选自askaswiss
作者:Michael Beyeler
机器之心编译
参与:王宇欣、吴攀 、邵明
随着机器学习越来越流行,也出现了越来越多能很好地处理任务的算法。但是,你不可能预先知道哪个算法对你的问题是最优的。如果你有足够的时间,你可以尝试所有的算法来找出最优的算法。本文介绍了如何依靠已有的方法(模型选择和超参数调节)去指导你更好地去选择算法。本文作者为华盛顿大学 eScience Institute 和 Institute for Neuroengineering 的数据科学博士后 Michael Beyeler。

步骤 0:了解基本知识
在我们深入学习之前,我们先重温基础知识。具体来说,我们应该知道机器学习里面三个主要类别:监督学习,无监督学习和强化学习。
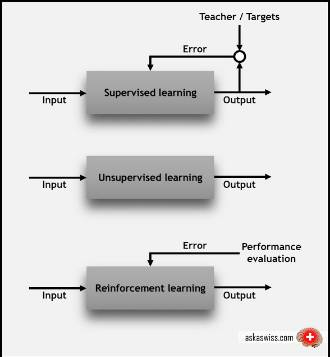
在监督学习(supervised learning)中,每个数据点都会获得标注,如类别标签或与数值相关的标签。一个类别标签的例子:将图片分类为「猫」或「狗」;数值标签的例子如:预测一辆二手车的售价。监督学习的目的是通过学习许多有标签的样本,然后对新的数据做出预测。例如,准确识别新照片上的动物(分类)或者预测二手车的售价(回归)。
在无监督性学习(unsupervised learning)中,数据点没有相关的标签。相反,无监督学习算法的目标是以某种方式组织数据,然后找出数据中存在的内在结构。这包括将数据进行聚类,或者找到更简单的方式处理复杂数据,使复杂数据看起来更简单。
在强化学习(reinforcement learning)中,算法会针对每个数据点来做出决策(下一步该做什么)。这种技术在机器人学中很常用。传感器一次从外界读取一个数据点,算法必须决定机器人下一步该做什么。强化学习也适合用于物联网应用。在这里,学习算法将收到奖励信号,表明所做决定的好坏,为了获得最高的奖励,算法必须修改相应的策略。
步骤 1:对问题进行分类
接下来,我们要对问题进行分类,这包含两个过程:
就是这么简单!
更一般地说,我们可以询问我们自己:我们的算法要实现什么目标,然后以此来找到正确的算法类别。
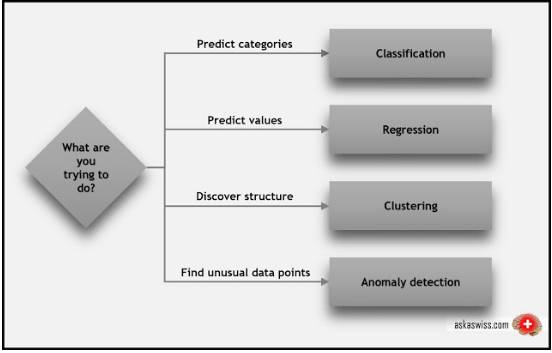
上面的描述包括了几个我们还没有提到的专业术语:
分类(classification):当使用数据来预测类别时,监督学习也被叫做分类。比如将含有「猫」或「狗」的图片识别出来,分类为「猫」或「狗」,这就是二分类问题(two-class or binomial classification)。当存在更多类别时(例如预测下一届诺贝尔物理学家的获得者是谁),这就是所谓的多分类问题(multi-class classification)。
回归(regression):当要预测数值时(比如预测股价),监督学习也被称为回归。
聚类(clustering):聚类或聚类分析(cluster analysis)是无监督学习中最常见的方法之一。聚类是将一组对象以某种方式分组,使得同一组中的数据比不同组的数据有更多的相似性。
异常检测(Anomaly detection):有时我们需要找出数据点中的异常点。例如,在欺诈检测中,任何极不寻常的信用卡消费都是可疑的;欺诈具有大量不同的形式,而训练样本又非常少,使得我们不可能完全了解欺诈活动应该是什么样。异常检测所采取的方法就是了解正常情况下的表现行为(使用非欺诈交易的历史数据),并识别出显著不同的表现行为。
步骤 2:寻找可用的算法
现在我们已经将问题进行了分类,我们就可以使用我们所掌握的工具来识别出适当且实用的算法。
Microsoft Azure 创建了一个方便的算法列表,其展示了哪些算法可用于哪种类别的问题。虽然该表单是针对 Azure 软件定制的,但它具有普遍的适用性(该表单的 PDF 版本可查阅 http://suo.im/3Ss2zW ):
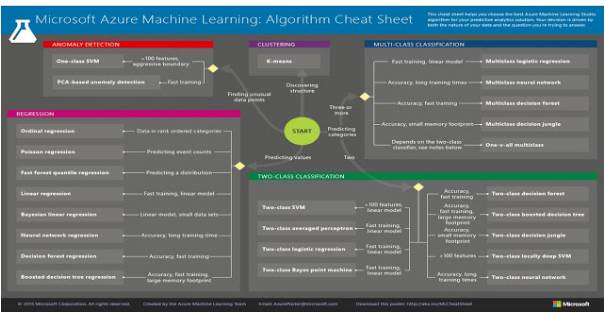
一些值得注意的算法如下:
支持向量机(SVM)可用于找到尽可能宽的分类的边界。当两个分类不能被清楚地分开时,该算法会找到其所能找到的最佳边界。其真正的亮点在于处理特征密集的数据,比如文本或者基因组(特征数量> 100)。在这些情况下,除了仅需要适量的记忆外,支持向量机(SVM)能够比其它大多数算法更快且更少过拟合地进行分类。
人工神经网络是涵盖二分类、多分类和回归问题的脑启发式学习算法。它们有无限的种类,包括感知器和深度学习。它们需要很长时间来训练,但已知其在多种应用领域都实现了当前最佳的表现。
logistic 回归:即便名字中有着「回归」,但 logistic 回归实际上是一种可用于二分类和多分类问题的强大工具。它快速且简单。事实上,它使用「S」形曲线而非直线,所以它自然适合用于数据分组。logistic 回归可以给出线性分类边界,所以如果你要使用它,你一定要确保你能接受线性的近似。
决策树和随机森林:决策森林(decision forests)(回归、二分类、多分类),决策丛林(decision jungles)(二分类和多分类)和提升决策树(boosted decision trees)(回归和二分类)都基于决策树。这是一个基本的机器学习概念。决策树有许多不同的变体,但它们都在做同样的事情—将特征空间(feature space)细分为具有大致相同标签的区域。这些区域可以是一致的类别或者恒定值,具体取决于你进行的是分类还是回归。
线性回归是将一条线(或平面、或超平面)拟合到一个数据集上。这是一种主要的工具,简单且快速,但对于一些问题而言,它可能过于简单。
贝叶斯线性回归有着非常理想的特性:它可以避免过拟合。贝叶斯方法通过事先对答案的可能分布做出一些假设来做到这一点。这种方法的另一个副产品是它们具有非常少的参数。
提升决策树回归(Boosted decision tree regression):如上所述,提升决策树(回归和二分类)均基于决策树,并通过将特征空间细分为具有大致相同标签的区域发挥效用。提升决策树通过限制其可以细分的次数以及每个区域中所允许的最少数据点来避免过拟合。该算法会构造一个树的序列,其中每棵树都会学习弥补之前的树留下来的误差。这能得到一个会使用大量的内存的非常精确的学习器。
层次聚类(Hierarchical Clustering)的目标是构建聚类的层次结构,它有两种形式。聚集聚类(agglomerative clustering)是一种「自下而上」的方法,其中每个观察(observation)在其自己的聚类中开始,随着其在层次中向上移动,成对的聚类会进行融合。分裂聚类(divisive clustering)则是一种「自上而下」的方法,其中所有的观察都从一个聚类开始,并且会随观察向下的层次移动而递归式地分裂。整体而言,这里的融合和分裂是以一种激进的方式确定的。层次聚类的结果通常表示成树状图(dendrogram)的形式。
k-均值聚类(k-means clustering)的目标是将 n 组观测值分为 k 个聚类,其中每个观测值都属于其接近的那个均值的聚类——这些均值被用作这些聚类的原型。这会将数据空间分割成 Voronoi 单元。
k 最近邻(k-nearest neighbors / k-NN)是用于分类和回归的非参数方法。在这两种情况下,输入都是由特征空间中与 k 最接近的训练样本组成的。在 k-NN 分类中,输出是一个类成员。对象通过其 k 最近邻的多数投票来分类,其中对象被分配给 k 最近邻中最常见的类(k 为一正整数,通常较小)。在 k-NN 回归中,输出为对象的属性值。该值为其 k 最近邻值的平均值。
单类支持向量机(One-class SVM):使用了非线性支持向量机的一个巧妙的扩展,单类支持向量机可以描绘一个严格概述整个数据集的边界。远在边界之外的任何新数据点都是非正常的,值得注意。
步骤 3:实现所有适用的算法
对于任何给定的问题,通常有多种候选算法可以完成这项工作。那么我们如何知道选择哪一个呢?通常,这个问题的答案并不简单,所以我们必须反复试验。
原型开发最好分两步完成。在第一步中,我们希望通过最小量的特征工程快速且粗糙地实现一些算法。在这个阶段,我们主要的目标是大概了解哪个算法表现得更好。这个步骤有点像招聘:我们会尽可能地寻找可以缩短我们候选算法列表的理由。
一旦我们将列表减少至几个候选算法,真正的原型开发开始了。理想情况下,我们会建立一个机器学习流程,使用一组经过仔细选择的评估标准来比较每个算法在数据集上的表现。在这个阶段,我们只处理一小部分的算法,所以我们可以把注意力转到真正神奇的地方:特征工程。
步骤 4:特征工程
或许比选择算法更重要的是正确选择表示数据的特征。从上面的列表中选择合适的算法是相对简单直接的,然而特征工程却更像是一门艺术。
主要问题在于我们试图分类的数据在特征空间的描述极少。利如,用像素的灰度值来预测图片通常是不佳的选择;相反,我们需要找到能提高信噪比的数据变换。如果没有这些数据转换,我们的任务可能无法解决。利如,在方向梯度直方图(HOG)出现之前,复杂的视觉任务(像行人检测或面部检测)都是很难做到的。
虽然大多数特征的有效性需要靠实验来评估,但是了解常见的选取数据特征的方法是很有帮助的。这里有几个较好的方法:
主成分分析(PCA):一种线性降维方法,可以找出包含信息量较高的特征主成分,可以解释数据中的大多数方差。
尺度不变特征变换(SIFT):计算机视觉领域中的一种有专利的算法,用以检测和描述图片的局部特征。它有一个开源的替代方法 ORB(Oriented FAST and rotated BRIEF)。
加速稳健特征(SURF):SIFT 的更稳健版本,有专利。
方向梯度直方图(HOG):一种特征描述方法,在计算机视觉中用于计数一张图像中局部部分的梯度方向的 occurrence。
更多算法请参考:https://en.wikipedia.org/wiki/Visual_descriptor
当然,你也可以想出你自己的特征描述方法。如果你有几个候选方法,你可以使用封装好的方法进行智能的特征选择。
使用交叉验证的准则来移除和增加特征!
步骤 5:超参数优化
最后,你可能想优化算法的超参数。例如,主成分分析中的主成分个数,k 近邻算法的参数 k,或者是神经网络中的层数和学习速率。最好的方法是使用交叉验证来选择。
一旦你运用了上述所有方法,你将有很好的机会创造出强大的机器学习系统。但是,你可能也猜到了,成败在于细节,你可能不得不反复实验,最后才能走向成功。
原文地址:http://www.askaswiss.com/2017/02/how-to-choose-right-algorithm-for-your-machine-learning-problem.html
©本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):[email protected]
投稿或寻求报道:[email protected]
广告&商务合作:[email protected]









