近日一篇“A guide to small-molecule structure assignment through computation of (1H and 13C) NMR chemical shifts”文章火爆网络,据作者看到的资料上看这篇论文自身的结果没有什么问题,但是,这篇论文附带了一份 Pyhon 程序,这个附带的 Python 脚本会出现一定问题。为了深入分析,作
者第一时间下载了相关代码。
https://media.nature.com/original/nature-assets/nprot/journal/v9/n3/extref/nprot.2014.042-S2.zip
https://www.nature.com/articles/nprot.2014.042
从目前看到的资料上看,这个BUG出现在读入“Gaussian Output Files”,这个函数,在不同的操作系统下会有不同的输出结果。
如果读者也下载了相关代码会看到这篇论文本身带有For Python2和Python3两个套脚本,不过读取高斯输出文件的写法没有什么不同,分别在\nprot.2014.042-S2\Supplementary Data 2\Python Scripts (for Python v2)\nmr-data_compilation.py和\nprot.2014.042-S2\Supplementary Data 2\Python Scripts (for Python v3)\nmr-data_compilation.py的函数read_gaussian_outputfiles下,其函数具体内容如下:
def read_gaussian_outputfiles(): list_of_files = [] for file in glob.glob('*.out'): list_of_files.append(file) return list_of_files
从上述文件中我们可以看到这个函数是使用 glob.glob('*.out'):来添加相关文件的,这个函数本身没有任何排序的行为,而且从Main函数的情况看,其所有后续处理也全部是依赖read_gaussian_outputfiles函数的返回的,具体代码如下:
def main(): lofc = read_gaussian_outputfiles() lofc_freq = read_gaussian_freq_outfiles(lofc) lofc_nmr = read_gaussian_nmr_outfiles(lofc) locs = prepare_list_of_chemical_shifts(lofc_nmr) lofe = get_list_of_free_energies(lofc_freq) lofe = boltzmann_analysis(lofe) lofe = report_chemical_shifts(lofc_nmr, lofe) summed_proton_shifts = final_proton_chemical_shifts(lofe) summed_carbon_shifts = final_carbon_chemical_shifts(lofe) lofe = count_imaginary_freq(lofc_freq, lofe) write_final_shift_csv(summed_proton_shifts,summed_carbon_shifts) write_master_csv(lofe)
那么这个 glob.glob函数是否会带排序功能呢,可以打开你\Python的根目录\Lib\glob.py来找到答案可以看到glob.glob函数的定义及官方说明如下,这个函数可以支持递归,但是没有说会自动排序。
def glob(pathname, *, recursive=False): """Return a list of paths matching a pathname pattern. The pattern may contain simple shell-style wildcards a la fnmatch. However, unlike fnmatch, filenames starting with a dot are special cases that are not matched by '*' and '?' patterns. If recursive is true, the pattern '**' will match any files and zero or more directories and subdirectories. """
而且从这个glob方法的具体实现iterdir函数上看也没有进行排序,这个iterdir是靠os.scan来进行添加文件的。
def _iterdir(dirname, dironly): if not dirname: if isinstance(dirname, bytes): dirname = bytes(os.curdir, 'ASCII') else: dirname = os.curdir try: with os.scandir(dirname) as it: for entry in it: try: if not dironly or entry.is_dir(): yield entry.name except OSError: pass except OSError: return
那么再打开你\Python的根目录\Lib\os.py可以看到scandir其实就是系统调用,也就是说这个python脚本调用了glob.glob方法来读入文件,glob.glob方法就调用iterdir方法操作,而最终调用的os.scan又完全依赖于系统的行为。所以在不同系统中会有不同返回就可想而知了。
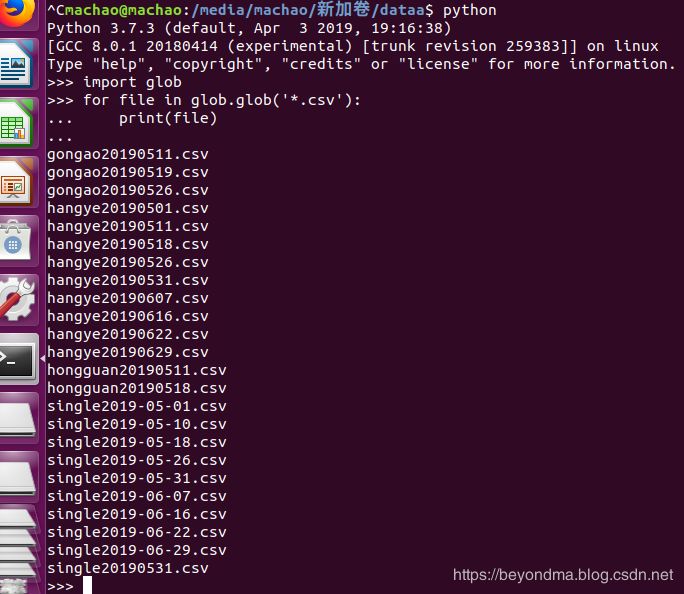
不过问题可以也不会像想象的那样严重,因为笔者在WINDOWS10和UBANTU18上对glob.glob方法进行测试的结果还都是对文件名升序排序的,也就是与预期一致。
不过这个BUG也反应出学术界的一些问题,一是没有像GITHUB这样的开源平台,学界对论文复现,肯定不像IT业这么普及,二是非IT学术界的编程能力其实堪忧,但是目前很多论文都有关数据分析,还是需要一定的编程能力的,而且一旦某一顶级论文附带脚本出现BUG,其影响可能特别巨大。
版权声明:
本文为CSDN博主「beyondma」的原创文章,转载请附上原文出处链接及本声明。
https://blog.csdn.net/BEYONDMA/article/details/102555199
换个姿势阅读?
扫码试试~
(*本文为 AI科技大本营约稿文章,
转
载请微
信联系 1092722531
)
2019 中国大数据技术大会(BDTC)再度来袭!豪华主席阵容及百位技术专家齐聚,15 场精选专题技术和行业论坛,超强干货+技术剖析+行业实践立体解读,深入解析热门技术在行业中的实践落地。










