来源:机器之心(ID:
almosthuman2014
)
本文
389
0
字23图
,建议阅读
10
分钟
。
本文介
绍了在应用
生成对抗网络(GAN)合成图像时如何避免遗漏情况从而打造出更加高质量的图像生成器,包括相关论文、代码和数据。
【导读】
生成对抗网络(GAN)现在已经能合成极具真实感的图像了,但 MIT、IBM 和香港中文大学的一项研究表明 GAN 在合成图像时会遗漏目标分布中的一些细节。未来的 GAN 设计者如果能够充分考虑这种遗漏情况,应该能够打造出更加高质量的图像生成器。研究者已经公布了相关论文、代码和数据。
论文:
https://arxiv.org/abs/1910.11626v1
项目:
https://ganseeing.csail.mit.edu
生成对抗网络(GAN)在合成逼真的图像方面能力出色,但我们不禁要问:
怎样才能知道 GAN 无法生成的东西呢?
模式丢失或模式崩塌被视为 GAN 所面临的最大难题之一,此时 GAN 会忽视目标分布中的某些部分,然而对于 GAN 中的这一现象,当前的分析工具所能提供的见解非常少。
MIT 的这项研究在分布层面和实例层面对模式崩塌进行了可视化。
首先,作者部署了一个语义分割网络,以比较生成的图像与训练集的目标分布中经过分割的目标的分布。
统计数据的差异能够揭示 GAN 忽视的目标类别。
图 1a 展示了在一个教堂 GAN 模型中,相比于训练分布,人、车和栅栏等目标类别在生成分布中出现的像素更少。
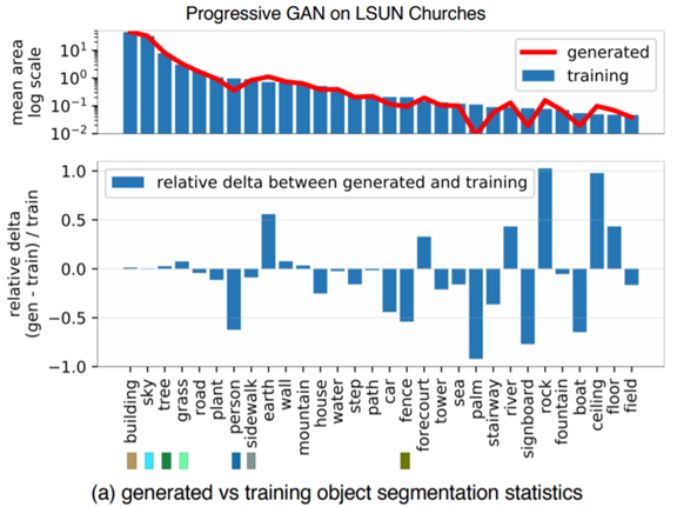
图 1:
看 GAN 不能生成什么:
(a)作者比较了 LSUN 教堂训练集中的目标分割分布与生成结果的分布:
生成器丢弃了人、车和栅栏等目标。
(b)一张真实图像及其重建图像的比较,其中一个人和栅栏的实例无法生成。
每组图中,左上角的是真实照片,右上角的是生成的重建图像,下面两张是各自的分割映射图。
然后,给定识别出的省略过的目标类别,作者对 GAN 的遗漏情况直接进行了可视化。
具体来说,作者比较了各张照片与 GAN 逆推出的相近图像之间的具体差异。
为了做到这一点,作者放宽了逆推问题的限制,并且求解的是易于解决的逆推 GAN 一个层(而非整个生成器)的问题。
在实验中,作者应用这种框架分析了在不同场景数据集上训练的几种近期的 GAN。
作者惊讶地发现,丢失的目标类别并没有发生畸变、渲染得质量很差或渲染成了噪声。
相反,它们实际上完全没有渲染,就好像这个物体不是该场景的一部分一样。
图 1b 给出了一个示例,可以看到,较大的人像被完全跳过了,栅栏的平行线条也被完全忽略。
因此,GAN 可能忽视太难处理的类别,同时又能得到平均视觉质量较高的输出。
相关代码、数据和其它信息参见:
ganseeing.csail.mit.edu.
量化分布层面的模式崩塌
GAN 的系统误差可通过利用场景图像的层次结构来分析。
每个场景都可以自然地分解为目标(object),这样可以通过估计组成目标统计数据的偏差来估计与真实场景分布的偏差。
举个例子,渲染卧室的 GAN 也应该渲染一些窗帘。
如果窗帘的统计数据与真实照片的统计数据存在偏差,那么我们就知道可以通过检查窗帘来查看 GAN 的具体缺陷。
为了实现这一想法,作者使用了 [44] 提出的统一感知解析网络来分割所有图像,这会用 336 个目标类别中的一个类别来标记图像的每个像素。
对于每个图像样本,作者收集了每个目标类别的总像素区域,并收集了所有被分割目标类别的均值和协方差统计数据。
作者在一个大型生成图像集以及训练集图像上采样了这些统计数据。
作者将所有目标分割的统计数据称为「生成图像分割统计数据(Generated Image Segmentation Statistics)」。
图 2 可视化了两个网络的平均统计信息。
在每张图中,每个生成目标类别的平均分割频率都与真实分布的情况进行了比较。
图 2:
使用生成图像分割统计数据来理解在 LSUN 卧室数据集上训练的两个模型的不同行为。
因为大多数类别都不会出现在大多数图像上,所以作者按降序对类别进行了分类,然后重点关注了其中最常见的类别。
这种比较可以揭示很多当前最佳模型之间的许多具体差异。
分析使用的两个模型都是在同一图像分布(LSUN 卧室集)上训练的,但 WGAN-GP 与真实分布的差距比 StyleGAN 与真实分布的差距要大得多。
使用单个数值总结分割的统计差异也是可能的。
要做到这一点,作者定义了 Frechet 分割距离(FSD),这类似于常用的 Frechet Inception 距离(FID)度量,但 FSD 是可解释的:
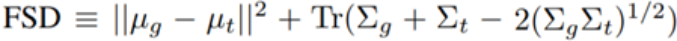
其中,µ_t 是一个训练图像样本上每个目标类别的平均像素数,Σ_t 是这些像素数量的协方差。
类似地,µ_g 和 Σ_g 反映了生成模型的分割统计情况。
作者在实验中比较了 10000 个生成样本和 10000 张自然图像的统计情况。
生成图像分割统计数据衡量的是整个分布:
比如它们能够揭示生成器忽略特定目标类别的情况。
但是,它们并不单独排除应该生成某个目标但却没有生成的特定图像。
为了得到进一步的见解,需要一种可视化生成器在每张图像上的遗漏情况的方法。
量化实例层面的模式崩塌
为了解决上述问题,作者比较了图像对 (x, x'),其中 x 是真实图像(包含 GAN 生成器 G 遗漏的特定目标类别),x' 是在可由 GAN 模型层生成的所有图像的空间上的投射。
在理想情况下,能够找到由生成器 G 完美合成的图像,并使之与真实图像 x 保持较近的距离。
用数学语言来说,目标是找到
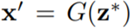 ,其中
,其中
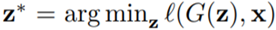 ,l 是图像特征空间中的距离度量。
不幸的是,由于 G 中层数较多,之前的方法都无法解决生成器的这个完全逆推问题。
因此,作者转而求解这个完全逆推问题的一个可解决的子问题。
作者将生成器 G 分解成了层:
,l 是图像特征空间中的距离度量。
不幸的是,由于 G 中层数较多,之前的方法都无法解决生成器的这个完全逆推问题。
因此,作者转而求解这个完全逆推问题的一个可解决的子问题。
作者将生成器 G 分解成了层:
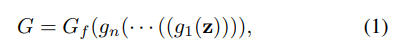
其中 g_1, ..., g_n 是生成器的几个早期层,G_f 是将 G 的所有后期层组合到一起。
任何可由 G 生成的图像都可由 G_f 生成。
也就是说,如果用 range(G) 表示可由 G 输出的所有图像的集合,那么有 range(G) ⊂ range(G_f )。
也就是说,G 无法生成任何 G_f 不能生成的图像。
因此,在 range(G_f ) 中可以确定的任何遗漏情况也都是 range(G) 遗漏的地方。
因此,对于层逆推而言,作者通过更简单地逆推 G_f 的后期层实现了对遗漏情况的可视化:
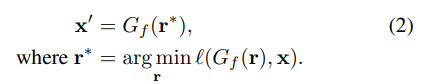
作者表示,尽管最终要找的是中间表征 r,但从估计的 z 开始能提供很多帮助:
对 z 有个初始估计能有助于对更好的 r 值的搜索,这些值更有可能由 z 生成。
因此,求解这个逆推问题的过程分为两步:
首先,构建一个近似逆推整个 G 的神经网络 E,并计算一个估计结果 z_0 = E(x)。
之后,求解一个优化问题,以确定一个中间表征
 ,其可生成一个重建的图像
,其可生成一个重建的图像
 ,以非常相近地恢复 x。
图 3 展示了这种层逆推方法。
,以非常相近地恢复 x。
图 3 展示了这种层逆推方法。
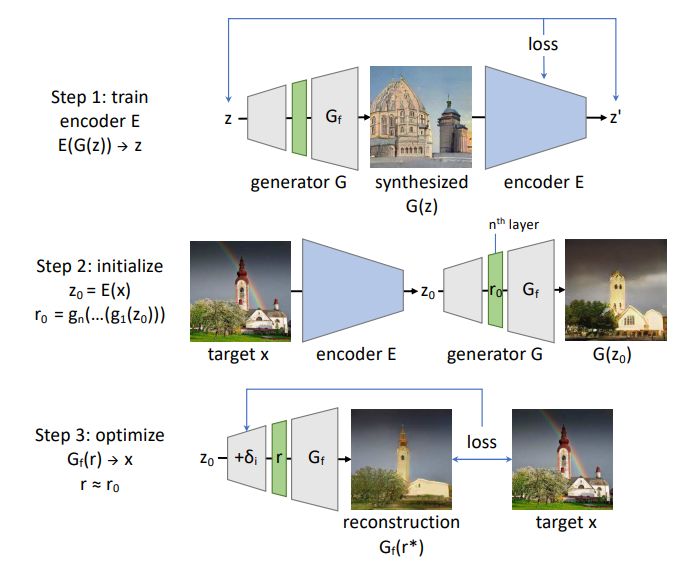
图 3:层逆推方法概况。首先,训练一个逆转 G 的网络 E;这可用于获取对隐含的 z_0 = E(x) 的初始估计及其中间表征
 。然后将 r_0 用于初始化对 r* 的搜索,以得到接近目标 x 的重建 x'。
。然后将 r_0 用于初始化对 r* 的搜索,以得到接近目标 x 的重建 x'。
通过在更小的问题上预训练各个层,可以更轻松地训练深度网络。
因此,为了学习逆推神经网络 E,作者选择了逐层执行的方法。
对于每一层 g_i ∈ {g_1, ..., g_n, G_f },训练一个小网络 e_i 以近似地逆推 g_i。
也就是说,定义 r_i = g_i(r_i−1),目标是学习一个网络 e_i,使其能近似计算 r_{i−1} ≈ e_i(r_i)。
作者也希望网络 e_i 的预测能够很好地保留层 g_i 的输出,因此需要 r_i ≈ g_i(e_i(r_i))。
作者通过最小化左逆推和右逆推损失来训练 e_i:
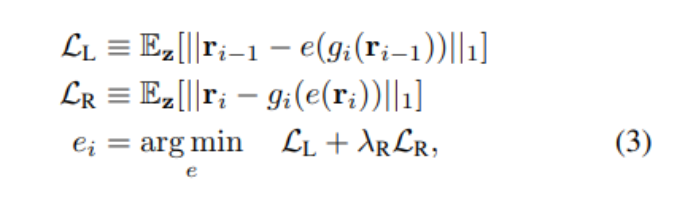
为了将训练集中在生成器所得到的表征的流形附近,作者对 z 进行了采样,并使用层 g_i 计算了 r_{i−1} 和 r_i 的样本,因此 r_{i−1} = g_{i−1}(· ·· g_1(z)· ··)。
这里 ||·||_1 表示 L1 损失,作者将 λ_R 设为 0.01 以强调 r_{i−1} 的重建。
一旦所有层都完成逆推后,可为整个 G 组建一个逆推网络:
通过联合微调这个为以整体逆推 G 而组建的网络 E*,结果还可得到进一步的优化。
作者将经过微调的结果记为 E。
结果
图 2 和图 4 展示了在 LSUM 卧室集上训练的 WGAN-GP、StyleGAN、Progressive GAN 的生成图像分割统计数据。
图 4:
一个卧室生成器的省略情况可视化;
这里测试了基于 lSUM 卧室集的 Progressive GAN。
直方图表明,对于多种不同的分割目标类别,StyleGAN 能比 Progressive GAN 更好地匹配这些目标的真实分布,而 WGAN-GP 的匹配最差。
表 1 用 Frechet 分割距离总结了这些差异,证实更好的模型整体上的分割统计情况与真实分布更加匹配。
表 1:
用 FSD 总结的生成图像分割统计数据。










