
作者 | 陈开江
推荐系统的框架大都是这个模式:多种召回策略,一种融合排序策略。召回策略姿势繁多,此处按下不表,单说最终的融合排序,最常见的就是CTR预估。这里说的CTR预估的C,可以是广义上的点击,包括我们视为关键动作的任何用户行为,如收藏、购买等。
CTR预估的常见做法就是广义线性模型,如Logistic Regression,外加特征海洋战术,这样做好处多多:
特征海洋战术让线性模型表现为一个很宽广(Wide)的模型。线性的宽模型要产生非线性效果,主要靠特征组合,尤其是二阶交叉,但如果交叉后的特征没有覆盖样本,那么交叉就然并卵。
近年来,深度学习异军突起,摧城拔寨,战火自然也烧到了推荐系统领域了,用深度神经网络来革“线性模型+特征工程”的命也再自然不过。用这种“精深模型”升级以前的“广博模型”,尤其是深度学习“端到端”的诱惑,让算法工程师们纷纷主动投怀送抱[1]。
深度学习在推荐领域的应用,其最大好处就是“洞悉本质般的精深”:优秀的泛化性能,可以给推荐很多惊喜。当然对应的问题就是容易过度泛化,会推荐得看上去像是“找不着北”,就是你们的PM和老板常问的那句话:“不知道怎么推出来的”,可解释性差一点。
既然深度模型有这么大的好处,广度模型也有诸多好处,根据人类的贪婪属性,下一秒就有人问“能都要吗?”,这时候Google站出来冷冷地说:当然。
Google公司去年提出一个新的推荐系统框架级别的解决方案,结合了传统的线性模型和当前火热的深度模型,应用在GooglePlay上的APP推荐,推荐效果提高非常明显[2]。
下面就为大家介绍一下这个方案的关键要素。
一个典型的推荐系统架构很类似一个搜索引擎。也是由检索(或称召回)和排序两部构成(图1),这在我们前面的搜索、推荐、广告三者架构能统一吗已经讨论过[3]。不过推荐系统的检索过程并不一定有显式的query,而通常是用户特征和场景特征。
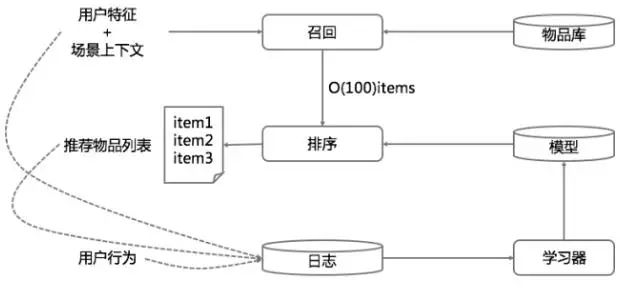
图1
推荐系统的“query”,最重要的当然就是用户特征,哪些可以做用户特征?并不只是标签和注册资料,可以说“六经注我”,凡是可以“注我”的皆为特征:显式的有标签,注册资料,喜欢过的物品,消费过的物品,在一些维度上的统计值,隐式的有一些话题模型,embedding(如word2vec)等等,并不只是人类可读的那些维度(PS:用户标签被一些擅长忽悠的公司和大众媒体换了个迷惑人的词语,叫做“用户画像”,通常还煞有介事的画成一个“人形”,真担心被有关部门解读为“标签成精”)
本文是关于广度和深度模型的结合,解决的是架构中的“学习”“模型”“排序”这三个地方的问题,所以上面这一段可以不读,当然现在说有点晚了(逃)。
现在来看看今天的主角:我们把它叫做“深宽模型”(Wide & Deep Model)。
首先,线性模型部分,也就是“宽模型”(图2左边),形式如下:
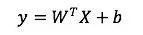
其中:
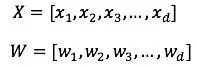
X是特征向量,W是模型参数向量,这个b是线性模型固有的偏见,哦不,偏置。线性模型中常用的特征构造手段就是特征交叉。例如:性别=女 and 语言=英语。就是由两个特征组合交叉而成,只有当“性别=女”取值为1,并且“语言=英语”也取值为1时,这个交叉特征才会取值为1。线性模型的输出这里采用的Logistic Regression。
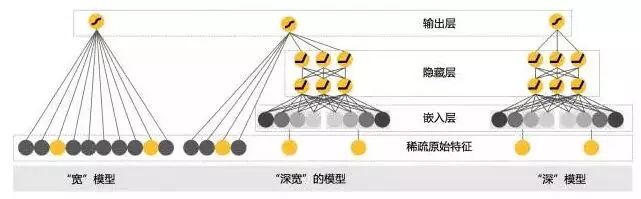
图2
然后,看看深度模型(图2右边)。深度模型其实就是一个前馈神经网络(Feedforward Neural Network)。深度模型对原始的高维稀疏类别型特征,先进行embedding,转换为稠密、低维的实值型向量,转换后的向量维度通常在10-100这个范围。至于怎么embedding,就是随机初始化embedding向量,然后直接扔到整个前馈网络中,用目标函数来优化。
前馈网络中每一个隐藏层激活方式如下:
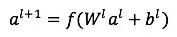
其中l表示第l个隐藏层,f是激活函数,通常选用ReLU(整流线性单元),为什么选用ReLU而不是LR,这个原因主要是LR在误差反向传播时梯度容易饱和(着急上车,来不及解释了,具体请参考任何一本深度学习教材)。ReLU及其他常用激活函数的形状见图3:
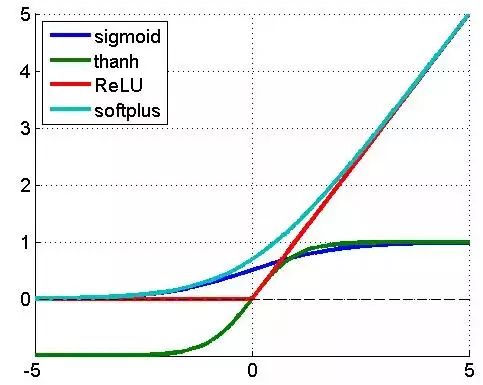
图3
最后,看看两者的融合,示意图见图2的中间部分。深模型和宽模型,由一个logistic regression模型作为最终输出单元。训练方法采用Joint Learning,这是什么?就是通常说的端到端(end-to-end),把深模型和宽模型以及最终融合的权重放在一个训练流程中,直接对目标函数负责,不存在分阶段训练。它与ensemble方法有区别,ensemble是集成学习,子模型是独立训练的,只在融合阶段才会学习权重。
为了对比试验,Google分别用JointLearning训练“深宽模型”(Wide&Deep),FTRL+L1训练“宽模型”(LR)[4],AdaGrad训练“深模型”(Feedforward Neural Network)。
融合结果以LR模型作为输出:
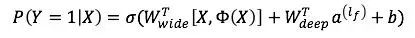
Y是我们要预估的行为,二值变量,如购买,或点击,Google原文是预估是否安装APP。σ是sigmoid函数,W_wide^T是宽模型的权重,Φ(X)是宽模型的组合特征,W_deep^T是应用在深模型输出上的权重,a^((l_f ) )是深模型的最后一层输出,b是线性模型的偏见,哦不,偏置。
整个深模型和宽模型的融合在图3的中间部分很好的展示了。










