基因表达主要是由转录和翻译两部分构成的。但研究发现,mRNA水平并不能完全代表对应的蛋白质水平,两者之间的相关性仅为约0.6,并且相关性在不同细胞类型和组织中具有差异性。尽管已有大量数据和算法用于评估遗传变异对转录的影响,但mRNA与蛋白质水平之间存在的差异阻碍了对疾病相关变异调控作用的系统性理解。
另一方面,93%以上与人类疾病相关的变异位于非编码区,其中也包括了一部分位于mRNA非翻译区(5’UTR或3’UTR)的疾病位点,这些位点无法直接改变蛋白质序列。尽管已有大量研究致力于阐明这些变异在mRNA表达层面的调控及其在介导疾病中的意义,但大部分非编码疾病位点的机制仍未被完全解释,因此亟需在翻译的层面上解析这部分非编码的疾病位点的机制。


2024年10月23日,浙江大学良渚实验室/附属第二医院熊旭深课题组在Nature Machine Intelligence发表了题为Deep learning prediction of ribosome profiling with Translatomer reveals translational regulation and interprets disease variants的研究论文,发展了基于Transformer架构的多模态深度学习模型Translatomer(以Translatome和Transformer的结合词命名)用于预测细胞特异性翻译过程,填补了mRNA表达与蛋白质水平之间的差距,解析了复杂疾病的遗传变异对基因翻译的调控作用,为机制未知的疾病相关遗传变异提供了全新的分子机制见解。
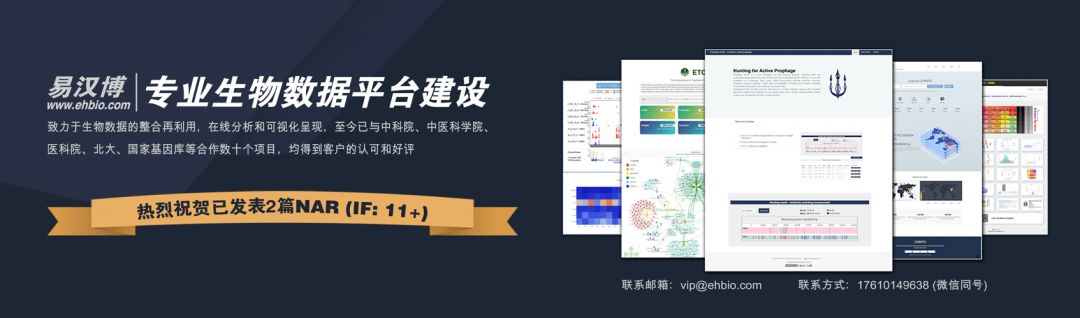
Translatomer模型整合了基因序列和RNA-seq数据作为多模态输入,模型输出是以核糖体印记(ribosome profiling)信号作为代表的翻译组。Translatomer是由输入层、Transformer主干层以及输出层组成。
首先每个基因的RNA-seq和以one-hot编码表示的基因序列会被编码为512维的token,并进行信号的合并作为Translatomer的输入。在Translatomer模型中,输入会先经过一个一维的卷积层(输入层)编码输入数据,然后经过一个由12层包含自注意力的Transformer组成的主干模块提取RNA-seq和基因序列的交互特征,最后经过一个输出层将信号解码为核糖体印记信号(如图所示)。Translatomer整合了来自33种不同组织或细胞系的基因序列和mRNA表达(RNA-seq)数据,能够准确地从头预测翻译信号,并捕捉到与翻译调控相关的序列特异性信息。在多个类型的细胞或组织的数据集中,模型从头预测的准确度达到了0.72-0.80,显著优于其他同类模型。此外,模型充分利用了RNA-seq作为输入的信息,获得了细胞类型特异性(context-dependent)预测的能力, 
随后,研究者发展了两种模型的可解释性算法和工具。在第一种解释算法中,通过计算梯度加权输入分数定量分别评估了基因序列和RNA-seq两种输入信息对翻译预测的贡献。结果表明RNA-seq对翻译的预测贡献总体上高于基因序列,符合生物学上翻译主要由mRNA水平决定的这一事实。其中,编码区对翻译的贡献最大,内含子的贡献最小。此外,5' UTR(转录起始区域)对翻译调控的影响显著高于3' UTR,说明翻译起始过程在调节基因翻译强度方面至关重要。在第二种解释性算法中,研究者依赖Translatomer进一步开发出了计算模拟突变(in silico mutation)工具,能够利用Translatomer模型精准预测剪辑突变对所在基因的翻译效率的影响,并利用了Kozak元件和荧光报告系统对计算模拟突变算法的准确性进行了验证。利用该工具,研究者发现与翻译调控相关的遗传变异在物种进化中受到了选择压力。
在建立起Translatomer模型以及可解释性工具后,研究者进一步鉴定了3041个影响翻译效率的复杂疾病遗传位点。这些疾病位点是同义突变位点或位于非翻译区;尽管这些变异不会直接改变蛋白质序列,但通过影响翻译过程,它们对多种复杂疾病的发生产生了重要影响。通过与基因表达数量遗传性状(eQTL)作进一步的整合分析,研究者发现这部分位点不会对mRNA的水平产生影响,因此揭示了这些遗传疾病位点的机制是通过特异地影响翻译过程从而调控疾病的发生发展。此外,这些遗传疾病位点对于翻译的影响也具有组织/细胞类型特异性,例如阿尔兹海默症、自闭症等疾病相关位点对翻译的调控特异地发生在大脑组织,而心肌病、心衰等疾病相关位点则在心脏中产生特异的翻译调控。
综上所述,该深度学习模型Translatomer为领域提供了研究基因翻译调控的新工具,还为解释复杂疾病中的遗传变异提供了除了mRNA水平之外的重要机制基础。通过分析不同细胞类型中的特异性翻译调控,为未来的疾病诊断和个性化治疗开辟了新的层次和靶点。
浙江大学熊旭深课题组科研助理何佳临和麻省理工学院熊磊(现为斯坦福大学博士后)为该论文的共同第一作者,浙江大学良渚实验室/附属第二医院熊旭深研究员和熊磊博士为该论文的共同通讯作者。浙江大学李静云研究员、胡新央教授、毛圆辉研究员、麻省理工理工学院Manolis Kellis教授、Carles A.Boix博士以及Xiong Lab多名成员对该工作做出重要贡献。
原文链接:https://www.nature.com/articles/s42256-024-00915-6
熊旭深博士于2022年12月份加入浙江大学良渚实验室/附属第二医院,主要进行生物信息、人工智能以及癌症异质性研究,已搭建起成熟的服务器集群、类器官及小鼠模型、高通量筛选等计算和实验体系。课题组成立至今已发表Nature Machine Intelligence, Cell Genomics, Advanced Scienced等论文多篇。课题组现诚聘具有湿实验、AI、生物信息背景的副研究员/博后/科助!详情请见:https://person.zju.edu.cn/xiongxs 或https://xiongxslab.github.io/
高颜值免费 SCI 在线绘图(点击图片直达)
最全植物基因组数据库IMP (点击图片直达)
往期精品(点击图片直达文字对应教程)
机器学习