
原文来源
:DeNA
「雷克世界」编译:嗯~是阿童木呀、KABUDA、EVA
导语:熟悉二次元的小伙伴一定对动漫人物的换装和姿势变化不陌生。而最近,日本网络游戏公司DeNA提出了一种渐进式结构条件生成式对抗网络(Progressive Structure-conditional Generative Adversarial Networks,PSGAN),这是一种新的框架,可以根据姿势信息(pose information)生成全身和高分辨率的动漫人物图像。接下来,我们就来看一下PSGAN是如何生成全身动漫人物,并为其添加新的姿势动作的。
最近在具有层次结构和渐进式结构的生成式对抗网络(generative adversarial network,GAN)方面所取得的进展使生成高分辨率图像成为可能。然而,现有的方法在对工业应用来说很重要的生成结构化对象(例如,全身人物)方面存在局限性。另一方面,虽然已经提出了可以基于结构化条件(例如,姿势和面部标志)生成图像的GAN,但是它们的图像质量不足。为了解决上述的局限性,我们引入了一个PSGAN,它在训练过程中使用结构化对象逐步提高生成图像的分辨率,以生成结构化对象(例如,全身人物)的详细图像。此外,我们还在网络上施加任意的潜变量(latent variable)和结构条件,以便根据目标的姿势序列(pose sequence)生成不同的、可控制的视频。在本文中,我们通过实验证明了这种方法的有效性,展示了具有详细的、以姿势为条件的动漫人物的512x512视频生成实验结果。
生成结果概述
我们展示了由PSGAN生成的各种动漫人物和动画的例子。我们首先使用PSGAN从随机潜变量中生成许多动漫人物。接下来,我们通过插入与动漫人物相对应的潜值(latent value)来生成新的动漫人物。然后,用连续的姿势序列生成内插的动漫人物的动画。
生成新的全身动漫角色
我们通过使用PSGAN插入与不同服饰的动漫人物(人物1和2)相对应的潜值,从而生成一个新的全身动漫角色。请注意,这里只施加了一个姿势条件。

将动作添加到生成的动漫人物
下面展示了带有指定动漫人物和目标姿势的动画生成示例。
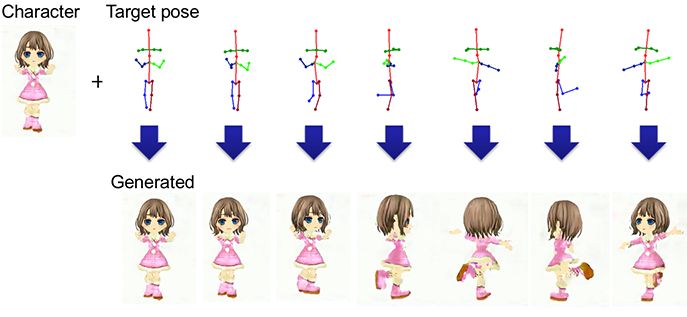
通过固定潜变量,并给PSGAN提供连续的姿势序列,我们可以生成人物的动画。更具体地说,我们将指定动漫人物的表征映射到作为PSGAN输入向量的潜空间中的潜变量中。
通过将指定动漫人物映射到潜空间并生成作为PSGAN输入的潜变量,生成带有指定动漫人物的任意动画。
近来,科学家们已经在使用深度生成式模型进行自动图像和视频生成方面进行了研究。可以说,这些研究对于诸如照片编辑、动画制作和电影制作等媒体创建工具来说意义重大。
专注于动漫创作(anime creation)、自动角色生成可以激发专家去创造新的角色,同时也有助于降低绘制动漫的成本。
Yanghua Jin、Jiakai Zhang、Minjun Li、Yingtao Tian和Huachun Zhu所著的《使用生成式对抗网络实现高质量动漫人物的生成》,聚焦于使用GAN架构实现动漫人物人脸的图像生成。然而,尚未提出全身性人物的生成(full-body character generation)。
可以这样说,专家们提出的是仅仅聚焦于人脸图像的动漫人物图像的生成,但其质量并不满足制作动漫的要求。
自动生成全身性的角色,并向其添加高质量的动作,这对于制作新角色和绘制动漫来说具有非常大的帮助。因此,我们致力于生成全身性的人物图像并为它们添加高质量的动作(例如视频生成)。
将全身性人物生成应用于动漫制作中仍然存在两个问题:(i)具有高分辨率的生成,(ii)具有特定姿势序列的生成。
可以这样说,作为一个适用于各种图像生成任务的框架,生成式对抗网络(GAN)是一个最有发展前景的候选方法之一。最近,在具有分层结构和渐进结构的GAN方面所取得的进展实现了高分辨率、详细的图像合成和文本—图像的生成。然而,高质量生成的应用仍然只局限于一些对象,如面部和鸟类。对于GAN来说,生成具有全局结构的结构的对象是一个很大的挑战,而对于具有高分辨率的生成来说也是如此。另一方面,科学家们还提出了具有结构化条件的GAN,如姿势和面部标志。但是,他们的图像质量还有很多的不足之处。
我们提出了渐进式结构条件GAN(Progressive Structure-conditional GAN,PSGAN)来解决这些问题。我们展示了PSGAN能够以512x512的分辨率生成具有目标姿势序列的全身性的动漫人物和动画。当PSGAN生成具有潜变量和结构条件的图像时,PSGAN就能够生成具有目标姿势序列的可控制动画。
渐进式结构条件性GAN
我们的主要思想是渐进式地学习具有结构条件的图像表示。PSGAN提高了具有结构条件的生成图像在每个尺度上的分辨率,并生成了具有详细姿势条件的高分辨率图像。我们采用与Zizhao Zhang、Yuanpu Xie和Lin Yang所著的《使用层次嵌套对抗网络实现摄影文本到图像的综合》中相同的图像生成器和鉴别器体系结构,除了我们所提出的通过添加具有相应分辨率的姿态图,在每个比例的生成器和鉴别器上施加结构条件。
利用所提出的网络体系结构,图像生成通过相应的条件图渐进式的从低分辨率层到高分辨率层进行执行,这显著地稳定了训练。这种增加使得对于生成器和鉴别器结构在每一种NxN分辨率下进行的训练都是渐进式结构条件化的,并稳定稳定了对结构条件式生成的训练。
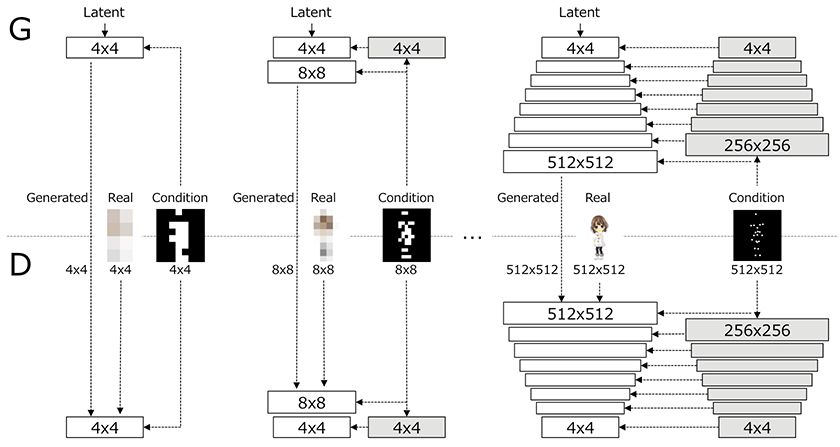
PSGAN的Generator(G)和Discriminator(D)体系结构。NxN白色框代表在NxN空间分辨率下操作的可学习卷积层。N×N灰色框代表结构条件的不可学习的下采样层,这将结构条件图的空间分辨率降低到N×N。
训练数据准备
在本节中,我们将描述我们的数据集准备方法。对于PSGAN,我们需要成对的图像和关键点坐标。我们准备了由Unity合成的原始变身动漫人物(avatar anime-character)数据集,以及由Openpose检测到的关键点的DeepFashion数据集。
Avatar Anime-Character数据集
我们构建PSGAN的新数据集,满足三个要求:
1.姿势多样性。为了生成平滑和自然的动漫,我们准备了各种各样的姿势条件。
2.训练图像的数量。通过使用Unity生成3D建模的虚拟头像,无需任何手动注释就可以获得具有关键点图的无限数量的合成图像。
3.背景消除。我们将背景颜色设置为白色并擦除不必要的信息,以避免对图像生成产生负面影响。
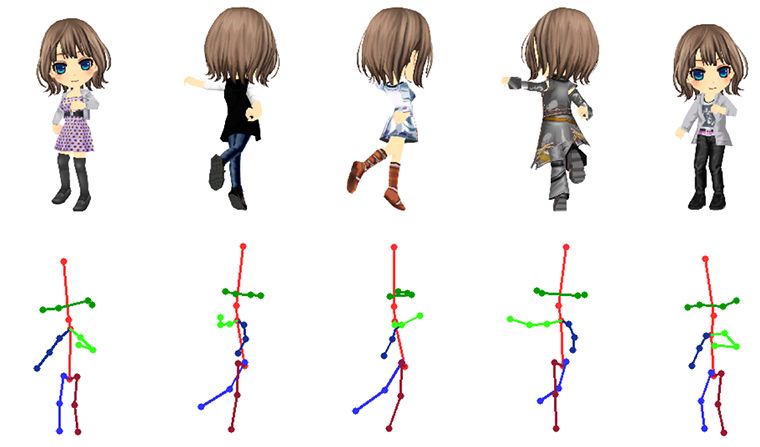
我们将一个变身的几个连续动作分成600个姿势,并捕捉每个姿势的关键点。我们对79种服装进行了这样的处理,总共获得了47,400张图像。我们还根据3D模型的骨骼位置获得了20个关键点。
下图显示了训练数据的样本。动漫角色(顶行)和姿势图片(底行)。
DeepFashion数据集
PSGAN利用姿态信息在图像生成网络上施加结构条件。我们使用Openpose从没有关键点注释的图像中提取关键点坐标。关键点的数量是18,并且省略了少于10个检测到的关键点的样本。缺少的关键点填充-1,其他关键点设置为1。
训练设置实验
我们使用与《用于提高质量、稳定性和变化的GAN的渐进式生长》相同的舞台设计和损失函数。我们展示了每阶段鉴别器的600K真实图像和结构条件,并使用了n_critic=1的WGAN-GP损失。为了节省CPU内存,在4×4 -128×128图像生成阶段,我们令minibatch size为16,并分别将256×256图像和512×512图像的生成器,减少至12个和5个。
我们使用M个通道来表示M个关键点的结构条件。在每个通道中,一个像素在对应的关键点上填充1,而在其他位置上填充-1。对于每个N×N分辨率,我们使用内核大小(kernel size)为2和步长(stride)为2的最大池化(max-pooling)作为结构条件的还原层(reduction layers)。
Avatar Anime-Character数据集
:我们使用Adam训练网络,其中β1=0,β2=0.99。我们在4×4-64×64图像生成阶段使用α=0.001,并将其逐渐降低至128×128图像的α=0.0008,256×256图像的α=0.0006以及512×512图像的α=0.0002。姿势关键点(pose keypoints)的数量是20。
DeepFashion数据集
:我们使用Adam(α=0.0008,β1=0,β2=0.99)对各阶段的网络进行训练。姿势通道(pose channels)的数量为18。
PSGAN、PG2、Dinentange PG2和渐进式 GAN之间的比较
本文中,我们研究了PSGAN生成图像的多样性。下图展示了PSGAN生成的图像,其中潜变量(latent variables)是随机设置的。PSGAN为每个姿势条件(pose condition)生成各种各样的图像。

接下来,我们评估了PSGAN的再现性(reproducibility),并与以姿势为指导的人的图像生成(Pose Guided Person Image Generation,PG2)]和分离的人的图像生成(Disentangled Person Image Generation,DPG2)进行了比较。PG2和DPG2需要源图像和相应的目标姿势,以将源图像转换为具有目标姿势结构的图像。同时,PSGAN根据潜变量和目标姿势生成具有目标姿势结构的图像。与PSGAN相比,PG2和DPG2更易受到源图像和相应目标姿势的影响。
下图展示了PSGAN、PG2和DPG2的生成图像。我们省略了PG2和DPG2的输入图像。从中我们可以观察到,由PSGAN生成的图像与由PG2和DPG2生成的图像一样自然、真实。由于PSGAN也是由潜变量生成图像,因此,从理论上讲,PSGAN可以和PG2和DPG2一样,生成多种多样的图像。

最后,我们评估了PSGAN与渐进式 GAN的结构一致性。下图是渐进式GAN和PSGAN生成图像的比较。我们发现,渐进式GAN无法生成由其整体结构组成的结构目标的自然图像。另一方面,PSGAN可以通过在每个度量上施加结构条件,来生成由其整体结构(例如:左侧两幅图)组成的近乎真实的图像。

结论
本文展示了由PSGAN生成的流畅、高分辨率动画。我们表明,PSGAN可以在512×512目标姿势序列的基础上,生成全身动漫人物和动画。在训练过程中,PSGAN可通过改善每个尺度上的结构条件,逐渐提高生成图像的分辨率,并为结构化对象(例如:全身人物)生成详细图像。由于PSGAN生成的图像具有潜向量(latent vectors)和结构条件,因此PSGAN能够生成具有目标姿势序列的可控制动画。我们的实验结果表明,PSGAN可以根据随机潜变量生成多种动漫人物,并以连续的姿势序列为结构条件,使动画更加流畅。由于实验环境有限,例如一个化身和几个动作,我们计划在不同条件下继续进行实验和评估。





