我曾经也只是一个只懂 ACM 竞赛相关算法的普通程序员,误打误撞接触到了数据挖掘,之后才开始系统地了解机器学习相关的知识,如今已经基本走上了正轨,开始了走向 Data Scientist 的征途。 但是最高赞的一篇回答居然是关于 Deep Learning 的,这感觉就想是有人问我这山地车好高级,能不能教我怎么换挡,我告诉他说,这车太low了,我教你开飞机吧。我想即使目前开飞机(Deep Learning)的门槛一再降低,如果你没有一个优秀的基础,即使是老司机也是容易翻车的。 简单认真回答一下,首先作为一个普通程序员,C++ / Java / Python 这样的语言技能栈应该是必不可少的,其中 Python 需要重点关注爬虫、数值计算、数据可视化方面的应用,主要是:

推荐阅读:吴军 —《数学之美》、大学相关课程教材
-
统计学基础
-
相关性分析(相关系数r、皮尔逊相关系数、余弦相似度、互信息)
-
回归分析(线性回归、L1/L2正则、PCA/LDA降维)
-
聚类分析(KNN、K-Means)
-
分布(正态分布、t分布、密度函数)
-
指标(协方差、ROC曲线、AUC、变异系数、F1-Score)
-
显著性检验(t检验、z检验、卡方检验)
-
A/B测试
推荐阅读:李航 —《统计学习方法》
推荐阅读:《集体智慧编程》、Andrew Ng — Machine Learning Coursera from Stanford
此时的你或许已经有一块可以用的敲门砖了,但离工业界实际应用还有比较大的距离,主要差距就在于 Feature Engineering,这也是我在面试考察有经验的人面前比较注重的点。这一块中有一些比较基础的知识点,
简单罗列如下:
可用性评估:获取难度、覆盖率、准确率
特征清洗:清洗异常样本
采样:数据不均衡、样本权重
单个特征:无量纲化(标准化、归一化)、二值化、离散化、缺失值(均值)、哑编码(一个定性特征扩展为N个定量特征)
数据变换:log、指数、Box-Cox 降维:主成分分析PCA、线性判别分析LDA、SVD分解
特征选择:Filter(相关系数、卡方检验)、Wrapper(AUC、设计评价函数A*、Embedded(L1-Lasso、L2-Ridge、决策树、DL)
衍生变量:组合特征 特征监控:监控重要特征,fa特征质量下降 放一张公司内部算法培训关于特征工程的 PPT,仅供学习参考:
再往后你就可以在技能树上点几个酷炫的了:
提升
SVM
-
软间隔
-
损失函数
-
核函数
-
SMO算法
-
libSVM
聚类
-
K-Means 并查集
-
K-Medoids
-
聚谱类SC
EM
算法
主题模型
-
共轭先验分布
-
贝叶斯
-
停止词和高频词
-
TF-IDF
词向量
HMM
-
前向/后向算法
-
Baum-Welch
-
Viterbi
-
中文分词
数据计算平台
推荐阅读:周志华——《机器学习》
可以看到,不管你是用 TensorFlow 还是用 Caffe 还是用 MXNET 等等一系列平台来做高大上的 Deep Learning,在我看来都是次要的。想要在这个行业长久地活下去,内功的修炼要比外功重要得多,不然会活得很累,也很难获得一个优秀的晋升空间。 最后,关注你所在行业的最新 paper,对最近的算法理论体系发展有一个大致印象,譬如计算广告领域的几大经典问题:

本文的目的是给出一个简单的,平滑的,易于实现的学习方法,帮助 “普通” 程序员踏入AI领域这个门。这里,我对普通程序员的定义是:拥有大学本科知识;平时工作较忙;自己能获取的数据有限。因此,本文更像是一篇 “from the scratch” 的AI入门教程。
AI,也就是人工智能,并不仅仅包括机器学习。曾经,符号与逻辑被认为是人工智能实现的关键,而如今则是基于统计的机器学习占据了主导地位。最近火热的深度学习正是机器学习中的一个子项。目前可以说,学习AI主要的是学习机器学习。但是,人工智能并不等同于机器学习,这点在进入这个领域时一定要认识清楚。关于AI领域的发展历史介绍推荐看周老师写的《机器学习简介》。下面一个问题是:AI的门好跨么?其实很不好跨。我们以机器学习为例。在学习过程中,你会面对大量复杂的公式,在实际项目中会面对数据的缺乏,以及艰辛的调参等。如果仅仅是因为觉得这个方向未来会“火”的话,那么这些困难会容易让人放弃。考虑到普通程序员的特点,而要学习如此困难的学科,是否就是没有门路的?答案是否定的。只要制定合适的学习方法即可。
学习方法的设定简单说就是回答以下几个问题:我要学的是什么?我怎样学习?我如何去学习?这三个问题概括说就是:学习目标,学习方针与学习计划。学习目标比较清楚,就是踏入AI领域这个门。这个目标不大,因此实现起来也较为容易。“过大的目标时就是为了你日后放弃它时找到了足够的理由”。学习方针可以总结为 “兴趣为先,践学结合”。简单说就是先培养兴趣,然后学习中把实践穿插进来,螺旋式提高。这种方式学习效果好,而且不容易让人放弃。有了学习方针以后,就可以制定学习计划,也称为学习路线。下面就是学习路线的介绍。
我推荐的学习路线是这样的,如下图:

图1 AI领域学习路线图
这个学习路线是这样设计的:首先了解这个领域,建立起全面的视野,培养起充足的兴趣,然后开始学习机器学习的基础,这里选择一门由浅入深的课程来学习,课程最好有足够的实验能够进行实战。基础打下后,对机器学习已经有了充足的了解,可以用机器学习来解决一个实际的问题。这时还是可以把机器学习方法当作一个黑盒子来处理的。实战经验积累以后,可以考虑继续进行学习。这时候有两个选择,深度学习或者继续机器学习。深度学习是目前最火热的机器学习方向,其中一些方法已经跟传统的机器学习不太一样,因此可以单独学习。除了深度学习以外,机器学习还包括统计学习,集成学习等实用方法。如果条件足够,可以同时学习两者,一些规律对两者是共通的。学习完后,你已经具备了较强的知识储备,可以进入较难的实战。这时候有两个选择,工业界的可以选择看开源项目,以改代码为目的来读代码;学术界的可以看特定领域的论文,为解决问题而想发论文。无论哪者,都需要知识过硬,以及较强的编码能力,因此很能考察和锻炼水平。经过这个阶段以后,可以说是踏入AI领域的门了。“师傅领进门,修行在个人”。之后的路就要自己走了。
下面是关于每个阶段的具体介绍:
在学习任何一门知识之前,首先第一步就是了解这个知识是什么?它能做什么事?它的价值在什么地方?如果不理解这些的话,那么学习本身就是一个没有方向的舟,不知道驶向何处,也极易有沉船的风险。了解这些问题后,你才能培养出兴趣,兴趣是最好的引路人,学习的动力与持久力才能让你应付接下来的若干个阶段。关于机器学习是什么,能做什么,它与深度学习以及人工智能的关系,从机器学习谈起:
如果你离校过久,或者觉得基础不牢,最好事先做一下准备复习工作。“工欲善其事,必先利其器”。以下的准备工作不多,但足以应付后面阶段的学习。
数学:复习以下基本知识。线性代数:矩阵乘法;高数:求导;概率论:条件与后验概率。其他的一些知识可以在后面的学习的过程中按需再补;
英文:常备一个在线英文词典,例如爱词霸,能够不吃力的看一些英文的资料网页;
FQ:可以随时随地上Google,这是一个很重要的工具。不是说百度查的不能看,而是很多情况下Google搜出来的资料比百度搜的几十页的资料还管用,尤其是在查英文关键字时。节省时间可是很重要的学习效率提升;
机器学习的第一门课程首推Andrew Ng的机器学习。这门课程有以下特点:难度适中,同时有足够的实战例子,非常适合第一次学习的人。http://open.163.com/special/opencourse/machinelearning.html
这门课程我这里不推荐,为什么,原因有以下:
时间:这门课 的时间太早,一些知识已经跟不上当今的发展,目前最为火热的神经网络一笔带过。而Cousera上神经网络可是用了两个课时去讲的!而且非常详细;
教学:Ng在cs229 时候的教学稍显青涩,可能是面对网络教学的原因。有很多问题其实他都没有讲清楚,而且下面的人的提问其实也很烦躁,你往往不关心那些人的问题。这点在Coursera上就明显得到了改善,你会发现Ng的教学水平大幅度改善了,他会对你循循善诱,推心置腹,由浅入深的教学,在碰到你不明白的单词术语时也会叫你不要担心,更重要的,推导与图表不要太完善,非常细致清晰,这点真是强力推荐;
字幕:cs229 的字幕质量比Coursera上的差了一截。Coursera上中文字幕翻译经过了多人把关,质量很有保证;
作业:cs229 没有作业,虽然你可以做一些,但不会有人看。这点远不如Coursera上每周有deadline的那种作业,而且每期作业提交上去都有打分。更重要的是,每期作业都有实际的例子,让你手把手练习,而且能看到自己的成果,成就感满满!
学习完了基础课程,你对机器学习就有了初步了解。现在使用它们是没有问题的,你可以把机器学习算法当作黑盒子,放进去数据,就会有结果。在实战中你更需要去关心如何获取数据,以及怎么调参等。如果有时间,自己动手做一个简单的实践项目是最好的。这里需要选择一个应用方向,是图像(计算机视觉),音频(语音识别),还是文本(自然语言处理)。这里推荐选择图像领域,这里面的开源项目较多,入门也较简单,可以使用OpenCV做开发,里面已经实现好了神经网络,SVM等机器学习算法。项目做好后,可以开源到到 Github 上面,然后不断完善它。实战项目做完后,你可以继续进一步深入学习,这时候有两个选择,深度学习和继续机器学习;
深度学习:深度学习是目前最火热的研究方向。有以下特点:知识更新快,较为零碎,没有系统讲解的书。因此学习的资源也相对零散,下面是一些资源介绍。其中不推荐的部分并不代表不好,而是在这个初学阶段不合适:
推荐,UFLDL
http://ufldl.stanford.edu/wiki/index.php/UFLDL_Tutorial
: 非常好的DL基础教程,也是Andrew Ng写的。有很详尽的推导,有翻译,且翻译质量很高;
推荐,Deep learning (paper):2015年Nature上的论文,由三位深度学习界的大牛所写,读完全篇论文,给人高屋建瓴,一览众山小的感觉,强烈推荐。
https://www.cs.toronto.edu/~hinton/absps/NatureDeepReview.pdf
如果只能读一篇论文了解深度学习,我推荐此篇。这篇论文有同名的中文翻译;
推荐,Neural networks and deep learning:这本书的作者非常擅长以浅显的语言表达深刻的道理,虽然没有翻译,但是阅读并不困难;
http://neuralnetworksanddeeplearning.com/
推荐,Recurrent Neural Networks: 结合一个实际案例告诉你RNN是什么,整篇教程学完以后,会让你对RNN如何产生作用的有很清晰的认识,而这个效果,甚至是读几篇相关论文所没有的;
http://www.wildml.com/2015/09/recurrent-neural-networks-tutorial-part-1-introduction-to-rnns/
不推荐,Neural Networks for Machine Learning - University of Toronto | Coursera:深度学习创始人教的课,最大的问题是太难,而且老先生的吐字有时不是很标准;
不推荐,Deep Learning (book):同样也是由深度学习大牛所写的书,但感觉就像是第二作者,也就是他的学生所写的。很多内容都讲了,但是感觉也没讲出什么内容来,只是告诉你来自那篇论文,这样的话可能直接阅读论文更合适。
不推荐,cs231n:李菲菲的课程,很有名,专门讲CNN。但是这门课程有一个最大的问题,就是没有字幕,虽然有youtube的自动翻译字幕,但有还不如没有。
深度学习未必就是未来的一定主流,至少一些大牛是这么认为的。传统的机器学习有如下特点,知识系统化,有相对经典的书。其中统计学习(代表SVM)与集成学习(代表adaboost)是在实践中使用非常多的技术。下面是相关资源:
推荐,机器学习(周志华):如果是在以前,机器学习方面的经典教材首推PRML,但现在周老师的书出来以后,就不再是这样了。首先推荐读周老师的书。这本书有一个特点,那就是再难的道理也能用浅显精炼的语言表达出来。正如周老师的名言:“体现你水平的地方是把难的东西讲容易了,而不是把容易的东西讲难,想把一个东西讲难实在太简单”;
不推荐,Pattern Recognition And Machine Learning:当前阶段不推荐。PRML是以贝叶斯的观点看待很多机器学习方法,这也是它的一大特色。但对于初学者来说,这种观点其实并无必要。而且此书没有中文翻译,当前阶段硬啃很容易放弃;
当知识储备较为充足时,学习可以再次转入实践阶段。这时候的实践仍然可以分两步走,学习经典的开源项目或者发表高质量的论文。开源项目的学习应该以尽量以优化为目的,单纯为读代码而学习效果往往不太好。好的开源项目都可以在Github 里搜索。这里以深度学习为例。深度学习的开源优秀库有很多,例如torch,theano等等,这里列举其中的两个:
推荐,DeepLearnToolbox:较早的一个深度学习库,用matlab语言撰写,较为适合从刚学习的课程转入学习。遗憾的是作者不再维护它了;
推荐,tensorflow:Google的开源库,时至今日,已经有40000多个star,非常惊人,支持移动设备;
较好的课程都会推荐你一些论文。一些著名的技术与方法往往诞生于一些重要的会议。因此,看往年的会议论文是深入学习的方法。在这时,一些论文中的内容会驱使你学习数学中你不擅长的部分。有时候你会觉得数学知识储备不够,因此往往需要学习一些辅助课程。当你看完足够的论文以后,在这个阶段,如果是在校学生,可以选择某个课题,以发论文为目的来学习研究。一般来说,论文是工作的产物。有时候一篇基于实验的论文往往需要你写代码或者基于开源项目。因此开源项目的学习与会议论文的工作两者之间是有相关的。两者可以同时进行学习。关于在哪里看论文,可以看一下CCF推荐排名,了解一下这个领域里有哪些优秀的会议。下面介绍两个图像与机器学习领域的著名顶级会议:
CVPR:与另两个会议ICCV和ECCV合称计算机视觉领域的三大会,注意会议每年的主页是变动的,因此搜索需要加上年份;
Conference on Neural Information Processing Systems:简称NIPS,许多重要的工作发表在这上面,例如关于CNN的一篇重要论文就是发表在上面;
自由学习:到这里了,可以说是进入这个门了。下面可以依据兴趣来自由学习。前阶段不推荐的学习资源也可随意学习,下面是点评:
cs229 :Ng写的讲义很不错,其中关于SVM的推导部分很清晰,想学习SVM推荐;
Neural Networks for Machine Learning:大牛的视角跟人就是不一样,看看Hinton对神经网络是怎么看的,往往会让你有种原来如此的感悟。其实看这门课程也等同于读论文,因为几乎每节课的参考资料里都有论文要你读;
CS231n: Convolutional Neural Networks for Visual Recognition:最新的知识,还有详细的作业。国内应该有团队对字幕进行了翻译,可以找找;
PRML:作为一门经典的机器学习书籍,是很有阅读必要的,会让你对机器学习拥有一个其他的观察视角;
本文的目的是帮助对AI领域了解不深,但又想进入的同学踏入这个门。这里只说踏入,是因为这个领域的专精实在非常困难,需要数年的积累与努力。在进行领域学习前,充分认识自己的特点,制定合适的学习方法是十分重要的。首先得对这个领域进行充分了解,培养兴趣。在学习时,保持着循序渐进的学习方针,不要猛进的学习过难资源;结合着学习与实践相辅的策略,不要只读只看,实际动手才有成就感。学习某个资源时要有充分的目的,不是为了学开源项目而看代码,而是为了写开源项目而看;不是为了发论文而写论文,而是为了做事情而写论文。如果一个学习资源对你过难,并不代表一定是你的问题,可能是学习资源的演讲或撰写人的问题。能把难的问题讲简单的人才是真正有水平的人。所以,一定要学习优质资源,而不是不分青红皂白的学习。最后,牢记以兴趣来学习。学习的时间很长,过程也很艰难,而只有兴趣才是让你持之以恒,攻克难关的最佳助力。
原创:吴郦军、罗人千 微软研究院AI头条
编者按:如果你是刚入门机器学习的AI探索者,你知道什么是胶囊网络吗?AutoML和元学习又是什么?为了帮大家节省查阅晦涩难懂的论文的时间,我们邀请微软亚洲研究院机器学习组实习生吴郦军、罗人千帮大家用最通俗的语言解释了这三个机器学习领域的热门词汇,赶紧收藏吧!
胶囊网络(Capsule Networks)是深度学习三巨头之一的Geoffrey Hinton提出的一种全新的神经网络。最初发表在2017年的NIPS会议上:Dynamic Routing Between Capsules。胶囊网络基于一种新的结构——胶囊(Capsule),通过与现有的卷积神经网络(CNN)相结合,从而在一些图像分类的数据上取得了非常优越的性能。
何谓胶囊?简单来说,
胶囊就是将原有大家熟知的神经网络中的个体神经元替换成了一组神经元组成的向量,这些神经元被包裹在一起,组成了一个胶囊
。因此,胶囊网络中的每层神经网络都包含了多个胶囊基本单元,这些胶囊与上层网络中的胶囊进行交互传递。

胶囊网络的主要特点是什么呢?与传统CNN相比优势是什么呢?下图简单比较了胶囊和传统的神经网络中神经元的不同。

两者最大的不同在于,
胶囊网络中的神经元是一个整体,包含了特征状态的各类重要信息
,比如长度、角度、方向等,而传统的CNN里每个神经元都是独立的个体,无法刻画位置、角度等信息。这也就是为什么CNN通过数据增广的形式(对于同一个物体,加入不同角度、不同位置的图片进行训练),能够大大提高模型最后的结果。
胶囊网络能够保证图像中不同的对象(比如人脸中的鼻子、眼睛、嘴巴)之间的相对关系不受角度改变的影响
,这一特性来自于图形图像学的启发。对于3D图像,人类的大脑能够在不同的位置对于这个图像都做出准确的判别。当我们以向量的形式将特性状态封装在胶囊中时,胶囊拥有状态特性的长度(以概率形式加权编码)以及状态的方向(特征向量的方向)。因此对于胶囊来说,长度相同的特征,其方向也存在着变化,而这样的变化对于模型训练就正如不同角度的增广图像。
胶囊的工作原理是基于“囊间动态路由”的算法,这是一种迭代算法
。简单地说,两层之间的胶囊信息传递,会通过计算两者之间的一种相关信息来决定下层的胶囊如何将自己的特征传递给上层的胶囊。也就是说,下层胶囊将其输出发送给对此表示“同意”的上层胶囊,利用输入与输出之间的点积相似性,来更新路由间的系数。
跟传统的CNN相比,当前的胶囊网络在实验效果上取得了更好的结果,但是训练过程却慢了很多,因此胶囊网络依然很有很大的发展空间。
在实际的AI应用中,如果想让机器学习获得比较好的学习结果,除了对数据进行初步分析、处理,可能还需要依赖领域知识对数据进行进一步的特征提取和特征选择,然后根据不同的任务及数据特征选择合适的机器学习模型,在训练模型时还要调大量的超参数,尝试各种tricks。整个过程中需要花费大量的人工和时间。因此,机器学习从业者都戏称自己是“调参工程师”,称自己的工作是“有多少人工就有多少智能”。对于初入门的小白及大量普通开发者来说,机器学习工具比较难以掌握。
为了减少这些需要人工干预的繁杂工作,
自动机器学习(Automatic Machine Learning,简称AutoML)
应运而生。它能
自动选择合适的算法模型以及调整超参数
,并最终取得不错的学习效果。简单来说,自动机器学习过程就是用户提供数据集,确定任务目标,之后的工作就交给AutoML来处理,用户将会得到一个训练好的模型。这大大降低了使用机器学习工具的门槛,让机器学习工具的使用过程变得简单、轻松。
我们以AutoML里的一个子领域NAS(Neural Architecture Search,神经网络结构搜索)为例。顾名思义,NAS是自动搜索神经网络的结构。传统神经网络都是由人工设计的,经过长时间的演化迭代,从AlexNet到DenseNet,性能不断上升,效果也不断提升。但正如前文所说,神经网络结构的演化过程耗费了大量的人工。不同的基础网络结构,如AlexNet、VGG、ResNet、DenseNet等需要深度学习的专业研究人员进行研究改进,而它们在具体任务上的应用又需要进一步调整相应的参数和结构。

NAS旨在针对给定的数据集和学习任务,自动搜索出适用于该任务的好的网络结构。决定一个神经网络“区别于其它网络”的关键因素包括网络结构里每层的运算操作(如不同种类、大小的卷积和池化操作)、每层的大小、层与层之间的连接方式、采用的激活函数等。这些关键因素在传统的人工设计的神经网络里都是固定的,但在自动搜索网络结构里可能都是未知的。算法需要通过自动搜索进而最终决定一个神经网络的结构。
2016年Barret Zoph等人发表了Neural architecture search with reinforcement learning一文,文中提出了控制器-子网络的框架,其中子网络即我们要应用在目标任务上的网络,控制器则负责生成子网络的结构。对于图像类任务,子网络采用CNN,搜索其每层的运算操作和连接方式;对于文本类任务,子网络采用RNN时,搜索其每层的激活函数和连接方式。控制器搜索出的子网络结构在目标任务的数据验证集上的性能则作为reward反馈给控制器,通过强化学习进行训练,使得控制器经过不断的学习迭代生成更好的子网络结构。但是这一工作使用了大量GPU资源,耗费了一个月时间才得到了最后的结果。
随后,有一系列的工作对NAS做出了改进:改进搜索空间(搜索单一block里的结构,之后堆叠多个block作为最终网络)、改进搜索算法(使用演化算法、梯度优化等)、提升搜索效率(通过参数共享等)等。这些工作提升了NAS本身的搜索效率和性能,同时搜索出的CNN网络也在主要的数据集(CIFAR10、CIFAR100、IMAGENET)上取得了SOTA,超过了人工设计的网络的性能。微软亚洲研究院机器学习组发表在NIPS 2018上的工作Neural Architecture Optimization [1],利用网络结构在验证集上的性能对网络的梯度信息来优化网络结构。首先将离散的网络结构用编码器转换成连续空间里的向量,然后训练了一个预测器来预测该向量(网络结构)在验证集上的性能,从而可以直接基于预测结果对该向量的梯度进行优化,生成更好的向量(网络结构),最后再通过解码器解码将生成的向量解码成离散的网络结构。我们的算法搜索出的CNN和RNN结构在相应任务(CIFAR10、CIFAR100、PTB、Wikitext-2)上皆取得了超过其它NAS工作的最好性能。
我们期待的通用人工智能的目标是让人工智能像人一样学会推理、思考,能快速学习。对于现实世界的很多问题,人类之所以能够快速学习是因为人类具有强大的思考推理能力以及学习能力。人类能够利用以往学习到的知识经验来指导新知识的学习,做到“触类旁通”、“举一反三”,这让人类的学习行为变得十分高效。
元学习(Meta Learning)的目的就是研究如何让机器学习系统拥有学习的能力
,能够更好、更高效地学习,从而取得更好的学习效果。比如对于数据集,采取什么方式、什么顺序、什么策略进行学习,对于学习效果如何进行评测,这些都会影响到模型学习的效果。

原创:
weakish
论智
编者按:Ahmed Gad介绍了一个决定神经网络深度、网络层大小的简单方法。

该使用多少层隐藏层?使用隐藏层的目的是什么?增加隐藏层/神经元的数目总能给出更好的结果吗?人工神经网络(ANN)初学者常常提出这些问题。如果需要解决的问题很复杂,这些问题的答案可能也会比较复杂。希望读完这篇文章后,你至少可以知道如何回答这些问题。
在计算机科学中,借鉴了生物神经网络的ANN用一组网络层表示。这些网络层可以分为三类:输入层、隐藏层、输出层。
输入层和输出层的层数、大小是最容易确定的。每个网络都有一个输入层,一个输出层。输入层的神经元数目等于将要处理的数据的变量数。输出层的神经元数目等于每个输入对应的输出数。不过,确定隐藏层的层数和大小却是一项挑战。
下面是在分类问题中确定隐藏层的层数,以及每个隐藏层的神经元数目的一些原则:
下面我们将举例说明这一确定隐藏层层数、大小的简单方法。
让我们先来看一个简单的分类问题。每个样本有两个输入和一个表示分类标签的输出,和XOR问题很像。

首先需要回答的问题,是否需要隐藏层。关于这个问题,有一条一般规则:
在神经网络中,当且仅当数据必须以非线性的方式分割时,才需要隐藏层。
回到我们的例子。看起来一条直线搞不定,因此,我们需要使用隐藏层。在这样的情形下,也许我们仍然可以不用隐藏层,但会影响到分类精确度。所以,最好使用隐藏层。
已知需要隐藏层,那么接下来就需要回答两个重要问题:
-
需要多少层?
-
每层需要多少神经元?
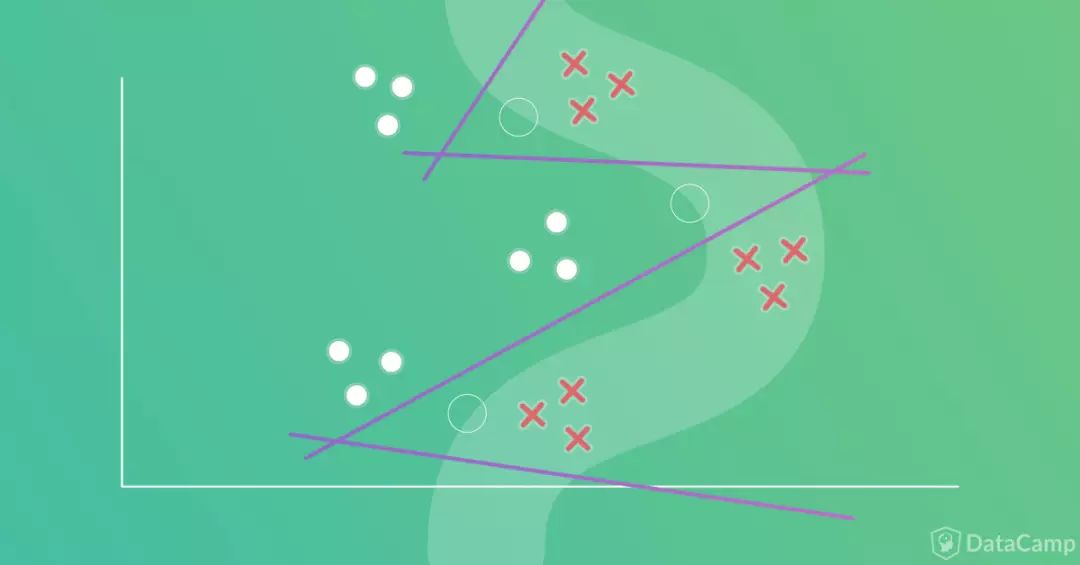
按照我们之前提到的流程,首先需要画出分割的边界。如下图所示,可能的边界不止一种。我们在之后的讨论中将以下图右部的方案为例。
根据之前的原则,接下来是使用一组线段表示这一边界。
使用一组线段表示边界的想法来自于神经网络的基础构件——单层感知器。单层感知器是一个线性分类器,根据下式创建分界线:
y = w
1
x
1
+ w
2
x
2
+ ⋯ + w
i
x
i
+ b
其中x
i
是第i项输入,w
i
是权重,b是偏置,y是输出。因为每增加一个隐藏单元都会增加权重数,所以一般建议使用能够完成任务的最少数量的隐藏单元。隐藏神经元使用量超出需要会增加复杂度。
回到我们的例子上来,人工神经网络基于多个感知器构建,这就相当于网络由多条直线组成。
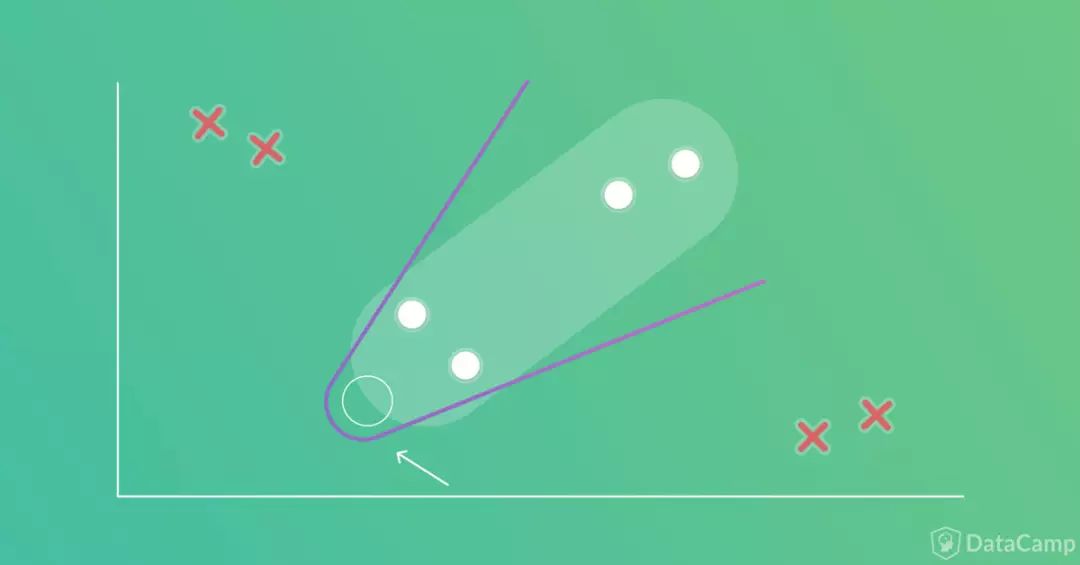
因此我们使用一组线段替换边界,以分界曲线变向处作为线段的起点,在这一点上放置方向不同的两条线段。
如下图所示,我们只需要两条线段(分界曲线变向处以空心圆圈表示)。也就是两个单层感知器网络,每个感知器产生一条线段。
只需两条线段就可以表示边界,因此第一个隐藏层将有两个隐藏神经元。
到目前为止,我们有包含两个隐藏神经元的单隐藏层。每个隐藏神经元可以看成由一条线段表示的一个线性分类器。每个分类器(即隐藏神经元)都有一个输出,总共有两个输出。但我们将要创建的是基于单个输出表示分类标签的一个分类器,因此,两个隐藏神经元的输出将被合并为单个输出。换句话说,这两条线段将由另一个神经元连接起来,如下图所示。
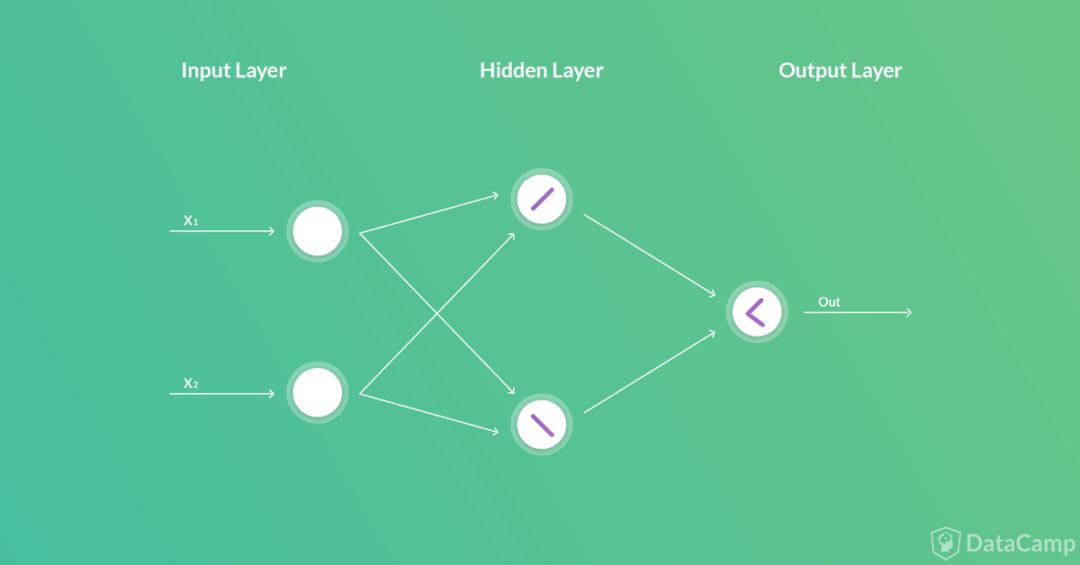
很幸运,我们并不需要额外添加一个包含单个神经元的隐藏层。输出层的神经元正好可以起到这个作用,合并之前提到的两个输出(连接两条线段),这样整个网络就只有一个输出。
整个网络架构如下图所示:
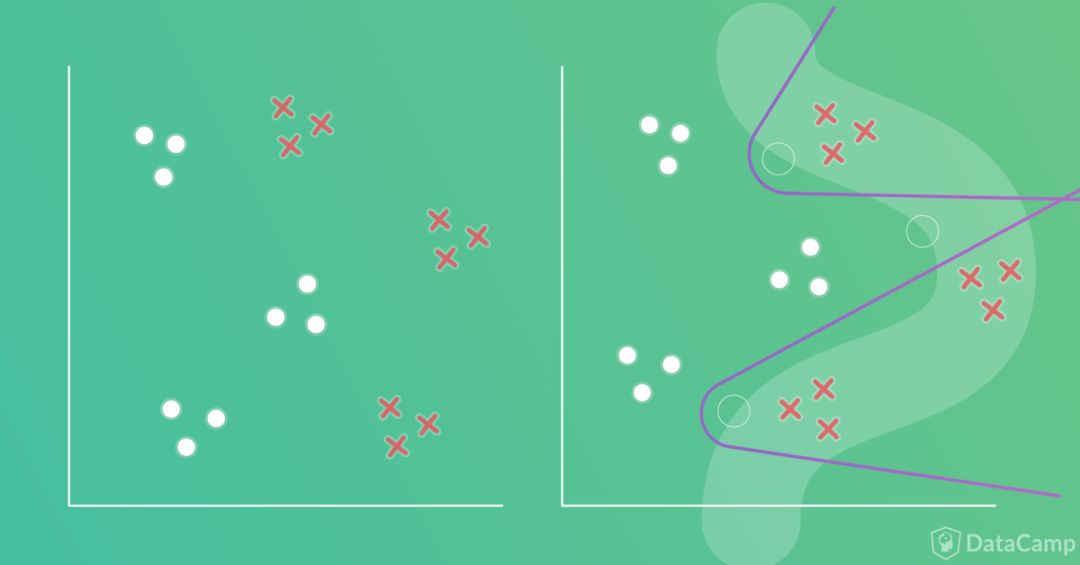
我们再来看一个分类问题的例子。和上面一个例子相似,这个例子也有两个分类,每个样本对应两个输入和一个输出。区别在于边界比之前的更复杂。

遵照之前的原则,第一步是画出边界(如下图左半部分所示),接着是将边界分成一组线段,我们将使用ANN的感知器建模每条线段。在画出线段之前,首先标出边界的变向处(下图右半部分中的空心圆圈)。
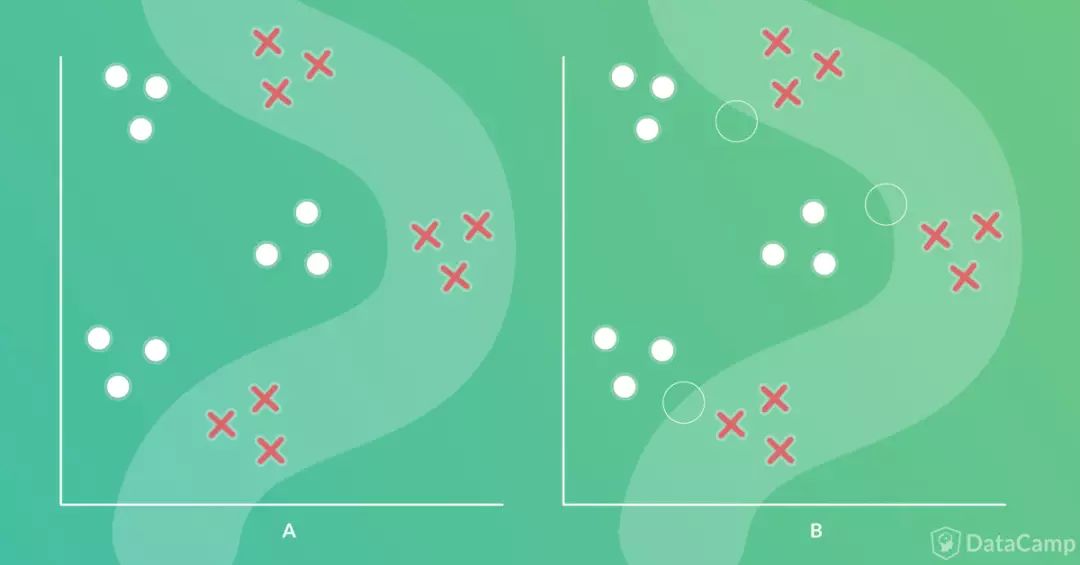
问题在于需要几条线段?顶部和底部的变向处各需要两条线段,这样总共是4条线段。而当中的变向处可以和上下两个变向处共用线段。所以我们需要4条线段,如下图所示。