If you wanted to classify animals, for example, based on a plethora of relevant collected data, you would quickly find that all sorts of potential data attributes, or features, were relatively unhelpful for classification. For example, given that most living creatures have precisely 1 heart, this particular feature would not be beneficial, from a learning perspective. On the other hand, an attribute denoting whether or not a given animal is hoofed would likely be a powerful predictor.
Further, using all of these irrelevant attributes, mixed in with the powerful predictors, may actually have a negative effect on the resulting model. This is to say nothing of the increased training times that may come along with the inclusion of useless attributes, or the overfitting which may occur on the training data.
Feature selection is the process of narrowing down a subset of features, or attributes, to be used in the predictive modeling process. Feature selection is useful on a variety of fronts: it is the best weapon against the Curse of Dimensionality; it can reduce overall training times; and it is a powerful defense against overfitting, increasing model generalizability.
Something I read recently -- written so eloquently and concisely by data scientist Rubens Zimbres -- alludes to the importance of feature selection from a practical standpoint:
After some experiences, using stacked neural nets, parallel neural nets, asymmetric configs, simple neural nets, multiple layers, dropouts, activation functions etc there is one conclusion: There's NOTHING like a good Feature Selection.
Having had some previous professional contacts with Rubens Zimbres in the past, I reached out to him for some elaboration. He provided the following:
Feature selection should be one of the main concerns for a Data Scientist. Accuracy and generalization power can be leveraged by a correct feature selection, based in correlation, skewness, t-test, ANOVA, entropy and information gain.
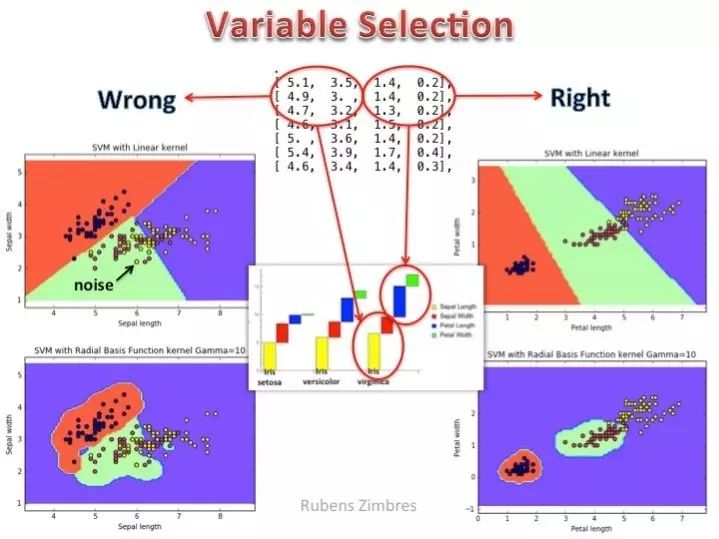
Many times a correct feature selection allows you to develop simpler and faster Machine Learning models. Consider the picture below (Support Vector Machine classification of the IRIS dataset): on the left side a wrong variable selection is presented. The linear kernel cannot handle the classification task properly, neither the radial basis function kernel. On the right side, petal width and petal length were selected as features and even the linear kernel is quite accurate. A correct variable selection, a good algorithm choice and hyperparameter tuning are the keys to success. Picture below made with Python.
链接:
http://www.kdnuggets.com/2017/06/practical-importance-feature-selection.html
原文链接:
https://m.weibo.cn/1402400261/4118103216008702







