原文来源:github
作者:Gal Leibovich
「雷克世界」编译:嗯~阿童木呀、多啦A亮
 概述
概述
Coach是一个python强化学习研究框架,包含许多最先进算法的实施。
它公开了一组易用的API,用于对新的机器学习算法实验,并且通过新环境的简单集成解决问题。基本的强化学习组件(算法、环境、神经网络架构、探索策略……)是完全解耦的,因此扩展和重用现有的组件是毫不费力的。
训练智能体来解决环境问题是与运行一样简单:
python coach.py -p CartPole_DQN -r



上图来源英特尔®Nervana™网站的博客文章(https://www.intelnervana.com/reinforcement-learning-coach-intel)
安装
注意:Coach仅在Ubuntu 16.04 LTS上进行了测试。
Coach的安装程序将设置让使用者在OpenAI Gym环境上运行Coach所需的所有基本操作,用户可以通过运行以下命令,然后按照屏幕上显示的说明完成安装:
./install.sh
Coach创建一个虚拟环境并安装在其中以避免更改用户系统。
激活或停用Coach的虚拟环境:
source coach_env/bin/activate
deactivate
除了OpenAI Gym,还有其它几个环境已经进行测试并被支持。 请按照下面的“支持的环境”部分中的说明进行操作,以安装更多的环境。
GPU支持
TensorFlow
默认情况下,Coach的安装程序将安装今年8月发布的英特尔优化版的TensorFlow,而其默认是不支持GPU的。为了使Coach能够在GPU上运行,必须安装支持GPU的TensorFlow版本。这可以通过覆盖TensorFlow版本来完成:
pip install tensorflow-gpu
开始运行Coach
Coach支持TensorFlow和neon深度学习框架。
通过使用-f标志可以在TensorFlow和neon后台之间进行切换。
使用TensorFlow(默认):-f tensorflow
使用neon:-f neon
presets.py中有几个可用的预设。要列出所有可用的预设,请使用-l标志。
要运行预设,请使用:
python coach.py -r -p
例如:
1、使用策略梯度CartPole游戏环境:
python coach.py -r -p CartPole_PG
2、使用剪裁PPO算法的倒立摆:
python coach.py -r -p Pendulum_ClippedPPO -n 8
3、使用A3C的山地车游戏:
python coach.py -r -p MountainCar_A3C -n 8
4、使用Dueling网络和Double DQN算法的毁灭战士游戏基础级:
python coach.py -r -p Doom_Basic_Dueling_DDQN
5、使用混合蒙特卡罗的毁灭战士游戏生命值收集级:
python coach.py -r -p Doom_Health_MMC
按照与presets.py相同的模式,可以轻松地为不同级别或环境创建新的预设。
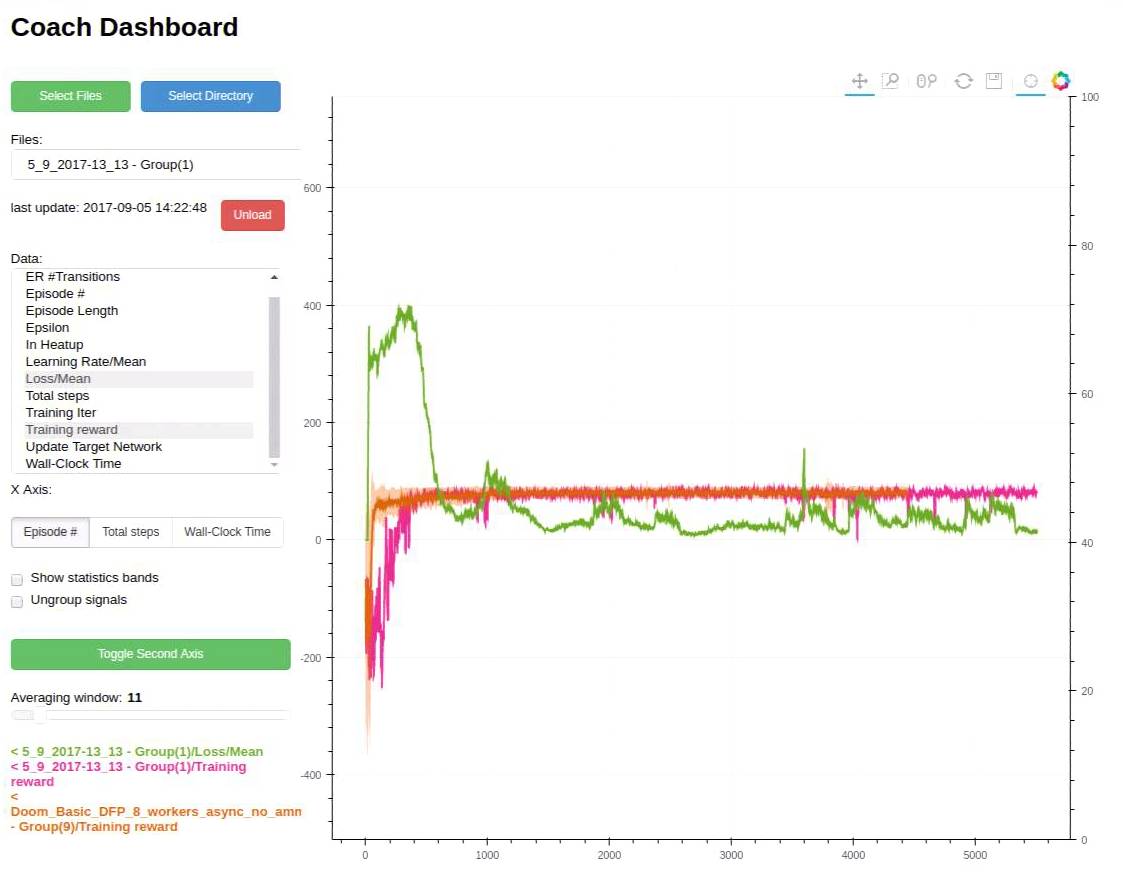
运行Coach仪表板(可视化)
一般说来,训练一个智能体来解决环境问题有时候是很棘手的。
有时为了调试训练过程,Coach会输出几个信号、每个经过训练后的算法,以便追踪算法性能。
当Coach在训练智能体时,一个包含相关训练信号的csv文件将保存到“实验”目录中,然后 Coach的仪表板可用于动态显示训练信号,并追踪算法表现。
如果想要使用它,可运行下面代码:
python dashboard.py
文档信息
有关框架文档、算法描述以及该如何构建一个新的智能体/环境的相关说明可点击链接查询阅读。(http://coach.nervanasys.com/)
并行化算法
自从在2016年引入A3C(https://arxiv.org/abs/1602.01783)以来,许多算法都已被证明在多个CPU内核上并行运行多个实例时可从中获益。到目前为止,这些算法涵盖了A3C、DDPG(https://arxiv.org/pdf/1704.03073.pdf)、PPO(https://arxiv.org/abs/1707.02286)和NAF(https://arxiv.org/pdf/1610.00633.pdf),而这极有可能只是一个开始。
使用Coach来并行化算法是很简单的。
下面的网络包装(NetworkWrapper)方法可以对算法进行无缝地并行化:
network.train_and_sync_networks(current_states, targets)
一旦并行运行开始启动,train_and_sync_networks API就会将每个本地worker的网络梯度应用到主要的全局网络,从而使得并行化训练得以开始。
然后,它只需要运行一个带有-n标志以及将要进行运行的worker的数量的Coach即可。例如,以下命令表示的是将要有16个worker协同合作以训练一个MuJoCo Hopper:
python coach.py -p Hopper_A3C -n 16
支持的环境
•OpenAI Gym
由Coach的安装程序默认安装。
•ViZDoom:
按照ViZDoom存储库中所描述的指令进行操作——https://github.com/mwydmuch/ViZDoom
另外,Coach假定变量环境VIZDOOM_ROOT直接指向ViZDoom安装目录。
•Roboschool:
按照roboschool存储库中所描述的指令进行操作——https://github.com/openai/roboschool
•GymExtensions:
按照GymExtensions存储库中所描述的指令进行操作——https://github.com/Breakend/gym-extensions
另外,将安装目录添加到变量环境PYTHONPATH中。
•PyBullet
按照快速入门指南中(Quick Start Guide)所描述的说明进行操作(基本上只是——'pip install pybullet')
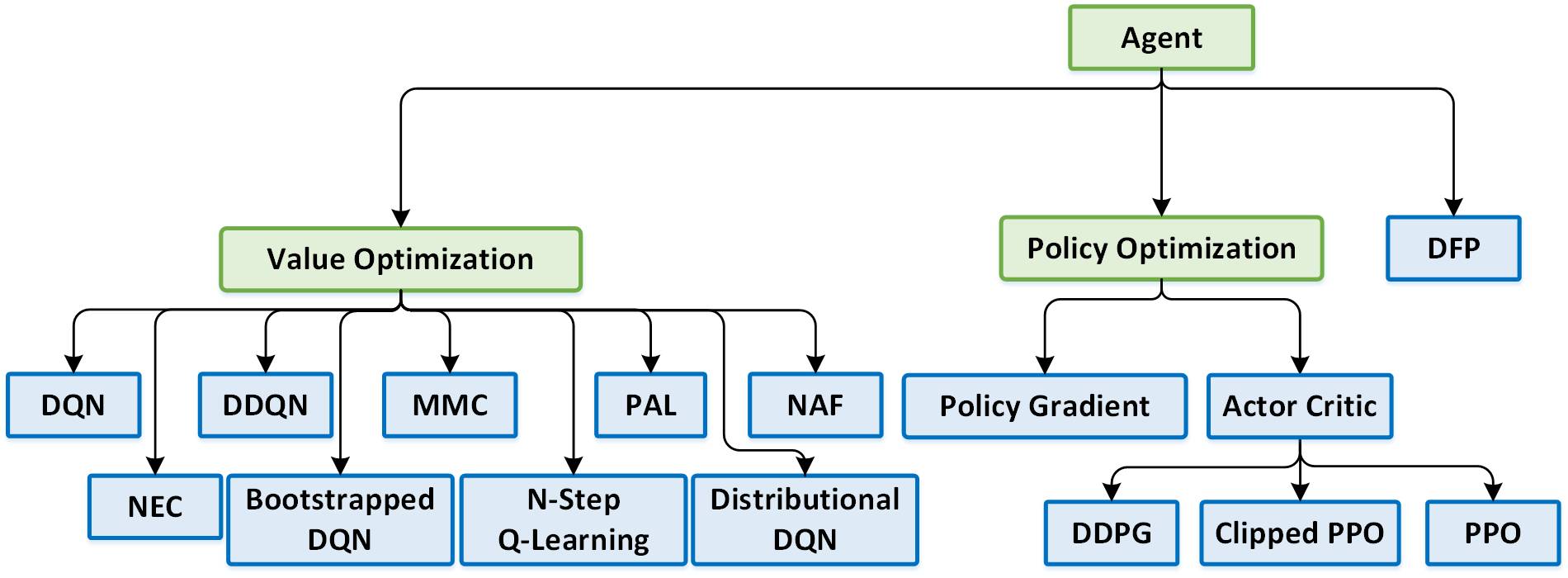
支持的算法
•深度Q网络(DQN)(https://www.cs.toronto.edu/~vmnih/docs/dqn.pdf)
•双重深度Q网络(DDQN)(https://arxiv.org/pdf/1509.06461.pdf)
•DuelingQ网络(https://arxiv.org/abs/1511.06581)
•混合蒙特卡罗(MMC)(https://arxiv.org/abs/1703.01310)
•一致性优势学习(PAL)(https://arxiv.org/abs/1512.04860)
•分布式深度Q网络(https://arxiv.org/abs/1707.06887)
•自举深度Q网络(https://arxiv.org/abs/1602.04621)
•N步Q学习|分布式(https://arxiv.org/abs/1602.01783)
•神经情景控制(NEC)(https://arxiv.org/abs/1703.01988)
•归一化优势函数(NAF)|分布式(https://arxiv.org/abs/1603.00748)
•策略梯度(PG)|分布式
(http://www-anw.cs.umass.edu/~barto/courses/cs687/williams92simple.pdf)
•演员评判家(Actor Critic)/ A3C|分布式(https://arxiv.org/abs/1602.01783)
•深度确定性策略梯度(DDPG)|分布式(https://arxiv.org/abs/1509.02971)
•近端策略优化(PPO)(https://arxiv.org/pdf/1707.02286.pdf)
•裁剪近策略优化|分布式(https://arxiv.org/pdf/1707.06347.pdf)
•直接未来预测(DFP)|分布式(https://arxiv.org/abs/1611.01779)
免责声明
Coach是出于研究目的作为参考代码发布的。这不是英特尔官方产品,质量和支持水平可能达不到官方预期水平。计划将附加算法和环境添加框架中,非常欢迎来自开源和RL研究社区的反馈和批评指正。
回复「转载」获得授权,微信搜索「ROBO_AI」关注公众号
中国人工智能产业创新联盟于2017年6月21日成立,超200家成员共推AI发展,相关动态:
中新网:中国人工智能产业创新联盟成立
ChinaDaily:China forms 1st AI alliance
证券时报:中国人工智能产业创新联盟成立 启动四大工程搭建产业生态“梁柱”
工信部网站:中国人工智能产业创新联盟与贵阳市政府、英特尔签署战略合作备忘录
 点击下图加入联盟
点击下图加入联盟

下载中国人工智能产业创新联盟入盟申请表

关注“雷克世界”后不要忘记置顶哟
我们还在搜狐新闻、雷克世界官网、腾讯新闻、网易新闻、一点资讯、天天快报、今日头条、雪球财经……
↓↓↓点击阅读原文查看中国人工智能产业创新联盟手册





