|
|
专栏名称: 3d tof
| 为国产ToF崛起奋斗 |
目录
相关文章推荐

|
新加坡眼 · 离谱!外籍女子在樟宜机场过境区连偷4家店 · 昨天 |

|
新加坡眼 · 新加坡又一男子公然拿1万新币假钞存银行! · 2 天前 |

|
新加坡眼 · 春节期间超市的猪肉都会换新名,大家发现了嘛? · 2 天前 |

|
新加坡眼 · 突发!字节跳动要求新加坡的中国籍员工必须向中国报税 · 2 天前 |

|
青塔 · 财经大学,迎来新校长! · 4 天前 |
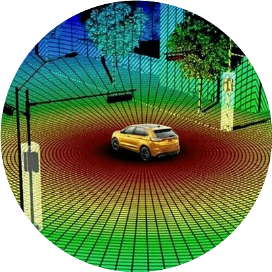
CVPR 2023 | Depth Estimation from Cam Image and mmWave Radar PCD
3d tof · 公众号 · · 2024-10-29 18:00
推荐文章
|
|
新加坡眼 · 离谱!外籍女子在樟宜机场过境区连偷4家店 昨天 |
|
|
新加坡眼 · 新加坡又一男子公然拿1万新币假钞存银行! 2 天前 |
|
|
新加坡眼 · 春节期间超市的猪肉都会换新名,大家发现了嘛? 2 天前 |
|
|
新加坡眼 · 突发!字节跳动要求新加坡的中国籍员工必须向中国报税 2 天前 |
|
|
青塔 · 财经大学,迎来新校长! 4 天前 |

|
毒药 · 宝强战马蓉、冠希斗志玲、曹金撕郭纲……2016中国娱乐圈10大超级PK丨毒药盘点 8 年前 |

|
ONE一个 · 你喜欢的人叫什么名字? 7 年前 |

|
柳林大小事 · 中阳:老公晚上和别的女人聊微信,还把我的头打破 7 年前 |

|
互联网聚焦 · 三星在中国陨落,国产崛起! 7 年前 |

|
木棉说 · 爸妈再苦再难,都要把孩子带在身边 7 年前 |