算法的诞生
AI 39年(公元1995年),扁鹊成立了一家专治某疑难杂症的医院,经过半年的精心筹备,硬件设施已全部到位,只缺经验丰富的医生前来坐诊。找几个猎头打听了一下,乖乖,请一个资深专家(总监头衔的),一年的工资就得250万。这恐怕还不够去知名搜索引擎投放广告!
穷则思变,扁鹊院长想来想去,找到了两个天才的顾问,名叫Freund和Schapire,想请他们出出主意,怎样用较低的成本解决医生的问题。这两位老兄想到了同一个点子:
三个臭皮匠,赛过诸葛亮
我们玩人海战术!不如去医学院招一批应届生,给他们训练一段时间然后上岗,组成一个会诊小组,一起来给病人看病,集体决策。扁鹊很快招来了8个年轻的新手:
赵大夫,钱大夫,孙大夫,李大夫,周大夫,吴大夫,郑大夫,王大夫
怎么训练这些新人呢?两个顾问设计出了一套培训方案:
1.用大量的病例让这些新手依次学习,每个大夫自己琢磨怎样诊断,学习结束后统计一下每个人在这些病例上的诊断准确率
2.训练时,前面的大夫误诊的病例,后面的大夫要重点学习研究,所谓查缺补漏
3.训练结束之后,给每个大夫打分,如果一个大夫对病例学习的越好,也就是说在这些学习的病例集上诊断的准确率越高,他在后面诊断病人时的话语权就越大
扁鹊院长跑到其他医院买回了1万个病例,这些病例是这样的:
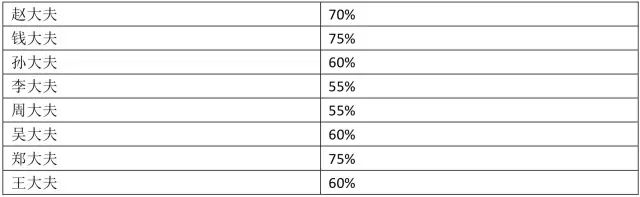
接下来培训过程开始了。首先接受培训的是赵大夫,经过学习总结,他摸索出了一套诊断规则,这套规则表现很不错,至少在学习用的病例集上,达到了70%的诊断准确率。学习完成之后,他给每一条病例调整了权重,被他误诊的病例,权重增大,诊断正确的病例,权重调小,以便于后面的医生有重点的学习。
接下来让钱大夫学习,他同样学习这些病例,但重点要关注被赵大夫误诊的那些病例,经过一番训练,钱大夫达到了75%的准确率。学习完之后,他也调整了这些病例的权重,被他误诊的病例,加大权重,否则减小权重。
后面的过程和前面类似,依次训练孙大夫,李大夫,周大夫,吴大夫,郑大夫,王大夫,每个大夫在学习的时候重点关注被前面的大夫误诊的病例,学习完之后调整每条病例的权重。这样到最后,王大夫对前面这些大夫都误诊的病例特别擅长,专攻这些情况的疑难杂症!
学习期结束之后,扁鹊院长汇总出了这8个大夫的诊断准确率:
当所有大夫都培训完成之后,就可以让他们一起坐堂问诊了。Freund和Schapire设计出了这样一套诊断规则:来一个病人之后,8个大夫一起诊断,然后投票。如果一个大夫之前在学习时的诊断准确率为p,他在投票时的话语权是:
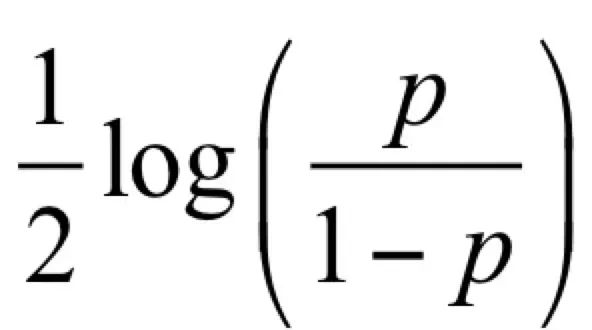
后面Freund和Schapire会解释这个规则的来由。按照这个计算规则,8个大夫的话语权为:
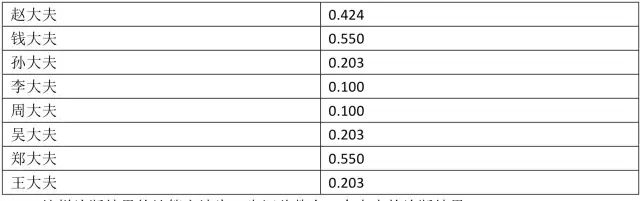
这样诊断结果的计算方法为,先汇总整合8个大夫的诊断结果:

在这里对病人的诊断结果有两种可能,阳性和阴性,我们量化表示,+1表示阳性,-1表示阴性。
最后的诊断结果是:如果上面计算出来的s值大于0,则认为是阳性,否则为阴性。
第一个病人来了,8个大夫一番诊断之后,各自给出了结果:
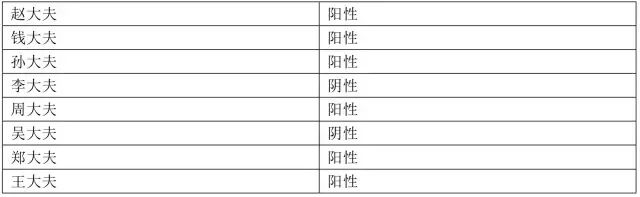
现在是投票集体决策的时候了。投票值为:
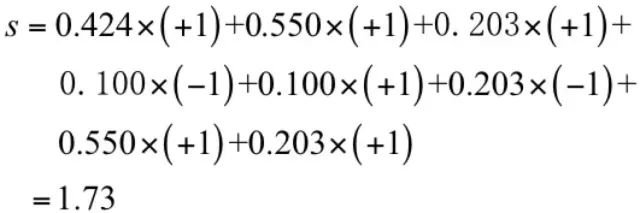
按照规则,这个病人被判定为阳性。医院运营了3个月,效果出奇的好,扁鹊院长统计了一下,诊断准确率居然高达95%,不比一个资深老专家差!每个医生一年的工资10万,8个医生总共才80万,这比请一个资深专家要便宜170万,太划算了!
这次成功之后,Freund和Schapire决定把这种方法推广到其他行业,用于解决一些实际问题。这些行业要解决的问题都有一个特点:要做出一个决策,这个决策有两种可能,例如银行要根据客户的收入、负债情况、信用记录等信息决定给客户贷款还是不贷款;人脸识别公司要判断一张图像是人脸还是不是人脸。这就是机器学习中的二分类问题,给定一个样本数据,判断这个样本的类别。对于上面的疾病诊断来说,样本数据就是病人的各项检查数据,类别是阴性和阳性。两位天才给这种方法取了一个名字:
AdaBoost算法
就这样,机器学习算法家族中的一个年轻小伙伴诞生了,没有想到,他后来在很多应用中都大显身手而被载入史册。(本故事纯属虚构)
集成学习
AdaBoost算法是一种集成学习(ensemble learning)方法。集成学习是机器学习中的一类方法,它对多个机器学习模型进行组合形成一个精度更高的模型,参与组合的模型称为弱学习器(weak learner)。在预测时使用这些弱学习器模型联合起来进行预测;训练时需要用训练样本集依次训练出这些弱学习器。典型的集成学习算法是随机森林和boosting算法,而AdaBoost算法是boosting算法的一种实现版本。
强分类器与弱分类器
AdaBoost算法的全称是自适应boosting(Adaptive Boosting),是一种用于二分类问题的算法,它用弱分类器的线性组合来构造强分类器,可以看成是前面介绍的新手大夫会诊例子的抽象。
弱分类器的性能不用太好,仅比随机猜测强,依靠它们可以构造出一个非常准确的强分类器。强分类器的计算公式为:

强分类器的输出值也为+1或-1,同样对应于正样本和负样本,也就是医生集体会诊的结果。这里的强分类器模型就是这就是上面的诊断规则的抽象化。弱分类器和它们的权重通过训练算法得到,后面我们会介绍。之所以叫弱分类器,是因为它们的精度不用太高,对于二分类问题,只要保证准确率大于0.5即可,即比随机猜测强,随机猜测也有50%的准确率。在上面的例子中,即使每个医生的准确率只有60%-75%,集体决策的准确率仍然能够达到95%以上。这种看似简单的组合,能够带来算法精度上的大幅度提升。
训练算法
下面来看AdaBoost算法的模型是怎么训练出来的,这是训练8位医生过程的抽象。算法依次训练每一个弱分类器,并确定它们的权重值。
在这里,训练样本带有权重值,初始时所有样本的权重相等,在训练过程中,被前面的弱分类器错分的样本会加大权重,反之会减小权重,这样接下来的弱分类器会更加关注这些难分的样本。弱分类器的权重值根据它的准确率构造,精度越高的弱分类器权重越大。
给定l个训练样本(xi , yi ),其中xi是特征向量,yi为类别标签,其值为+1或-1。训练算法的流程为:

根据计算公式,错误率低的弱分类器权重大,它是准确率的增函数。沿用医生集体会诊的例子,如果在之前的诊断中医生的技术更好,对病人情况的判断更准确,那么可以加大他在此次会诊时说话的分量即权重。弱分类器在训练样本集上的错误率计算公式为:

被上一个弱分类器错误分类的样本权重会增大,正确分类的样本权重减小,训练下一个弱分类器时算法会关注在上一轮中被错分的样本。这对应于每个医生在学习之后对病例权重的调整。给样本加权重是有必要的,如果样本没有权重,每个弱分类器的训练样本是相同的,训练出来的弱分类器也是一样的,这样训练多个弱分类器没有意义。AdaBoost算法的原则是:
关注之前被错分的样本,准确率高的弱分类器有更大的权重。
上面的算法中并没有说明弱分类器是什么样的,具体实现时应该选择什么样的分类器作为弱分类器?在实际应用时一般用深度很小的决策树,在后面将会详细介绍。强分类器是弱分类器的线性组合,如果弱分类器是线性函数,无论怎样组合,强分类器都是线性的,因此应该选择非线性的分类器做弱分类器。至此,我们介绍了AdaBoost算法的基本原理与训练过程,在后面的文章中,我们会介绍这种算法的理论依据,以及其他版本的实现,在现实问题中的应用。
文章来源:SigAI

《机器读心术之神经网络与深度学习》课程通过学习熟悉神经网络技术和深度学习,懂得怎样运用到自己的实际工作,设计有一定规模的学习系统,智能化地解决某些场景的实际问题。
点击下方二维码报名课程






