作者 | Alex Kendall
编译 | KK4SBB
如今,深度学习已颠覆计算机视觉领域,端到端的深度学习模型几乎是任何问题的最佳解决方案。尤其是卷积神经网络(CNN),因为它效果拔群而广受欢迎。可是,这些深度学习模型都像是一个个黑盒子,盒子内的奥秘仍然不为人所知。笔者认为,现在的研究人员只是简单地写少量代码来调用深度学习接口,尽管这种直白的使用方式能解决大多数计算机视觉问题,但是最终效果显然还存在更大的提升空间。
PoseNet(http://mi.eng.cam.ac.uk/projects/relocalisation/)
是我曾经开发的一种使用深度学习技术判断摄像头姿态的算法。这是计算机视觉领域的一个经典问题,并且有非常完整的相关理论研究。当时用深度学习训练了一个端到端的模型,这个模型取得了很好的效果。可是,现在回想,觉得当时自己完全忽略了这个问题的已有理论背景。在本文的末尾作者补充了相关工作的最新进展,从更偏向理论的角度重新审视了问题,并用基于几何的方法取得了巨大的效果提升。
简单地调用深度学习接口就能解决问题的时代即将结束,计算机视觉领域的下一次进步将源自对几何形态的深入研究。
在计算机视觉领域,几何描述这个世界的结构和形状,涉及深度、体积、形状、姿态、视差、运动和光流等测量角度。
几何在视觉模型中地位较高的原因在于几何定义了这个世界的结构,而且我们人类能理解这种结构(比如,从经典的
教科书(http://www.robots.ox.ac.uk/~vgg/hzbook/)
中学习)。因此,有很多复杂的几何关系并不需要利用深度学习技术从头学起,比如,物体的深度和运动状态等。通过使用已有的几何知识构建体系结构,我们可以将它们对应到现实中,简化了学习过程。本文结尾的一些示例将介绍如何使用几何来提高深度学习架构的性能。
另一种范式是使用语义表示。语义表示指的是用语言来描述物体在现实中的关系。例如,我们可以将物体描述为“猫”或“狗”。但是,几何在语义上有两大特性:
-
几何形态可以直接观察。人们直接用视觉观察这个世界的几何形态。在最基本的层面上,人们可以通过追踪帧与帧之间相应像素的关系来直接观察物体的运动状态和深度情况。另外一些有趣的例子,包括根据阴影观察形状或是从立体视差推测深度。与此相反,语义表示是人类语言所特有的,每个标签对应于一个名词实体,无法直接观察。
-
几何是基于测量的连续变量。例如,人们可以用“米”来度量深度或是用像素来衡量视差,而语义表征则是离散量或二值标签。
为什么这些属性很重要呢?其中一个重要的原因在于这些属性对无监督学习非常有帮助。
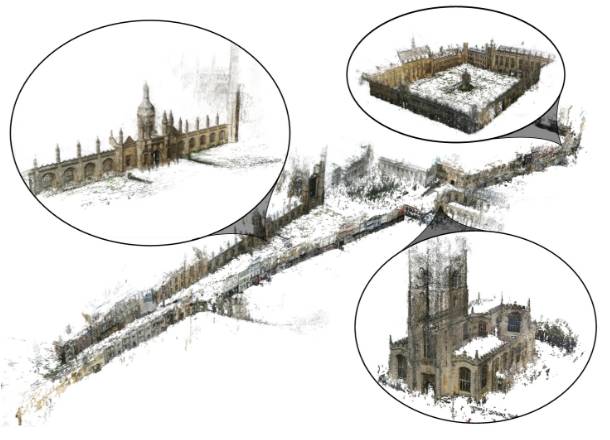
英国剑桥中心,几何结构的运动重建,来自于手机的视频拍摄
无监督学习无需标注数据就能学习物体的表示和结构。获取大量的已标注训练数据需要耗费财力物力,因此无监督学习提供了更具扩展性的框架。
作者上面提到几何学的两个特性正好可以用来训练无监督学习模型:可观察性和连续表示。
例如笔者去年发表的一篇
作品(https://arxiv.org/abs/1603.04992)
,介绍了如何利用无监督训练和几何形态来预测物体的深度,这篇论文给出了几何学原理与上述两个特性结合形成无监督学习模型的绝佳案例,也有几篇思路类似的
论文(https://arxiv.org/abs/1505.01596)
。
语义在计算机视觉领域一直备受关注,许多高引用论文成果都来自图像分类和语义分割领域。
仅依靠语义来设计一套表达方式会存在问题,因为语义是由人类定义的。人工智能系统理解语义并提供与人类交互的接口必不可少,而语义是人类定义的,很有可能这种定义并不是最合理的定义方式。直接从观察到的几何世界学习可能更自然。
与此同时,低层次的几何形态也是婴儿学习观察世界的形式。根据
美国眼科协会
的调查,人类在出生后的前九个月学习协调眼睛的聚焦和感知深度、颜色和几何形状等属性。直到第十二个月才学会如何识别物体和语义。这说明在人类视觉中学习几何学的基础是非常重要的,人类会很好地把这些洞察融入到计算机视觉模型中。

机器眼中的世界(SegNet)。每种颜色表示不同的语义类别,比如道路、人行道、交通标志等等。
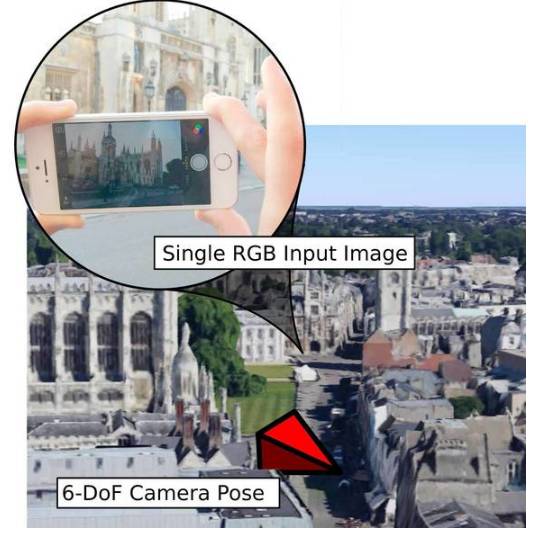
使用PoseNet重定位
PoseNet
是一种单目六自由度的重定位算法。此算法可以解决著名的
“被绑架的机器人(https://en.wikipedia.org/wiki/Kidnapped_robot_problem)”
问题。
在
ICCV 2015
上发表的第一篇论文中,笔者通过训练端到端的映射模型来解决此问题,将输入图像映射到六自由度的照相机姿态。此方法把整个问题看做一只黑盒。在今年
CVPR
发表的论文(https://arxiv.org/pdf/1704.00390.pdf)中,有用几何学原理做了改进,不再将学习照相机姿态和方向作为两个独立的回归目标,而是用几何重投影误差联合训练。效果得到了显著提升。
立体视觉深度预测
立体算法通常是指通过观察两幅校准图像对之间的差异来获得人造立体效应的过程。这就是所谓的视差,它在相应的像素位置与场景深度成反比。因此,基本上可以将问题简化为一个匹配问题,即从左、右图像分别找到对象之间的对应关系,以此来计算深度。
最先进的立体算法还是以深度学习技术为主导,但也仅用于构建匹配特征。深度估计所需的匹配和正则化步骤还未用到深度学习。
笔者从几何学的角度提出了
GC-Net(https://arxiv.org/pdf/1703.04309.pdf)
网络结构。众所周知,我们可以利用沿着单目视差线构成的cost volume来估计视差。该文的新颖之处在于如何用回归模型来对cost volume的几何形状建模。更多细节可以参考这篇
论文(https://arxiv.org/pdf/1703.04309.pdf)
。
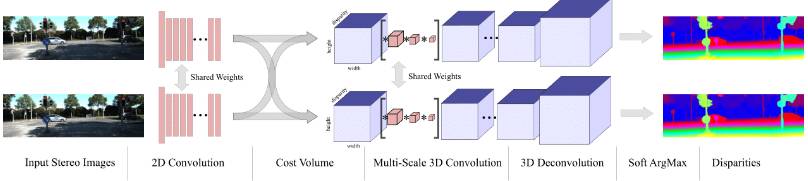
GC-Net结构图,它利用几何形状的显示表示来预测深度。
本文的主要内容可以归纳为以下两点:
原文链接:
http://alexgkendall.com/computer_vision/have_we_forgotten_about_geometry_in_computer_vision
在线直播 | 人工智能核心技术解析与应用实战峰会
由CSDN学院倾力打造,力邀一线公司技术骨干做深度解读。
五一特惠:199元即可听6位技术专家的在线分享,优惠价将于5月2日结束,扫描下方二维码报名:






