文章来源:云栖社区
(
yunqiinsight)
近日,美国权威杂志《麻省理工科技评论》(MIT Technology Review)发布了2017全球十大突破性技术榜单,
强化学习(Reinforcement Learning)
技术位列该榜单第一位,正是阿里近两年布局和重点投入的技术之一。
该技术曾在2016年双十一期间大规模应用于阿里电商搜索和推荐应用场景。通过持续机器学习和模型优化建立决策引擎,对海量用户行为以及百亿级商品特征进行实时分析,帮助每一个用户迅速发现宝贝、为商家带来投缘的买家,提高人和商品的配对效率,实现了用户点击率提升10%-20%。阿里因此成为国际上将该技术率先大规模应用在商业领域的企业之一。
下面是阿里研究员仁基在双11阿里巴巴技术论坛上的分享:
以下内容根据在线分享和演讲幻灯片整理而成。
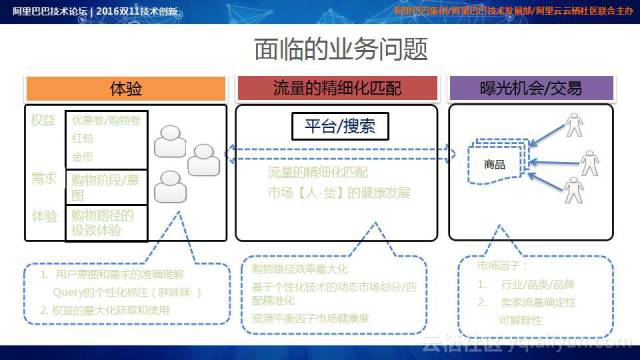
对于阿里巴巴电子商务平台而言,它涉及到了买家、卖家和平台三方的利益,因此必须最大化提升消费者体验;最大化提升卖家和平台的收益。在消费者权益中,涉及到了一些人工智能可以发力的课题,如购物券和红包的发放,根据用户的购物意图合理地控制发放速率和中奖概率,更好地刺激消费和提升购物体验;对于搜索,人工智能主要用于流量的精细化匹配以及在给定需求下实现最佳的人货匹配,以实现购物路径效率最大化。经过几年的努力,阿里研发了一套基于个性化技术的动态市场划分/匹配技术。
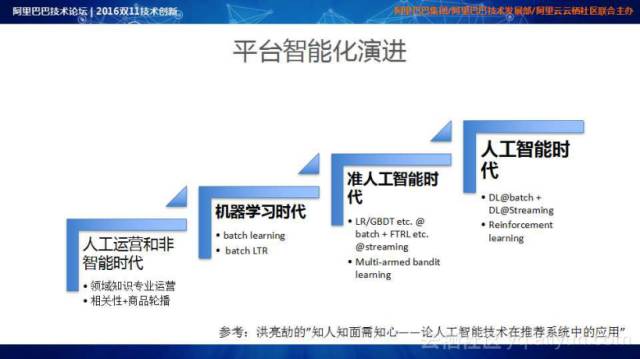
电商搜索和推荐的智能化演进路程可以划分为四个阶段:人工运营和非智能时代、机器学习时代、准人工智能时代、人工智能时代。人工运营和非智能时代,主要靠领域知识人工专业运营,平台的流量投放策略是基于简单的相关性+商品轮播;在机器学习时代,利用积累的大数据分析用户购物意图,最大化消费者在整个链路中可能感兴趣的商品;准人工智能时代,将大数据处理能力从批量处理升级到实时在线处理,有效地消除流量投放时的误区,有效地提高平台流量的探索能力;人工智能时代,平台不仅具有极强的学习能力,也需要具备一定的决策能力,真正地实现流量智能投放。
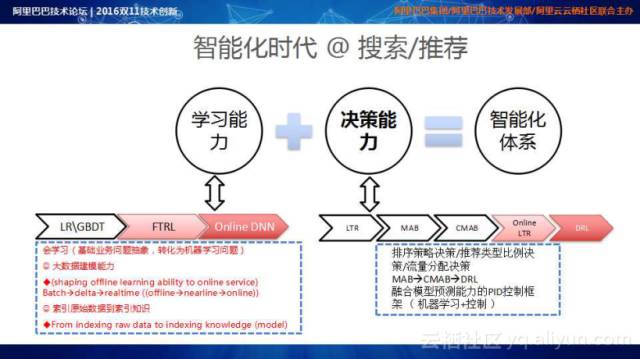
智能化时代,对于搜索和推荐而言,可以提炼为两点:学习能力和决策能力。学习能力意味着搜索体系会学习、推荐平台具有很强的建模能力以及能够索引原始数据到索引知识提升,学习能力更多是捕捉样本特征空间与目标的相关性,最大化历史数据的效率。决策能力经历了从LTR到MAB再到CMAB再到DRL的演变过程,使得平台具备了学习能力和决策能力,形成了智能化体系。
借他山之石以攻玉
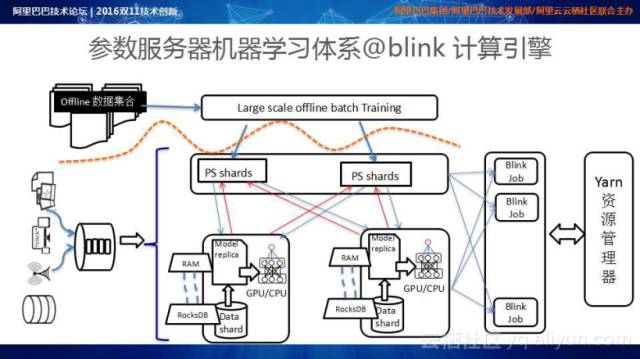
借他山之石以攻玉。在线服务体系中,我们基于参数服务器构建了基于流式引擎的Training体系,该体系消费实时数据,进行Online Training;On Training的起点是基于离线的Batch Training进行Pre-train和Fine Tuning;然后基于实时的流式数据进行Retraining;最终,实现模型捕捉实时数据的效果。
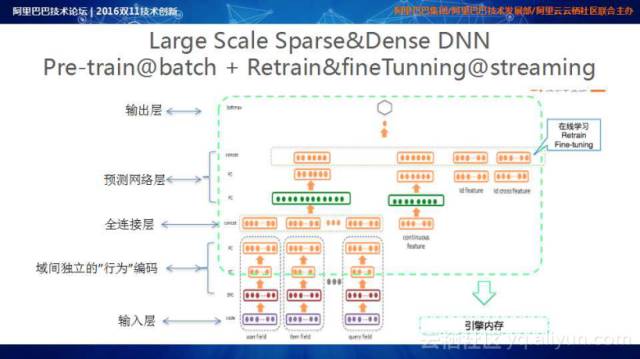
上图是基于Wide & Deep Learning for Recommender Systems的工作建立的Large Scale Sparse&Dense DNN训练体系的架构,该架构中利用Batch Learning进行Pre-Train,再加上Online数据的Retrain&fine Tuning。模型在双11当天完成一天五百万次的模型更新,这些模型会实时输送到在线服务引擎,完成Online的Prediction。

Streaming FTRL stacking@offline GBDT的基本理念是通过离线的训练,在批量数据上建立GBDT的模型;在线的数据通过GBDT的预测,找到相应的叶子节点作为特征的输入,每一个特征的重要性由online training FTRL进行实时调整。
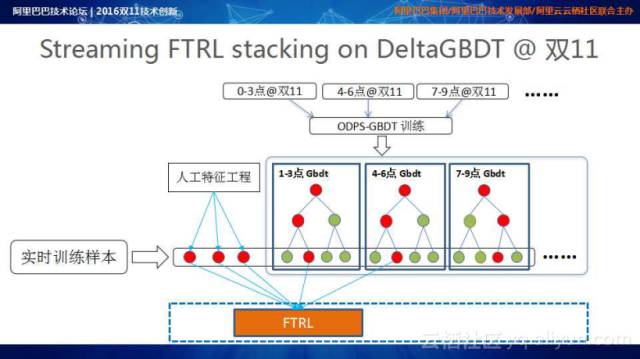
双11当天的成交额是是普通成交日的十到十二倍,点击量将近三十倍。在用户行为密集发生的情况下,有理由相信数据分布在一天内发生了显著的变化,基于这样的考虑,GBDT的Training由原来的日级别升级到小时级别(每小时进行GBDT Training),这些Training的模型部署到Streaming的计算体系中,对于实时引入的训练样本做实时的预测来生成对应的中间节点,这些中间节点和人工的特征一起送入FTRL决出相应特征的重要性。
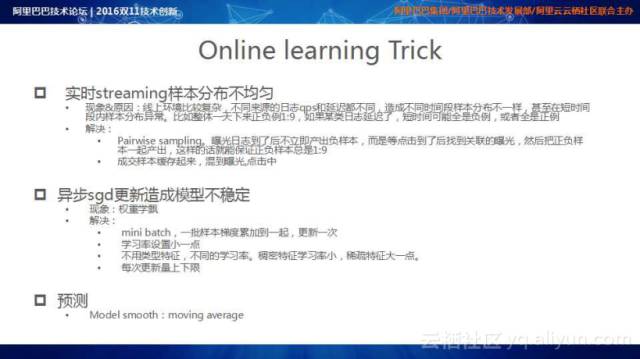
Online Learning和Batch Learning有很大的区别,在Online Learning的研发过程中,总结了一些技巧:
-
实时streaming样本分布不均匀时,由于线上环境比较复杂,不同来源的日志qps和延迟都不同,造成不同时间段样本分布不一样,甚至在短时间段内样本分布异常。比如整体一天下来正负例1:9,如果某类日志延迟了,短时间可能全是负例,或者全是正例,很容易导致特征超出正常值范围。对应的解决方案是提出了一些 Pairwise sampling:曝光日志到了后不立即产出负样本,而是等点击到了后找到关联的曝光,然后把正负样本一起产出,这样的话就能保证正负样本总是1:9;成交样本缓存起来,正样本发放混到曝光点击中,慢慢将Training信号发放到样本空间中。
-
异步sgd更新造成模型不稳定时,由于训练过程采用的是异步SGD计算逻辑,其更新会导致模型不稳定,例如某些权重在更新时会超出预定范围。对应的解决方案是采用mini batch,一批样本梯度累加到一起,更新一次;同时将学习率设置小一点,不同类型特征有不同的学习率,稠密特征学习率小,稀疏特征学习率大一些;此外,对每个特征每次更新量上下限进行限制保护。
-
预测时,在参数服务器中进行Model Pulling,通过采用合理的Model smooth和Model moving average策略来保证模型的稳定性。
智能化体系中的决策环节
电商平台下的大数据是源自于平台的投放策略和商家的行业活动,这些数据的背后存在很强Bias信息。所有的学习手段都是通过日志数据发现样本空间的特征和目标之间的相关性;进而生成模型;之后利用模型预测线上的点击率或转化率,由于预测模型用于未来流量投放中,因此两者之间存在一定的时间滞后(systematic bias),也就观测到的数据和实际失效的数据存在着Gap。在工作逻辑中,如果一个特征和目标存在很强的Correlation,则该特征就应该在线上的预测中起到重要作用。









