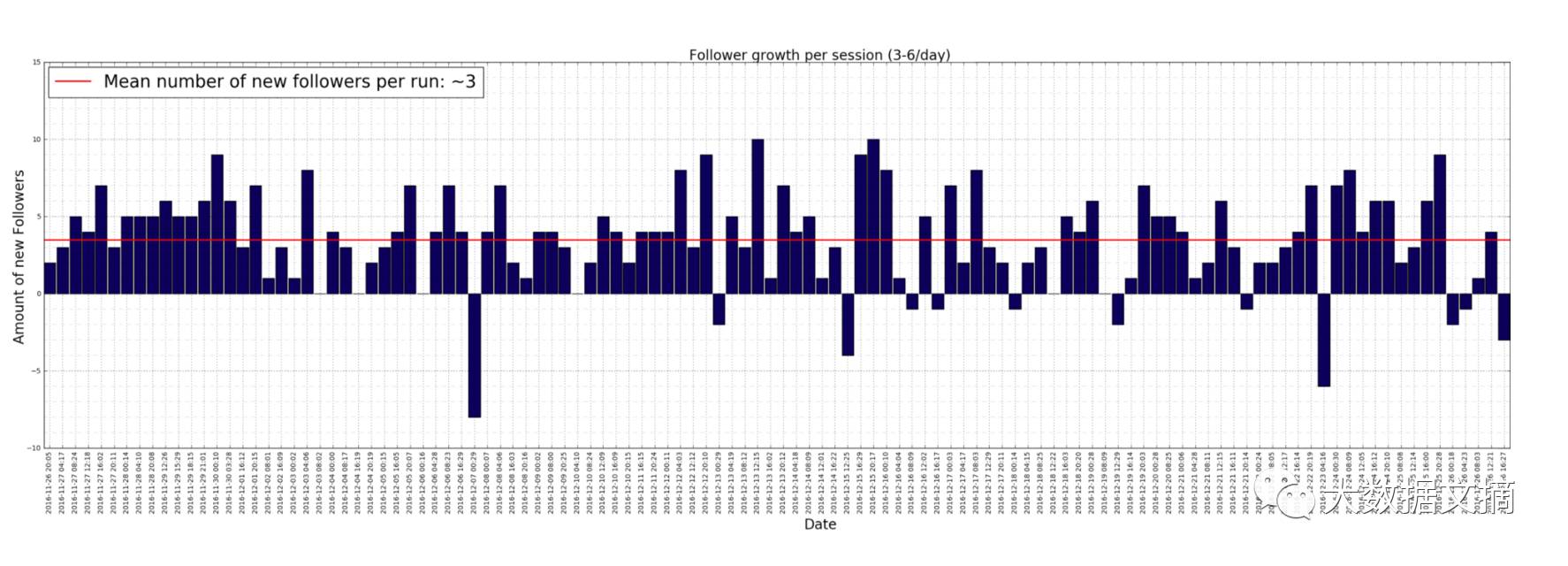
注意:0个新粉丝不代表没有增加新的粉丝,取消关注的只是和新关注的相互抵消了。
让我们来看看上面的立柱图,我们可以看到在一段时间内的8个小时里,我的账户失去了8个粉丝,只增加了3个新的粉丝(按照每个回合平均来算)我是失去了11个粉丝。
左边:程序运行10分钟后 /右边:程序运行25分钟前
上面的图例展示了程序运行10分钟后和下一次运行程序的25分钟前的标准增长。标准增长一直是这样,甚至是在我的账户失去粉丝的时候也是这样 。
这个关注与不关注策略的灵感来源于我的朋友告诉我:我几乎觉得因为你关注了我所以我欠你些东西。
大部分的粉丝确实是这样,不像你购买的僵尸粉一样,只是没有动态的空账户。
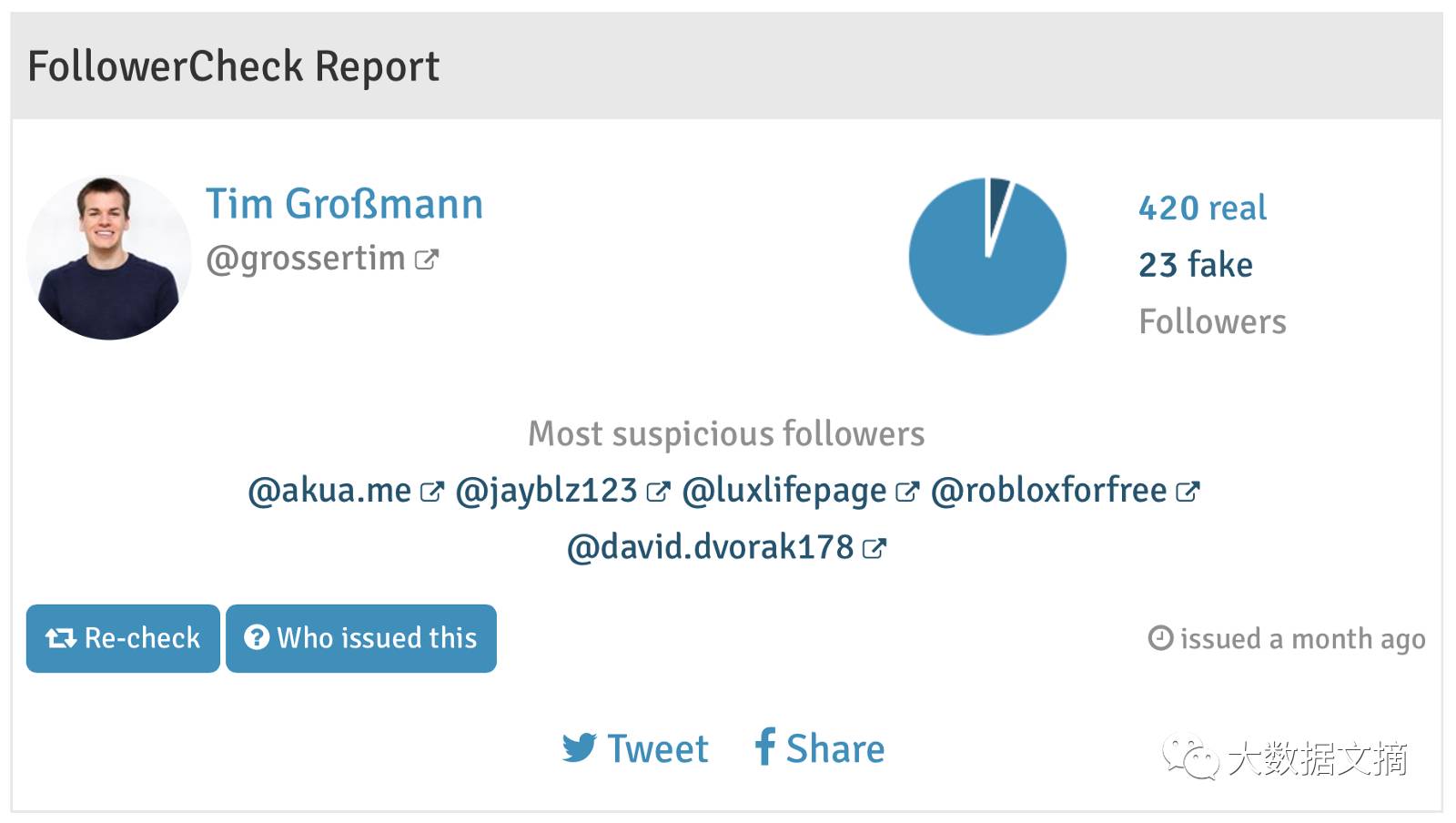
在这页443个粉丝的报告上,像@ luxlifepage这样的账户名就有可能是僵尸粉,因为这用户名有点像垃圾字符。
正如你在下图看的那样,新关注我的粉丝会在我的博客里比较积极的活动,就不像那些僵尸粉一样不活跃。
到目前为止,我评论最多的帖子:

按2016年ins平台上账户每月增长粉丝的比例为16%,而我一月增长粉丝的比率达到了112%(从357名->757名粉丝)。
第二个月就开始变得更好了,我达到了94%的增长比率。我开始寻找合适的标签来接触更多的粉丝,最重要的是,如果帖子越多,那么会有许多人使用这个标签。
当你准备发帖的时候,就可以看到标签分类和标签被使用的数量。
帖子的标签分类和标签的使用数量
通过这3个标签,我已经得到了一大群粉丝了。这些已经是我的标签模板,并且得到大量的应用。

大部分经常被使用在帖子里的标签
通过对我的帖子经常被点zan、评论和标签的数量分析,我将分析结果写成了一个小程序将其简单处理后保存为JSON。
提示:最好使用正能量的标签,将会呈现积极的感觉。
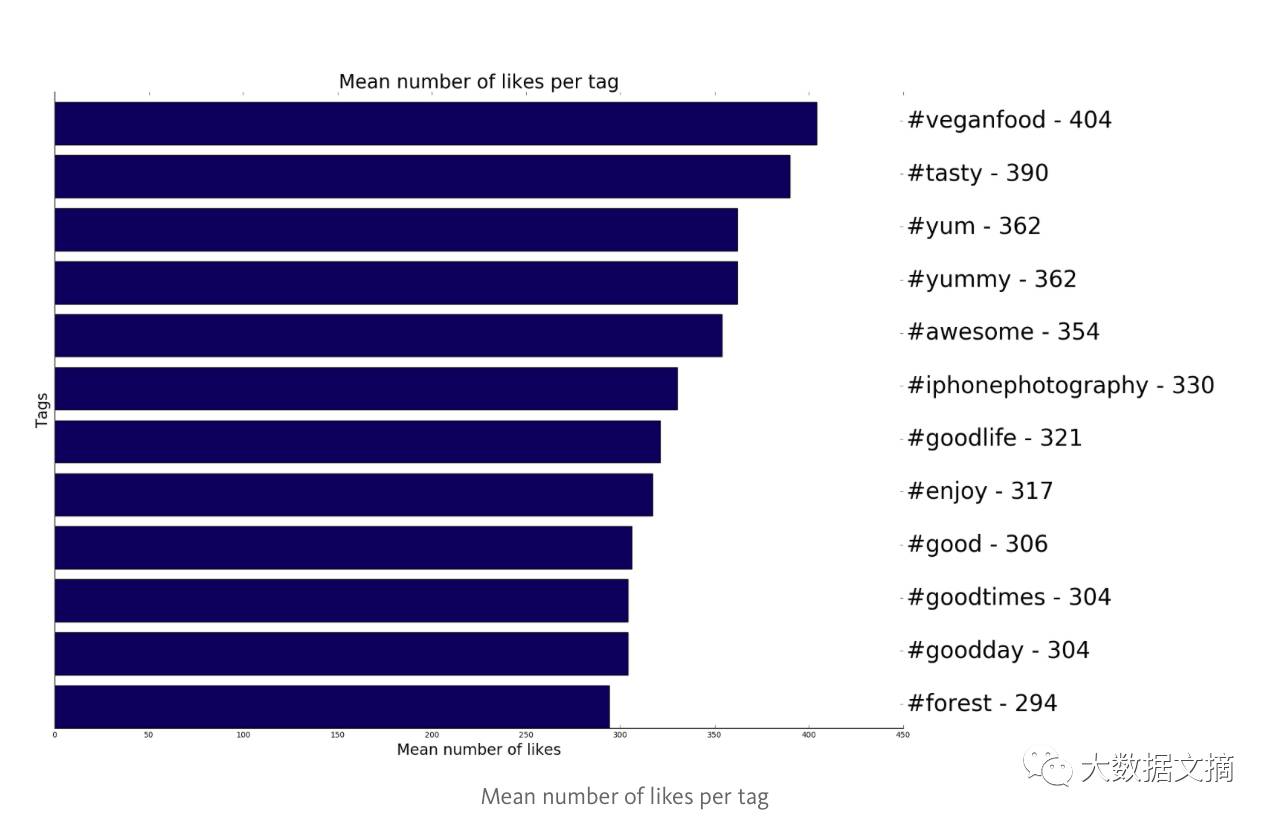
每个标签平均被zan的数量
如果我们仔细看一下上图,就能发现 “美味” 标签的帖子,我平均得到了390个zan。
我还会发布其他2-3个类别标签,而不是所有的图片都发这个标签。
我会集中在两个大的标签类别和1-2个小的标签类别,两个大的标签类别分别是“素食”和“假期/美好生活”。小的标签类别是属于自然风光(是我的家乡,德国)。
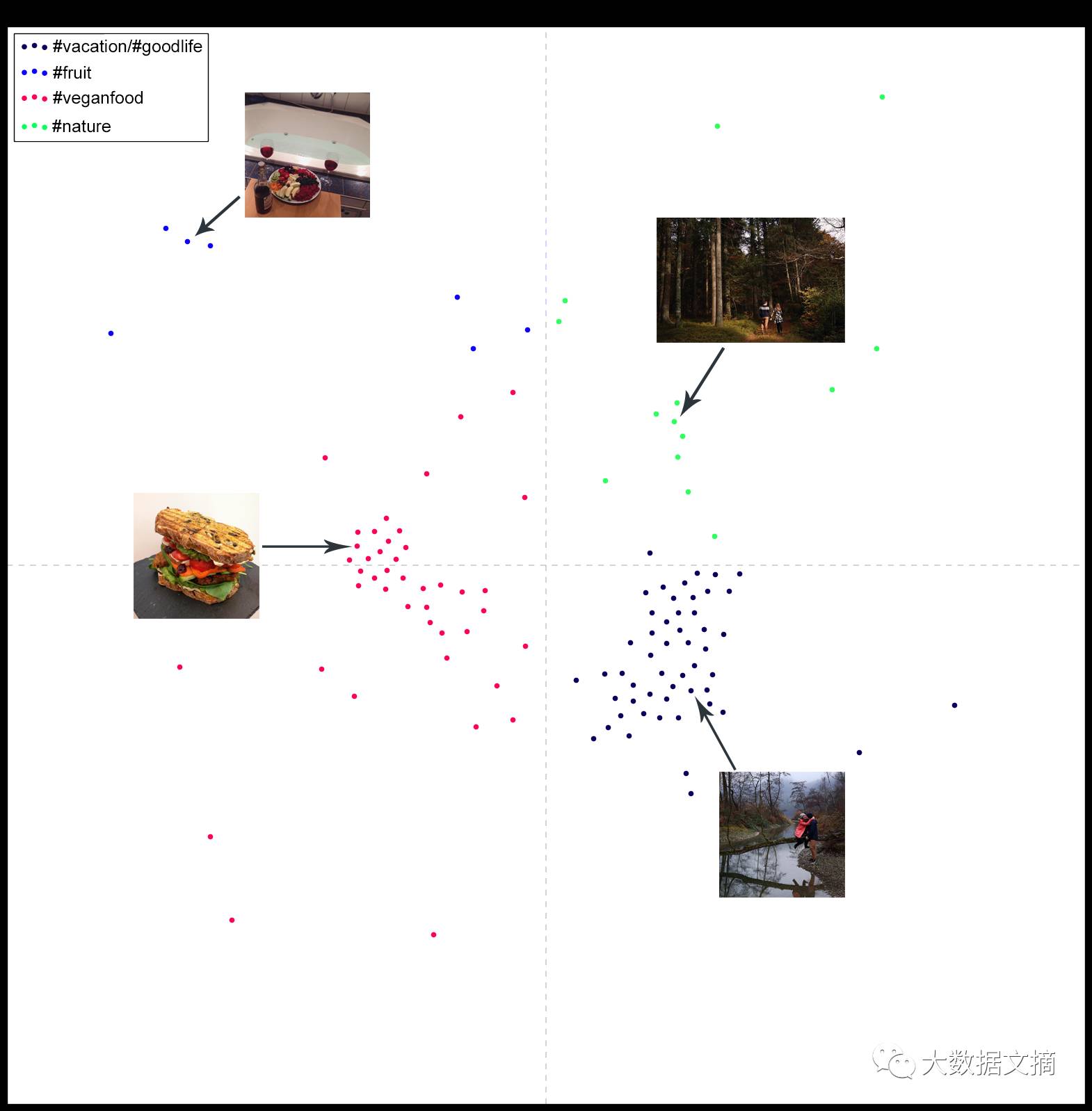
标签集合
真正受到我的程序影响的不仅仅是我的部分粉丝,而且我的真正的活动也会影响新的粉丝。我决定收集每个帖子里的zan和评论,然后将结果整理之后,得出以下图表:
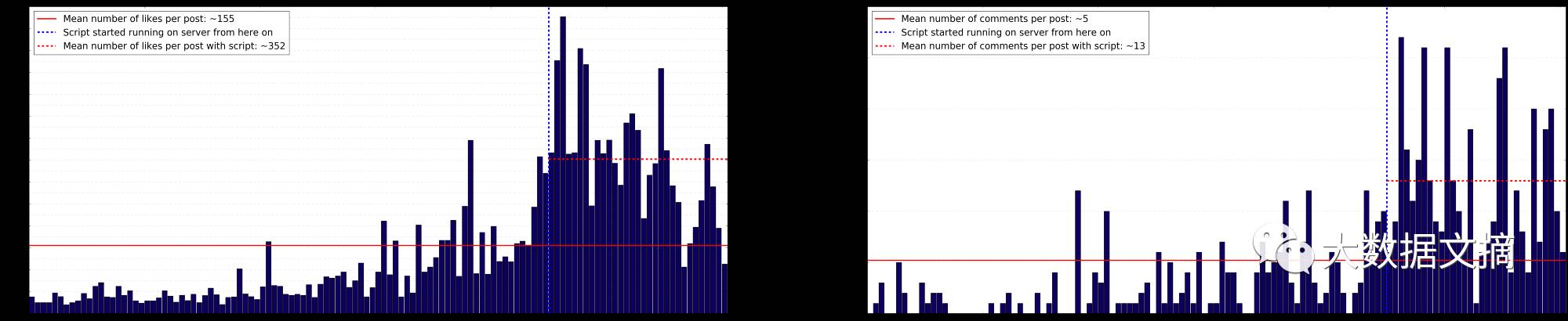
每篇帖子里的zan和评论
在上图中,当我在服务器上开始运行脚本时绘制了一条垂直线,如果你将红线、红虚线内和图表中的数值进行比较,就会发现数值增长了数倍。
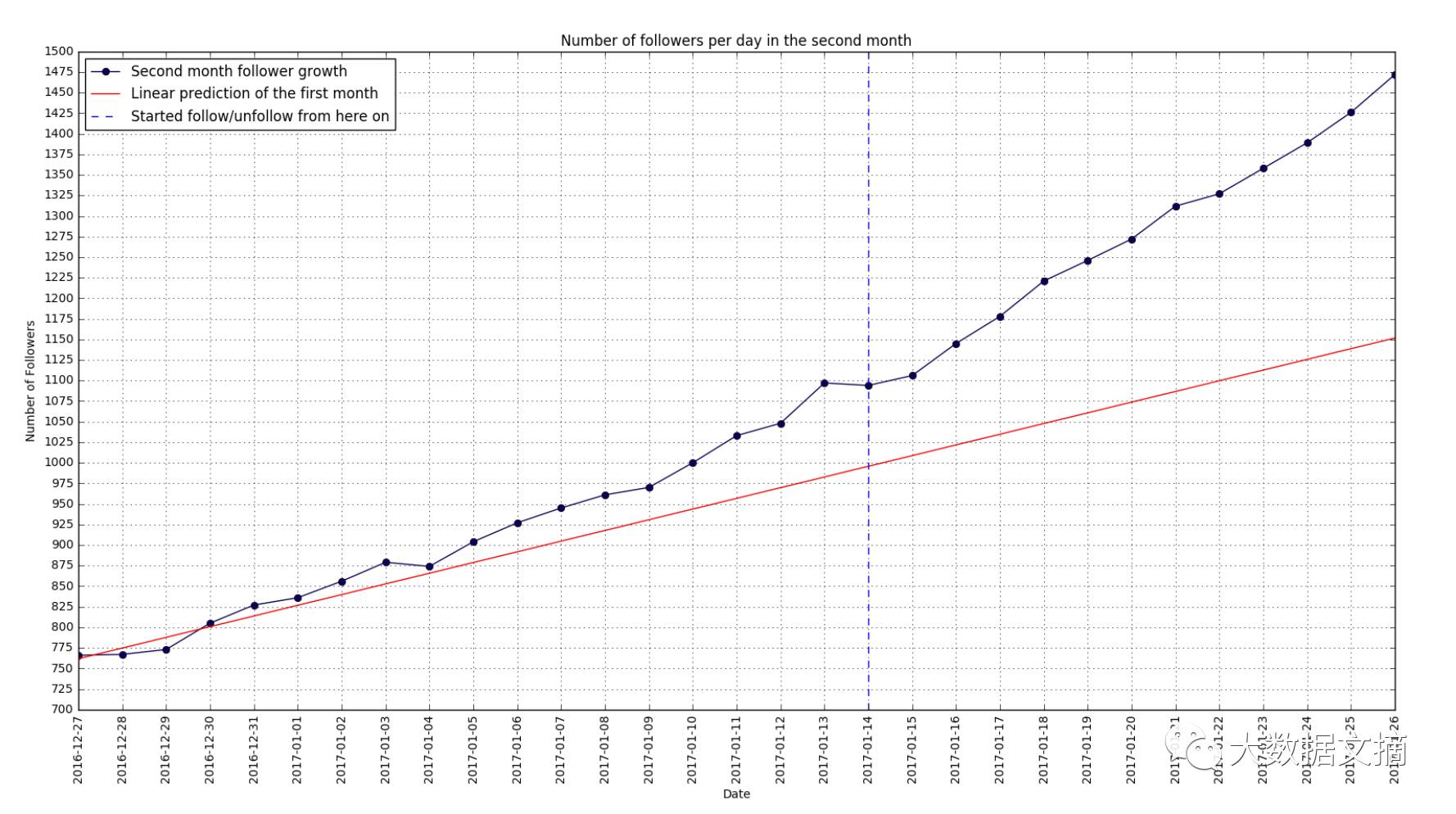
在第二个月里每天粉丝的数量
然后我将关注和没关注的粉丝数量追踪功能添加到我的InstaPy 脚本程序里,我对它有如此大的影响感到非常惊讶!
下图是我醒来之后的7个小时内没有登录Instagram的成果:
我醒来之后查看的Instagram
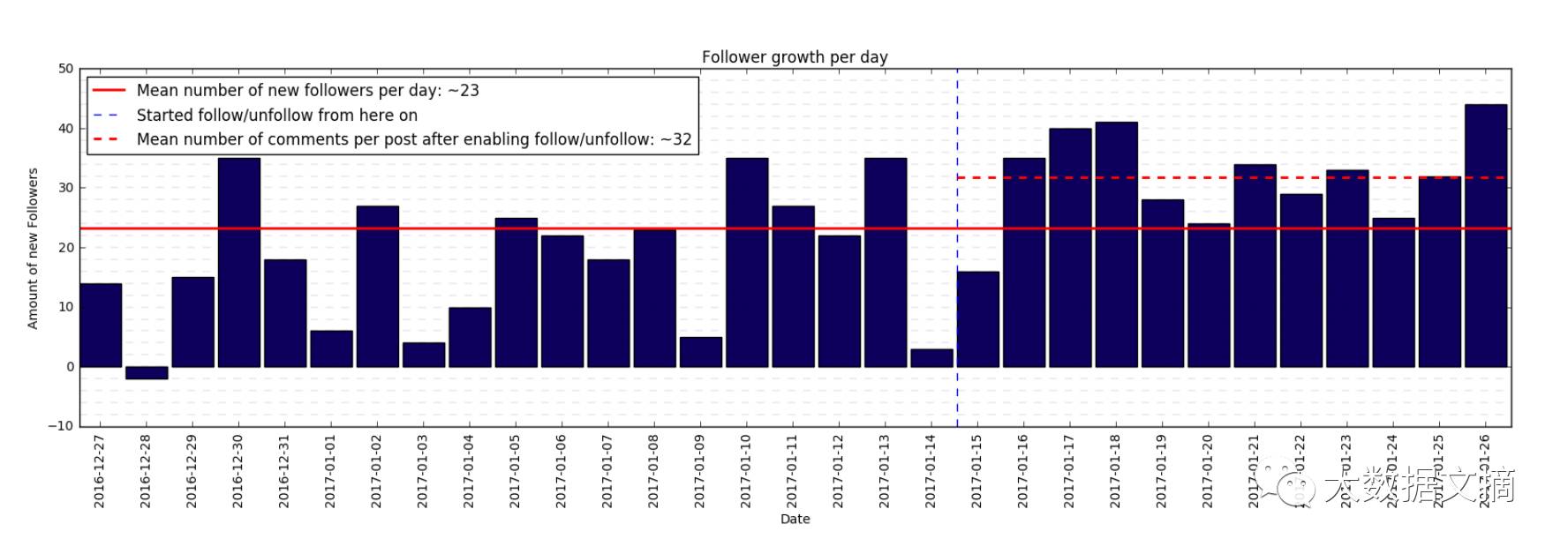
在第二个月里每天增长的粉丝数量
从第一个月里的每天增长13个新粉丝和第二个月里每天增长23个新粉丝的情况看来,我们可以证实猜想:那就是你拥有的粉丝越多,你就越能快速的吸引更多的粉丝。
让我印象比较深刻的是,无论我的吸引粉丝策略影响有多强,我在喜欢的博主发表的帖子上收获新的粉丝数量在23-32个左右,在下一次运行程序的时候他们就会取消关注。
根据我的统计,一个运行脚本程序的INS账户已经获得了5K个粉丝量,每天还会新增70-100个新的粉丝。
老实说,第三个月相比之前并没有什么大的变化,粉丝的增长量甚至比第二个月要低。
我的服务器有出现一些小问题,而且Instagram也改变了网站的布局,导致我的脚本程序无法正常工作,所以我需要解决这个问题,导致我的程序有些天没有运行了。
我的一个账户里读到了一条消息如下:
为什么你关注我了之后又没关注我了?
这个问题是我之前所没有考虑到的,明显的是,我很快就解决了这个问题,因为我觉得这个可能是一个机器账户的群发消息。
我的解决方法是保存了一个我已经关注的账户为模板,然后我可以定义每个被跟踪的账户的最大关注量。
从我的粉丝量在本月达到了2000个的时候,我举办了一个赠礼活动,不仅让我的粉丝量有些许增加,还让我的Instagram账户看上去更加平常(这个单词是“合法的”意思,翻成平常感觉不太准确,但我暂时没有其他更恰当的建议)。

免费赠送两个椰子碗
现在回忆起来,可能最好是将赠品图片放上去,而不是写在描述文字里。
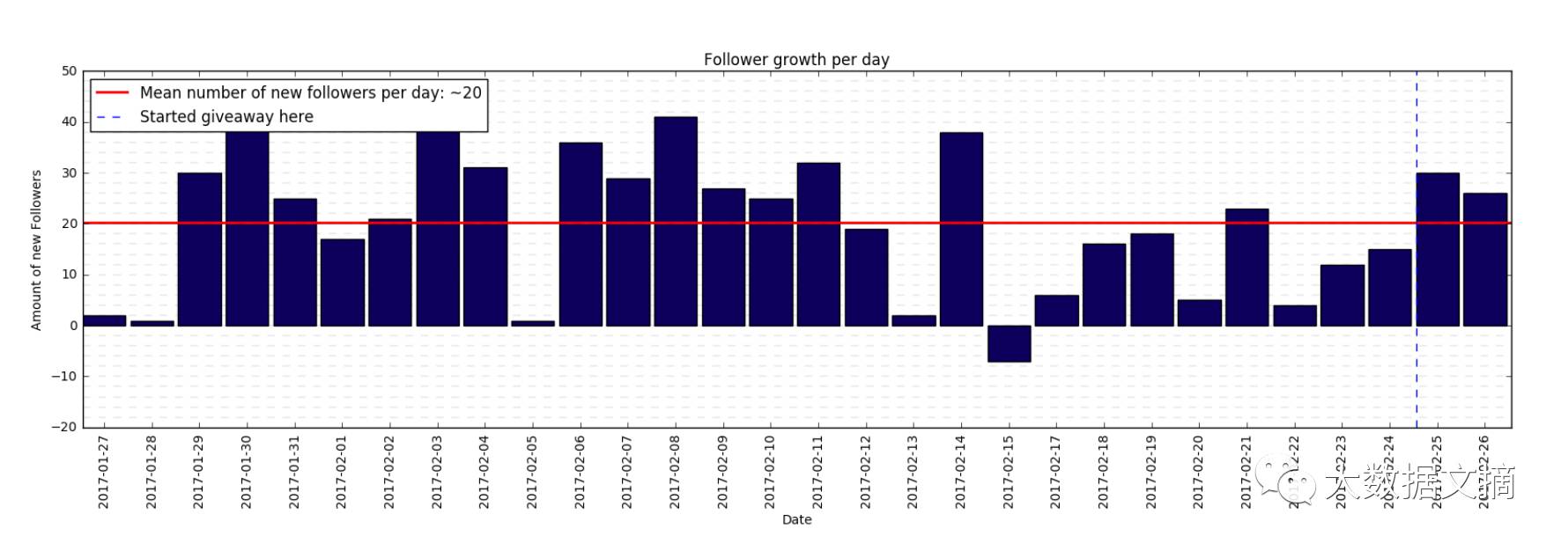
在第三个月里每天增长的粉丝量
从上图里我们可以看到每天新增的粉丝量从32个降到20个。一段时间我的脚本出了点问题,我的新增粉丝量就变少了。但是大部分时候还是很不错的,每天的新增粉丝量可以达到40个。
我们如果将赠品活动前后的新增粉丝量作比较,可以发现每天有28个新增粉丝。
在发布新的图片或视频后,现在我通常会在第一小时内获得100个zan。

Technical Issues技术问题
使用像Selenium这样的GUI测试工具的问题是,如果网站(就我而言是Instagram)在HTML布局方面更改某些内容,我必须改变脚本,并更新从页面中选择的元素。这正是我这个月要学习的东西。
如果您对脚本的工作方式感兴趣,请继续阅读。要不然你可以直接跳到第四个月。
当然,您可以在GitHub的存储库中查看代码,但阅读简短的描述有时更加舒适。所以我们开始吧。
它实际上很简单,Selenium启动一个浏览器窗口,像一个真实的人一样。
然后,您可以使用get方法前往任何页面。
只要你在页面上,你就可以获得页面的元素,例如通过他们的标签名称。所以让我们来假设在HTML中,关注按钮看起来是这样的
我们现在可以使用我们的浏览器来获取按钮元素,例如类
follow_button = browser.find_elementy_by_class_name('_follow')
这就是改变HTML的问题。如果现在Instagram将类从“_follow”更改为“_follow_button”,脚本需要调整。这只是一个小小的改变,但是只需要做一次会更好一些。
一旦我们有了关注按钮,我们只需要调用:
follow_button.click()
现在我们已经在Instagram上关注该用户了。
这种工具的最大任务是通过分析页面的HTML(就我而言是instagram.com)来找到元素的正确路径。
整个脚本分解到最小的部分,只需在每个页面上查找所需的元素,并单击它们或提取其文本即可。
在第四个月,令人遗憾的是,这次增长又只是620个新粉丝。
经过4个月的脚本运行之后,这就是我平均的帖子情况,如下:
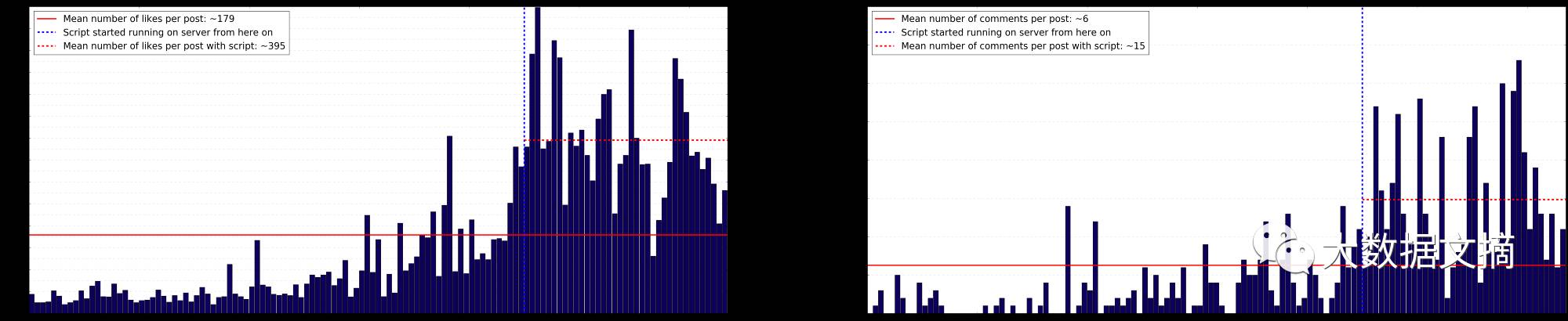
在这里,我们再次看到了脚本的影响之大,甚至在脚本开始之前就已经出现在那里了。
在第四个月开始的时候,我把这个链接发布到我的GitHub repoonReddit上,以便把这个词传播得更广一些,也许还会有一些开发人员帮助我测试它并报告bug。
我得到的是这个问题:
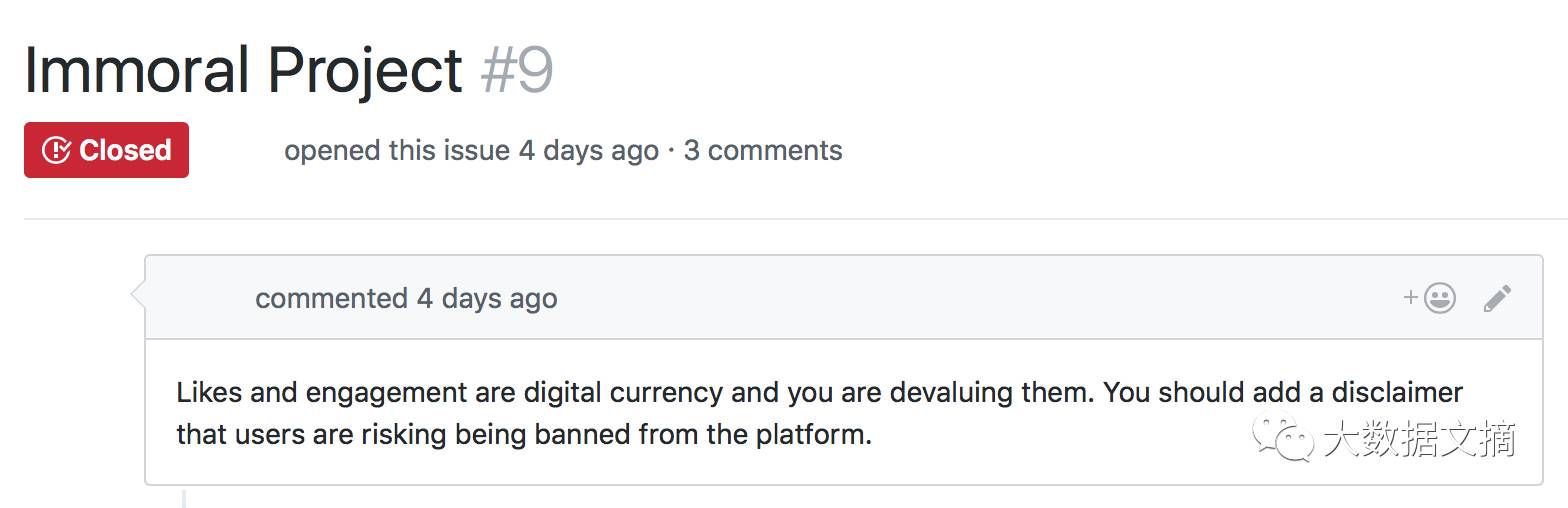
在陈述了我对这个话题的看法之后,(同一个人给我写了这封电子邮件:
,我是那个在InstaPy提出上从糟糕的github问题的人。我为Instagram上的影响者创建了一个平台,叫做******。我们是欧洲最大的影响力平台(或者至少是前三名)。我们在业务方面做得很好,并且我们在冰岛有一个很棒的产品团队。
我对您的InstaPy项目印象深刻。我本身就是Python开发人员,后端是Flask / PostgreSQL / AWS堆栈。我们正在转向单一回购,以更有弹性,并有能力将其后端分解成更小的服务。
你在短期内找工作吗?有兴趣了解您未来的计划。
令我印象深刻的是,即使是这样一个简陋的自动化脚本,我还是成功地引起了他们的注意。
因为我在编写这篇文章的时候,还是博世Bosch工程的实习生,无法考虑加入他们的团队。但是,因为冰岛这里有着美好的大自然和善良的人们,我想有一天在冰岛工作。

由于我想要让这个实验继续运行一段时间,我想到了一种方法:一次付费,这项服务基本上永远运行。
RaspberryPi3似乎非常适合它。它体积小巧,功能强大,价格便宜。
仅仅花费35 $,你就可以获得一个小型的Unix计算机,通过一些修修补补,可以运行Google Chrome。
使用本指南:如何在Raspberry Pi上运行Google Chrome一段时间,我可以在RaspberryPi安装InstaPy,将其启动并运行。
这不仅仅是廉价服务的优势。在检查机器人时,大多数服务都有一个IP数据中心的列表。DigitalOcean和其他基础设施作为服务提供商拥有专用的IP,可追溯到每一个数据中心。
像Raspberry Pi这样的小型计算机在您的家庭网络中运行,并具有与计算机或智能手机相同的IP地址。
The infamous robots.txt
在整理这篇文章的那一刻,我想过不发布它,因为“自动化”一个站点,而不是它的robot.txt - 这个文档告诉机器人,网站所有者更希望他们不要扫描网站的那些部分。
例如,Facebook的robot.txt,从以下几行开始:
# Notice: Crawling Facebook is prohibited unless you have express written permission. See: http://www.facebook.com/apps/site_scraping_tos_terms.php
注意:除非您有明确的书面许可,否则爬取Facebook是被禁止的。 请参阅:http://www.facebook.com/apps/site_scraping_tos_terms.php
有一大堆这样的网站:
Google谷歌
Amazon亚马逊
甚至是Volksbank的当地分支机构
有趣的是,Instagram一个都没有。
这可能有助于我的观察,Instagram上有很多机器人。 Instagram本身并不介意,因为更多的机器人意味着整个系统中的更多活动。
编辑:有人指出,其实Instagram确实有一个robots.txt。你可以在这里查看。
在写这篇文章的时候,我有2,800个粉丝。我打算继续运行我的脚本,直到我在Instagram上被禁止或上升到最高的高度。
不,说真的,我真的有兴趣看看这可以走多远。
当然如果有很大的突破或发现,我会回复你的。
到目前为止,我只花了5美元租了一台服务器。凭借GitHub的“学生背包”的$ 50优惠券,我可以让它多运行5个月,而不用多投一分钱。仅仅35美元的RapsberryPi3可能永远运行着。
如果你进入RaspberryPi,还可以获得一个Model3,并安装所有必要的工具,让它在那里运行一次,费用约为$ 35。这就是我在第四个月所做的。如果您有兴趣,请查看如何在RaspberryPi上运行Google Chrome。
另外,在达到2000个粉丝的时候,我花了大约16美元来运送赠品。
所以,没有额外的东西,它只是5美元。如果我们包括所有的费用(包括我没有支付的费用),我会支付100美元来永远运行它。
注意:如果要使用python开始自动化,请务必查看“自动化这个无聊的东西”!
每一个人。我是认真的。即使你不想在服务器上安装与运行,也可以轻松下载脚本并手动运行。
有很多专业的服务与我的脚本做的事情完全一样。唯一的区别是,他们花费了相当多的钱(像FollowLiker的100美元)。我的是免费的。
我还添加了一个快速启动文件,您只需输入一些简单的信息即可。
InstaPy(username='test', password='test')\
.login()\
.set_do_comment(True, percentage=10)\
.set_comments(['Cool!', 'Awesome!', 'Nice!'])\
.set_dont_include(['friend1', 'friend2', 'friend3'])\
.set_dont_like(['food', 'girl', 'hot'])\
.set_ignore_if_contains(['pizza'])\
.like_by_tags(['dog', '#cat'], amount=100)\
.end()
如果您对每行内容都感到好奇,请查看GitHub上的文档。
如果您再多花些时间,您就可以检查我的分步指南,了解如何安装selenium自动化的服务器。
如果你喜欢我所做的,请考虑在GitHub,Instagram和YouTube上关注我。确保一定要在GitHub:P上展示。
谢谢你的阅读。我很好奇你是怎么想的,所以请给我一些意见。










