导语:
1912年4月10日,号称 “世界工业史上的奇迹”的豪华客轮泰坦尼克号开始了自己的处女航,从英国的南安普顿出发驶往美国纽约,4月14日晚,泰坦尼克号在北大西洋撞上冰山而倾覆,1502人葬生海底,705人得救。造成了当时在和平时期最严重的一次航海事故,也是迄今为止最著名的一次海难。38岁的查尔斯·莱特勒是泰坦尼克二副,他是最后一个从冰冷的海水中被拖上救生船、职位最高的生还者。在他写的回忆录中,列举几个让人震撼的情景:
-
在第一艘救生艇下水后,我对甲板上一名姓斯特劳的女人说:你能随我一起到那只救生艇上去吗?没想到她摇了摇头:不,我想还是呆在船上好。她的丈夫问:你为什么不愿意上救生艇呢?这名女人竟笑着回答:不,我还是陪着你。此后,我再也没有见到过这对夫妇…
-
亚斯特四世(当时世界第一首富)把怀着五个月身孕的妻子玛德琳送上4号救生艇后,站在甲板上,带着他的狗,点燃一根雪茄烟,对划向远处的小艇最后呼喊:我爱你们!一副默多克曾命令亚斯特上船,被亚斯特愤怒的拒绝:我喜欢最初的说法(保护弱者)!然后,把唯一的位置让给三等舱的一个爱尔兰妇女……
-
斯特劳斯是世界第二巨富,美国梅西百货公司创始人。他无论用什么办法,他的太太罗莎莉始终拒绝上八号救生艇,她说:多少年来,你去哪我去哪,我会陪你去你要去的任何地方。八号艇救生员对67岁的斯特劳斯先生提议:我保证不会有人反对像您这样的老先生上小艇。斯特劳斯坚定地回答:我绝不会在别的男人之前上救生艇。然后挽著63岁罗莎莉的手臂,一对老夫妇蹒姗地走到甲板的藤椅上坐下,等待着最后的时刻…
-
新婚燕尔的丽德帕丝同丈夫去美国渡蜜月,她死死抱住丈夫不愿独自逃生,丈夫在万 般无奈中一拳将她打昏,丽德帕丝醒来时,她已在一条海上救生艇上了。此后,她终生未再嫁,以此怀念亡夫…
在这种生死存亡的紧要关头,我们常常认为社会等级越高、影响力越大,公众认可度越高的人物,生存的概率应该越大,其次,乘客家庭成员多,成员间的协作和对求生的渴望度越高,生存的概率越高。然而,很多时候,事情产生这样的结果的原因并非我们主观臆测的那样,我们需要通过对真实数据进行科学的分析,才能发现很多事情并非我们想象的那样简单,事情产生的本质,往往隐藏在数据之中
下面我们就使用R语言根据已知存活情况的数据建立分析模型来预测其他一部分乘客的存活情况,其中,训练数据和测试数据均来源于:
https://www.
kaggle.com/c/titanic
本文的代码和分析过程除部分修改外主体参考自Megan L. Risdal的文章:
Exploring Survival on the Titanic
一.数据的导入和查看
#有些包需要安装,我们专门建立一个packagemanger.R文件来管理它门,在工程主入口文件中先进行编译后导入进行使用
source('D:/R/RStudioWorkspace/titanic_test/utils/packageManager.R',encoding = 'UTF-8')
library('ggplot2') # 可视化
library('ggthemes') # 可视化
library('scales') # 可视化
library('dplyr') # 数据处理
library('mice') # 填充缺失数据
library('randomForest') # 分类算法
train
查看的数据结果如下:
'data.frame': 1309 obs. of 12 variables:
$ PassengerId: int 1 2 3 4 5 6 7 8 9 10 ...
$ Survived : int 0 1 1 1 0 0 0 0 1 1 ...
$ Pclass : int 3 1 3 1 3 3 1 3 3 2 ...
$ Name : chr "Braund, Mr. Owen Harris" "Cumings, Mrs. John Bradley (Florence Briggs Thayer)" "Heikkinen" ...
$ Sex : chr "male" "female" "female" "female" ...
$ Age : num 22 38 26 35 35 NA 54 2 27 14 ...
$ SibSp : int 1 1 0 1 0 0 0 3 0 1 ...
$ Parch : int 0 0 0 0 0 0 0 1 2 0 ...
$ Ticket : chr "A/5 21171" "PC 17599" "STON/O2. 3101282" "113803" ...
$ Fare : num 7.25 71.28 7.92 53.1 8.05 ...
$ Cabin : chr "" "C85" "" "C123" ...
$ Embarked : chr "S" "C" "S" "S" ...
我们观察到一共有1309条数据,每一条数据有12个相关变量
$ PassengerId: 乘客编号
$ Survived :存活情况(存活:1 ; 死亡:0)
$ Pclass : 客场等级
$ Name : 乘客姓名
$ Sex : 性别
$ Age : 年龄
$ SibSp : 同乘的兄弟姐妹/配偶数
$ Parch : 同乘的父母/小孩数
$ Ticket : 船票编号
$ Fare : 船票价格
$ Cabin :客舱号
$ Embarked : 登船港口
二.特征工程
特征工程: 为了达到预测模型性能更佳,不仅要选取最好的算法,还要尽可能的从原始数据中获取更多的信息。挖掘出更好的训练数据,就是特征工程建立的过程
2.1 观察乘客名称
注意到在乘客名字(Name)中,有一个非常显著的特点:乘客头衔每个名字当中都包含了具体的称谓或者说是头衔,将这部分信息提取出来后可以作为非常有用一个新变量,可以帮助我们进行预测。此外也可以用乘客的姓代替家庭,生成家庭变量。
# 从名称中挖掘
# 从乘客名字中提取头衔
#R中的grep、grepl、sub、gsub、regexpr、gregexpr等函数都使用正则表达式的规则进行匹配。默认是egrep的规则,sub函数只实现第一个位置的替换,gsub函数实现全局的替换。
total_data$Title
结果如下:
Capt Col Don Dona Dr Jonkheer Lady Major Master Miss Mlle Mme Mr Mrs Ms Rev Sir the Countess
female 0 0 0 1 1 0 1 0 0 260 2 1 0 197 2 0 0 1
male 1 4 1 0 7 1 0 2 61 0 0 0 757 0 0 8 1 0
我们发现头衔的类别太多,并且好多出现的频次是很低的,我们可以将这些类别进行合并
# 合并低频头衔为一类
rare_title
得到如下结果:
Master Miss Mr Mrs Rare Title
female 0 264 0 198 4
male 61 0 757 0 25
最后,从名称中获取到姓氏
#sapply()函数:根据传入参数规则重新构建一个合理的数据类型返回
total_data$Surname
2.2家庭成员数量的影响
既然我们已经根据乘客的名字划分成一些新的变量,我们可以把它进一步做一些新的家庭变量。首先我们要做一个基于兄弟姐妹/配偶数量(s)和儿童/父母数量的家庭规模变量。
# 创建一个包含乘客自己的家庭规模变量
total_data$Fsize
结果如下:
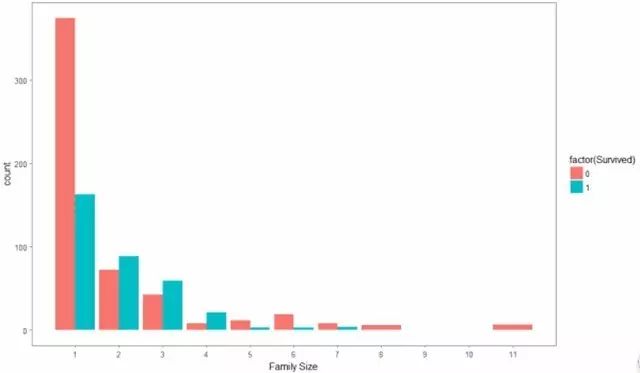
2.3客舱位置的影响
可以发现在乘客客舱变量 passenger cabin 也存在一些有价值的信息如客舱层数 deck,但是这个变量的缺失值太多,无法做出新的有效的变量,暂时放弃这个变量的挖掘
三.缺失数据的处理
观察文件中的数据,我们会发现有些乘客的信息参数并不完整,由于所给的数据集并不大,我们不能通过删除一行或者一列来处理缺失值,因而对于我们关注的一些字段参数,我们需要根据统计学的描述数据(平均值、中位数等等)来合理给出缺失值
我们可以通过函数查看缺失数据的变量在第几条数据出现缺失和总共缺失的个数
3.1年龄的缺失和填补
#统计年龄的缺失个数
age_null_count
通常我们会使用 rpart (recursive partitioning for regression) 包来做缺失值预测 在这里我将使用 mice 包进行处理。我们先要对因子变量(factor variables)因子化,然后再进行多重插补法。
#统计年龄的缺失处理
age_null_count
让我们来比较一下我们得到的结果与原来的乘客的年龄分布以确保没有明显的偏差
# 绘制直方图
par(mfrow=c(1,2))
hist(total_data$Age, freq=F, main='Age: Original Data',
col='darkgreen', ylim=c(0,0.04))
hist(mice_output$Age, freq=F, main='Age: MICE Output',
col='lightgreen', ylim=c(0,0.04))
结果如下,右边图和左边图有很高的相似度
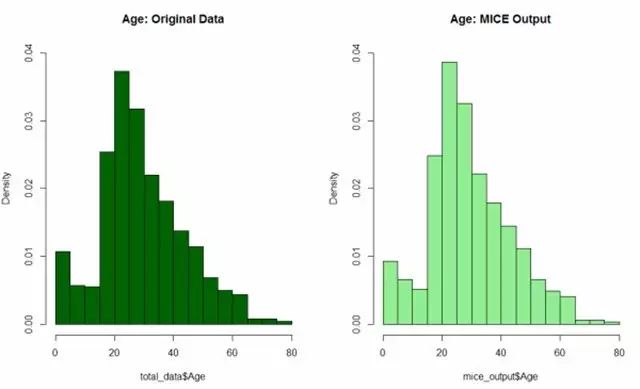
所以,我们可以用mice模型的结果对原年龄数据进行替换。
# 用mice模型数据替换原始数据
full$Age
3.2票价的缺失处理
#查看票价的缺失值
getFareNullID
得到票价缺失个数为1 ,缺失行数为第1044行
查看这一行我们会发现
total_data[1044,]
PassengerId Survived Pclass Name Sex Age SibSp Parch Ticket Fare Cabin
1044 1044 NA 3 Storey, Mr. Thomas male 60.5 0 0 3701 NA
Embarked Title Surname Fsize Family
1044 S Mr Storey 1 Storey_1
我们发现港口和舱位是完整的,我们可以根据相同的港口和相同的舱位来大致估计该乘客的票价,我们取这些类似乘客的中位数来替换缺失的值
#从港口Southampton ('S')出发的三等舱乘客。 从相同港口出发且处于相同舱位的乘客数目
same_farenull
3.3登船港口号的缺失处理
#登船港口号的缺失值函数
getEmbarkedNullCount
得到登船港口号缺失的个数为2 ,分别为 62 、830,我估计对于有相同舱位等级(passenger class)和票价(Fare)的乘客也许有着相同的 登船港口位置embarkment .我们可以看到他们支付的票价分别为: $ 80 和 $ 80 同时他们的舱位等级分别是: 1 和 1 . 我们可以用箱线图绘制出这三者之间关系图
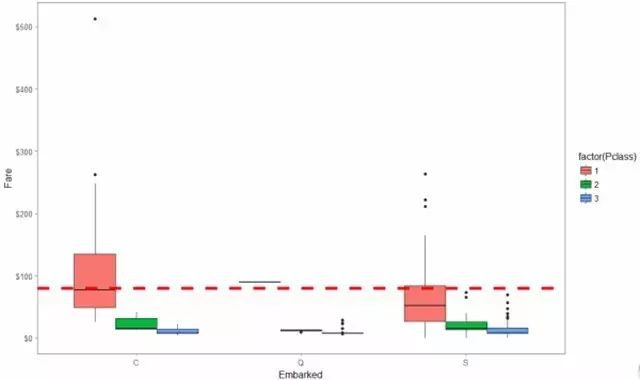
从港口 (‘C’)出发的头等舱支付的票价的中位数正好为80。因此我们可以放心的把处于头等舱且票价在$80的乘客62和830 的出发港口缺失值替换为’C’
total_data$Embarked[c(62, 830)]
我们基本上完成了重要参数缺失值的处理,我们的数据集变得更加完整了呢,接下来,需要根据新的数据集创建出新的特征工程
四.新特征工程的建立
通过上面缺失值填补的完成,我们试着在新的数据集中挖掘出对乘客的存活有影响的一些因素,根据文章刚开始的几段真实场景预测,我们考虑在这种灾难性的时刻,小孩和老人相对于青年或者中年人应该会得到更好的照顾,生存的概率应该更高,其次,如果你是一位母亲,你相比于其他成年女性是否会有更高的存活可能?其实我还有一个想法,那就是乘客的社会地位或者说阶层 和当时的收入水平层次可能对生存有一定的影响,当然这两个因素对于现在的我们来说非常难以获取,毕竟事情发生在100多年前,或许当时的政府,也需要很长时间才能准确的获取到觉大部分人的这些侧面信息。
4.1年龄的划分
我们考虑将年龄划分成三个阶段,小于18岁算小孩,18岁及以上至50岁为青壮年,50岁以上为老年人
#将年龄划分成3个阶段
total_data$AgeGroup[total_data$Age = 18 & total_data$Age 50]
相比于成人,小孩的生存概率接近50%,小孩得到的照顾比成年高的多
4.2是否为母亲
我们从性别和头衔中提炼出一位成年女性是否为一位母亲,看看她的生存概率如何
# Adding Mother variable
total_data$IsMother 0 & total_data$Age > 18 & total_data$Title != 'Miss']
我们发现,如果是一位母亲,那么你生存下来的概率高达70%,之后,我们整合上面两个新变量到原数据集
# 完成因子化
total_data$AgeGroup
五.预测
到了最激动人心的时刻了有没有,前面四个步骤都是为了预测在做前期准备,如何进行预测呢?
5.1.拆分测试和训练数据集
#拆分数据集
train
5.2 构建训练模型
我们使用随机森林法则作用于训练数据集来构建我们需要的预测模型
#拆分数据集
train
结果如下
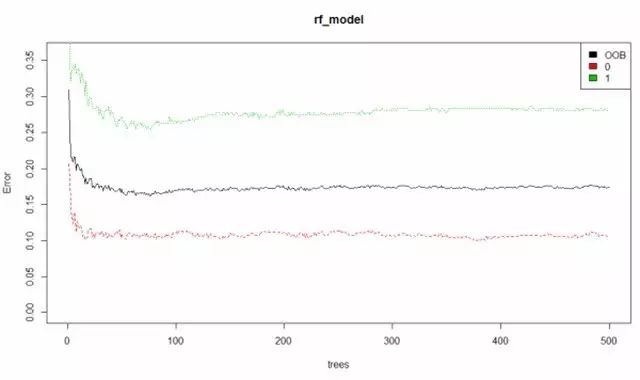
黑色那条线表示:整体误差率(the overall error rate)低于20% 红色和绿色分别表示:遇难与生还的误差率 至此相对于生还来说,我们可以更准确的预测出死亡。
5.3相关性检测
通过随机森林中所有决策树的Gini 计算出其他变量相对于生存变量的相关性排行,我们可以看出那些因素对生存率影响较大
# 重要性系数
importance %
mutate(Rank = paste0('#',dense_rank(desc(Importance))))
# 使用 ggplot2 绘出重要系数的排名
ggplot(rankImportance, aes(x = reorder(Variables, Importance),
y = Importance, total_data = Importance)) +
geom_bar(stat='identity') +
geom_text(aes(x = Variables, y = 0.5, label = Rank),
hjust=0, vjust=0.55, size = 4, colour = 'red') +
labs(x = 'Variables') +
coord_flip() +
theme_few()
结果如下:
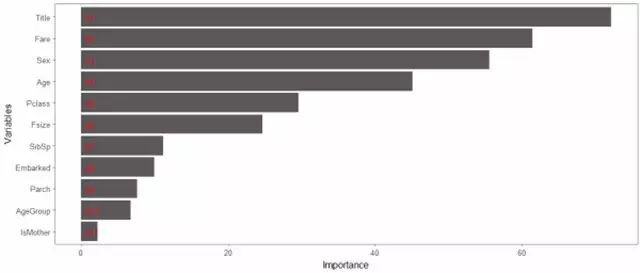
我们发现,头衔称号和船票价格及性别年龄对生存率的影响比较大,我们刚刚认为的小孩、老人和是否为母亲 这几个特征应该有很大的生存几率,但是结果并不是这样,现实还是比较残酷!
5.4预测
最后,我们使用训练好的特征模型作用于测试数据上,得到我们的预测结果
#预测
prediction
得到预测结果文件,我们可以上传到Kaggle,查看自己的排名情况,





