
视频的内容语义提取的技术,整理有以下几种:
1. 提取视频中的商品
应用场景:比如下面的视频,发现视频中正在展示有电视、帽子、相框,那么就可以推送电视、帽子、相框相关的广告。

实现方式:首先人工标注,然后深度学习。
首先看一个人工标注的案例:
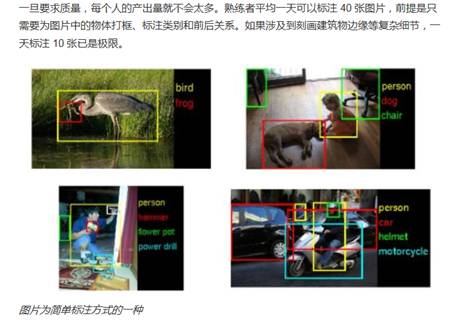
来源:特写|人工智能背后的人 - 知乎专栏
深度学习的结果可以看谷歌现在开源的:搜google video intelligence,可能要翻墙。
谷歌基本上把视频中的物体都可以识别出来,已经非常智能。
适用视频类型:有人物和物品的,有品牌的;
适用场景:电商类,商品类广告;
优势:智能。我们现在看电视剧时,会发现电视剧已经用人工做了这事了,比如三生三世的夜华的长发一垂下来,立刻就推出了洗发水的广告。随着热巴火,贴片广告就放成了热巴代言的品牌。
但是,当面对数万的视频,特别是短视频市场还在快速增长时,就需要机器来完成。
劣势:
比较容易识别出名词来,动词比较难;比如能够识别出“篮球”,但是不能识别“打篮球”。(深度学习可以做到,但是谷歌这个开源没有)
能够识别,但不能判断,比如图片质量的好坏,等。
2. 对视频内容的语义进行关键词提取;
1) 对视频的帧截图:
l 有的是截每一帧;
l 有的是镜头转换时再截,如何判断视频的镜头是否转换呢?计算前后两个图片的差距,差的很多,说明镜头换了,需要再截图。
2) 对截图进行语义识别;
3) 将视频的语音转换成文字;
4) 对文字进行语义识别
5) 将上述截图得到的语义和文字得到的语义综合在一起,就是这个视频的语义;
技术的原话是,“视频内容ffmpeg到声音,语音识别变字幕,nlp处理字幕得到词向量和文档相似度。”,上面是我自己看了一些资料理解的。
优势:比如教育类,视频上的文字内容非常多。
劣势:其他类型的视频文字可能就没这么多了,不足以拆解出语义来。
3. 对标题进行关键词提取;
这种属于对纯文本的提取。词本身的重要程序、词所在的位置,标题比内容重要,前面比后面重要,词频,词的整体出现顺序,综合起来。
优势:计算简单,业内对文本的处理非常成熟,各种算法开源包都很方便。确实能提取出内容来,比如下图是秒拍的转发量前50的短视频的标题,可以看到基本都能覆盖视频的主要内容;

劣势:
标题党问题;
还有一些确实是标题无法分辨具体内容;比如说,有一个视频的标题叫:耳朵怀孕了。视频:一个人唱歌。机器可以识别有个人在唱歌,从开始唱到结束。但是机器不理解为什么标题叫耳朵怀孕了。
4. 对内容人工打标签;
分两块:
l 上述第一种处理方式的人工部分。那篇文章写得也很清楚,我就不多写了。
l 人工编目。这个可以看看豆瓣和视频网站怎么做的,就是比它们界面上显示的标签更细一两层。
l 一些人工打上标签后机器也不能自己学习的,或者学习起来比较吃力,比如场景,还是要靠人工打。
5. 总结
最开始调研的时候,只是想看看业内最先进的方式是什么。但是看下来发现,每一种都只能覆盖一个类目的视频的需求,比如第一种,更适合电视剧或者综艺,如果碰到动漫,就几乎没有作用了。
所以在使用的时候,对每一种类目,都深入分析其视频类型,确定哪一种语义提取方式为主,并且多种方式混合的规则是什么。
要从应用场景往回推,才能推出这一类视频需要哪一种语义提取的方式。
End.
作者:楠楠 (中国统计网特邀认证作者)






