来源:知乎专栏 智能单元
作者:胡晓伟
【新智元导读】
本文主要介绍DeepMind的星际争霸强化学习算法,由于原论文作者没有开源他们的代码,所以我们尝试重现论文中的结果,并且达到了DeepMind基准80%左右的结果。代码已开源,欢迎大家使用。
Github 链接: https://github.com/XHUJOY/pysc2-agents

关于PySC2环境简介的文章已经有许多了,在这里我们不再详细介绍了。给大家一个传送门:迈向通用人工智能:星际争霸2人工智能研究环境SC2LE完全入门指南(https://zhuanlan.zhihu.com/p/28434323),按照教程相信大家可以对PySC2的API有一个详细的了解。
随着PySC2环境公布的同时,DeepMind在他们的论文中介绍了3种不同的强化学习智能体,分别为Atari-net Agent、FullyConv Agent和FullyConv LSTM Agent。由于这三种智能体具有相似的学习算法和参数,只是使用了不同架构的神经网路来提取特征。所以接下来的内容我们都是以FullyConv Agent为例进行介绍。
在原论文中,作者使用了经典的A3C算法,即异步的actor-critic算法,在这类算法中actor作为策略函数生成要执行的动作,critic作为价值函数负责评估策略函数的好坏。在SC2强化学习算法中,作者使用了神经网路去拟合策略函数和价值函数,具体网络架构为:
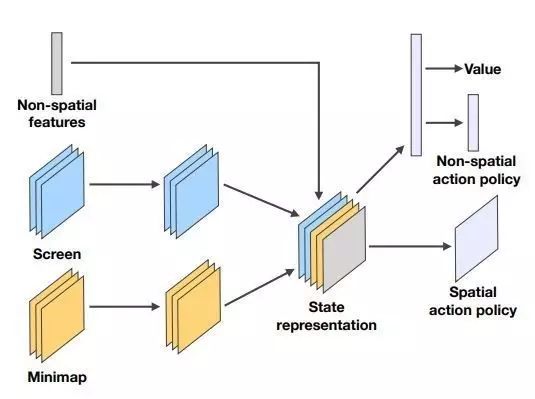
我们按照论文给出的细节简单重现了论文中的算法,并达到了基准的80%左右。接下来将详细介绍实现的过程与使用方法。
算法输入与输出
我们使用了所有的Screen特征图和Minimap特征图,以及可执行动作作为非空间特征作为算法的输入;输出为所有非空间动作和空间动作的概率。笔者发现,由于输出的动作空间巨大,所以这也是星际2的难点所在。
直接运行测试代码
首先,从Github上拷贝源代码并从
这里
下载预训练好的模型,并安装依赖库pysc2和tensorflow,就可以运行测试代码了:
git clone https://github.com/xhujoy/pysc2-agents && cd pysc2-agents
python -m main --map=MoveToBeacon --training=False
你将会得到类似下面的效果图,下面效果图为windows下结果:
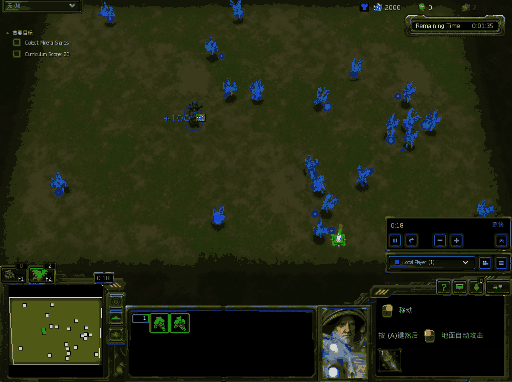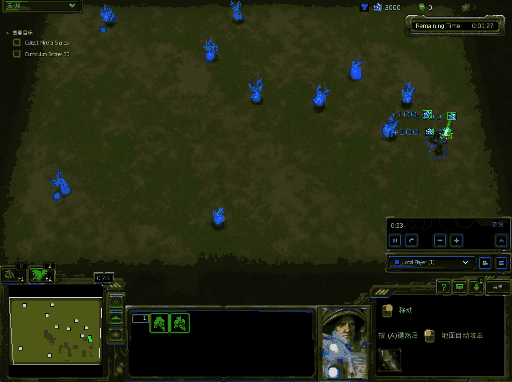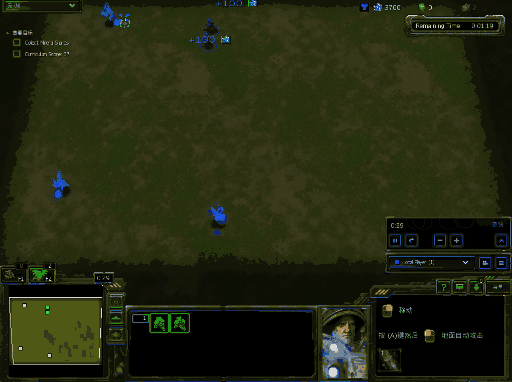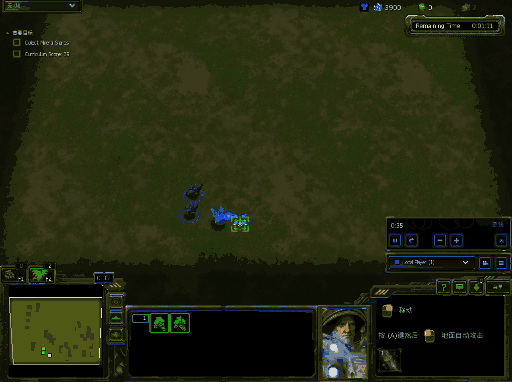
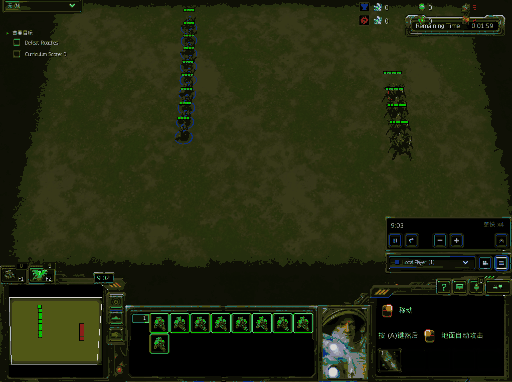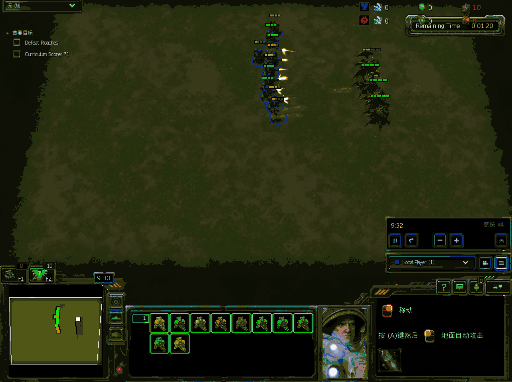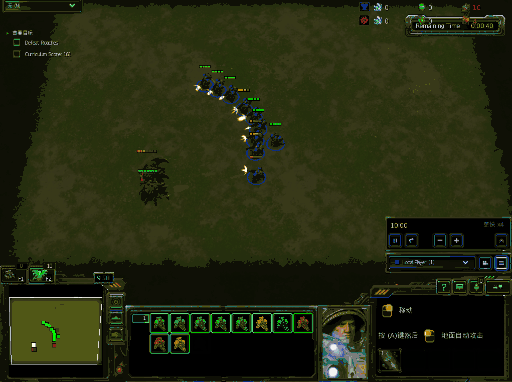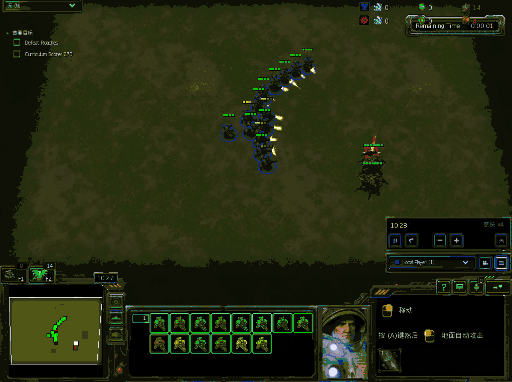
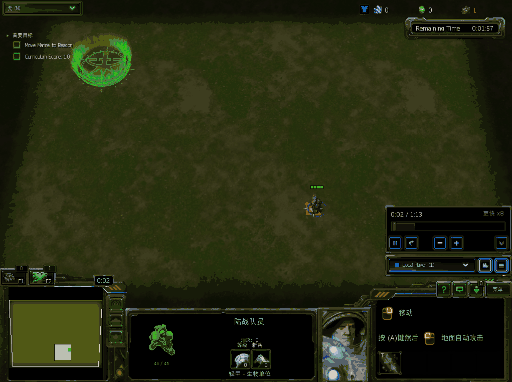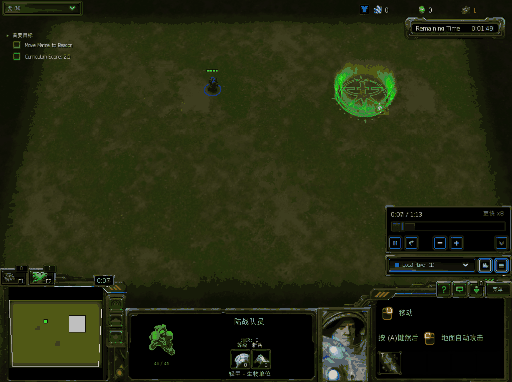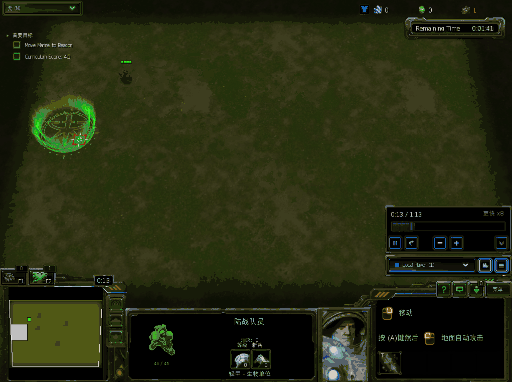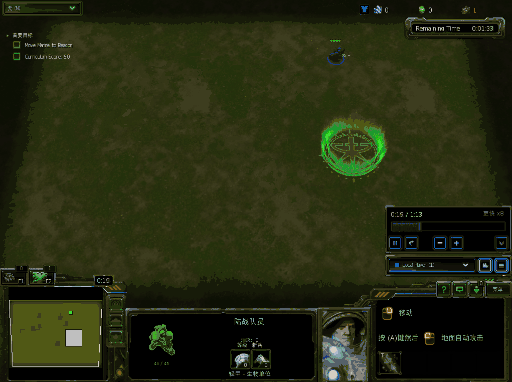
运行训练代码
python -m main --map=MoveToBeacon
训练代码对机器性能要求较高,笔者是在Nvidia K40上进行训练的,并且训练存在较大随机性,在原论文中DeepMind每个模型进行了100次试验(望尘莫及)选择最好的模型。
总结
这篇文章主要向大家介绍了SC2的强化学习算法,并基本重现了论文中的方法。笔者在重现过程发现,星际2的动作空间巨大奖励却很稀疏,总结一句话,完全基于学习的星际2智能体真的好难啊。
代码已经开源,欢迎一起讨论学习。
(本文经授权转载自作者知乎专栏,特此感谢)
【号外】
新智元正在进行新一轮招聘,
飞往智能宇宙的最美飞船,还有N个座位
点击阅读原文可查看职位详情,期待你的加入~






