 作者 | 黄波,何沧平
作者 | 黄波,何沧平
责编 | 何永灿
随着人工神经网络算法的成熟、GPU计算能力的提升,深度学习在众多领域都取得了重大突破。本文介绍了微博引入深度学习和搭建深度学习平台的经验,特别是机器学习工作流、控制中心、深度学习模型训练集群、模型在线预测服务等核心部分的设计、架构经验。微博深度学习平台极大地提升了深度学习开发效率和业务迭代速度,提高了深度学习模型效果和业务效果。
人工智能和深度学习
人工智能为机器赋予人的智能。随着计算机计算能力越来越强,在重复性劳动和数学计算方面很快超过了人类。然而,一些人类通过直觉可以很快解决的问题,例如自然语言理解、图像识别、语音识别等,长期以来很难通过计算机解决。随着人工神经网络算法的成熟、GPU计算能力的提升,深度学习在这些领域也取得了重大的突破,甚至已经超越人类。深度学习大大拓展了人工智能的领域范围。
深度学习框架
深度学习框架是进行深度学习的工具。简单来说,一套深度学习框架就是一套积木,各个组件就是某个模型或算法;开发者通过简单设计和组装就能获得自己的一套方案。深度学习框架的出现降低了深度学习门槛。开发者不需要编写复杂的神经网络代码,只需要根据自己的数据集,使用已有模型通过简单配置训练出参数。
TensorFlow、Caffe和MXNet是三大主流的深度学习开源框架:TensorFlow的优势是社区最活跃,开源算法和模型最丰富;Caffe则是经典的图形领域框架,使用简单,在科研领域占有重要地位;MXNet在分布式性能上表现优异。PaddlePaddle、鲲鹏、Angel则是百度、阿里、腾讯分别推出的分布式计算框架。
2015年底,Google开源了TensorFlow深度学习框架,可以让开发者方便地组合CNN、RNN等模块实现复杂的神经网络模型。TensorFlow是一个采用数据流图(data flow graphs),用于数值计算的开源软件库。
2016年,百度开源了PaddlePaddle(PArallel Distributed Deep LEarning 并行分布式深度学习)深度学习框架。PaddlePaddle具有易用,高效,灵活和可伸缩等特点,为百度内部多项产品提供深度学习算法支持。
深度学习平台
深度学习框架主要提供神经网络模型实现,用于进行模型训练。模型训练只是机器学习和深度学习中的一环,除此之外还有数据输入、数据处理、模型预测、业务应用等重要环节。深度学习平台就是整合深度学习各环节,为开发者提供一体化服务的平台。深度学习平台能够加快深度学习的开发速度,缩减迭代周期;同时,深度学习平台能够将计算能力、模型开发能力共享,提升开发效率和业务效果,也能够将资源合理调度,提高资源利用率。
腾讯深度学习平台DI-X
腾讯深度学习平台DI-X于2017年3月发布。DI-X基于腾讯云的大数据存储与处理能力来提供一站式的机器学习和深度学习服务。DI-X支持TensorFlow、Caffe以及Torch等三大深度学习框架,主要基于腾讯云的GPU计算平台。DI-X的设计理念是打造一个一站式的机器学习平台,集开发、调试、训练、预测、部署于一体, 让算法科学家和数据科学家,无须关注机器学习(尤其是深度学习)的底层工程繁琐的细节和资源,专注于模型和算法调优。
DI-X在腾讯内部使用了一年,其主要用于游戏流失率预测、用户标签传播以及广告点击行为预测等。
阿里机器学习平台PAI
阿里机器学习平台PAI1.0于2015年发布,包括数据处理以及基础的回归、分类、聚类算法。阿里机器学习平台PAI2.0于2017年3月发布,配备了更丰富的算法库、更大规模的数据训练和全面兼容开源的平台化产品。深度学习是阿里机器学习平台PAI2.0的重要功能,支持TensorFlow、Caffe、MXNet框架,这些框架与开源接口兼容。在数据源方面,PAI2.0支持非结构化、结构化等各种数据源;在计算资源方面,支持CPU、GPU、FPGA等异构计算资源;在工作流方面,支持模型训练和预测一体化。
PAI已经在阿里巴巴内部使用了2年。基于该平台,在淘宝搜索中,搜索结果会基于商品和用户的特征进行排序。
百度深度学习平台
百度深度学习平台是一个面向海量数据的深度学习平台,基于PaddlePaddle和TensorFlow开源计算框架,支持GPU运算,为深度学习技术的研发和应用提供可靠性高、扩展灵活的云端托管服务。通过百度深度学习平台,不仅可以轻松训练神经网络,实现情感分析、机器翻译、图像识别,也可以利用百度云的存储和虚拟化产品直接将模型部署至应用环境。
微博在Feed CTR、反垃圾、图片分类、明星识别、视频推荐、广告等业务上广泛使用深度学习技术,同时广泛使用TensorFlow、Caffe、Keras、MXNet等深度学习框架。为了融合各个深度学习框架,有效利用CPU和GPU资源,充分利用大数据、分布式存储、分布式计算服务,微博设计开发了微博深度学习平台。
微博深度学习平台支持如下特性:
-
方便易用
:支持数据输入、数据处理、模型训练、模型预测等工作流,可以通过简单配置就能完成复杂机器学习和深度学习任务。特别是针对深度学习,仅需选择框架类型和计算资源规模,就能模型训练。
-
灵活扩展
:支持通用的机器学习算法和模型,以及用户自定义的算法和模型。
-
多种深度学习框架
:目前支持TensorFlow、Caffe等多种主流深度学习框架,并进行了针对性优化。
-
异构计算
:支持GPU和CPU进行模型训练,提高模型训练的效率。
-
资源管理
:支持用户管理、资源共享、作业调度、故障恢复等功能。
-
模型预测
:支持一键部署深度学习模型在线预测服务。
微博深度学习平台是微博机器学习平台的重要组成部分,除继承微博机器学习平台的特性和功能以外,支持TensorFlow、Caffe等多种主流深度学习框架,支持GPU等高性能计算集群。微博深度学习平台架构如图1所示。
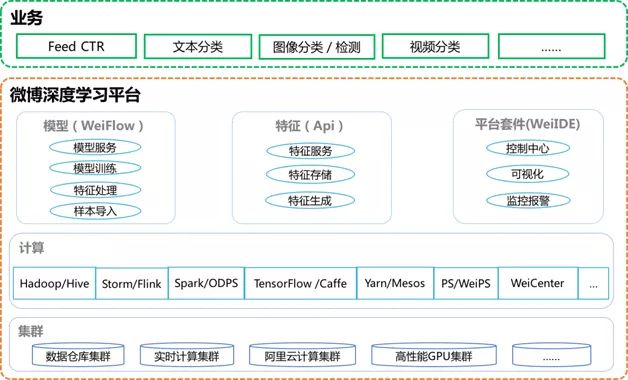
图1 微博深度学习平台架构
下面将以机器学习工作流、控制中心、深度学习模型训练集群、模型在线预测服务等典型模块为例,介绍微博深度学习平台的实践。
机器学习工作流WeiFlow
微博深度学习和机器学习工作流中,原始数据收集、数据处理、特征工程、样本生成、模型评估等流程占据了大量的时间和精力。为了能够高效地端到端进行深度学习和机器学习的开发,我们引入了微博机器学习工作流框架WeiFlow。
WeiFlow的设计初衷就是将微博机器学习流的开发简单化、傻瓜化,让业务开发人员从纷繁复杂的数据处理、特征工程、模型工程中解脱出来,将宝贵的时间和精力投入到业务场景的开发和优化当中,彻底解放业务人员的生产力,大幅提升开发效率。
WeiFlow的诞生源自于微博机器学习的业务需求。在微博的机器学习工作流中(如图2所示),多种数据流经过实时数据处理,存储至特征工程并生成离线的原始样本。在离线系统,对原始样本进行各式各样的数据处理、特征处理、特征映射,从而生成训练样本;业务人员根据实际业务场景(排序、推荐),选择不同的算法模型,进行模型训练、预测、测试和评估;待模型迭代满足要求后,通过自动部署将模型文件和映射规则部署到线上。线上系统根据模型文件和映射规则,从特征工程中拉取相关特征,根据映射规则进行预处理,生成可用于预测的样本格式,进行线上实时预测,最终将预测结果(用户对微博内容的兴趣程度)输出,供线上服务调用。
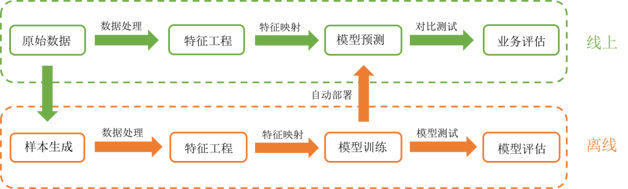
图2 微博机器学习工作流
为了应对微博多样的计算环境,WeiFlow采用了双层的DAG任务流设计,如图3所示。外层的DAG由不同的Node构成,每一个Node是一个内层的DAG,具备独立的执行环境,即上文提及的Spark、TensorFlow、Hive、Storm、Flink等计算引擎。
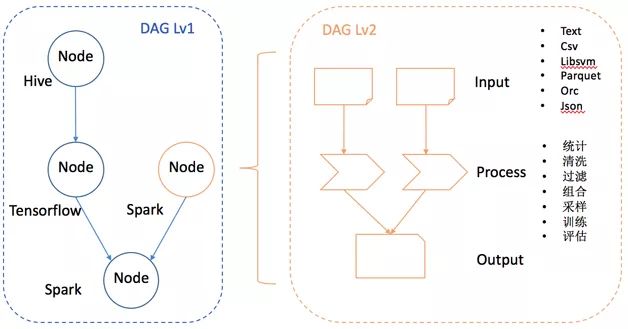
图3 WeiFlow双层DAG任务流设计
外层DAG设计的初衷是利用各个计算引擎的特长,同时解决各个计算引擎间的依赖关系和数据传输问题。内层的DAG,利用引擎的特性与优化机制,实现不同的抽象作为DAG中计算模块之间数据交互的载体。





