游戏行业有一种比较特殊的业务机制需求,叫「跨服」。
这种机制,常见于分区分服类游戏(与之对应的是一些全区全服类游戏,比如COC)。
为了便于非游戏行业的同学理解,小说君抽象一下问题。
现在假设我们部署了两组业务,简化的架构图如下:
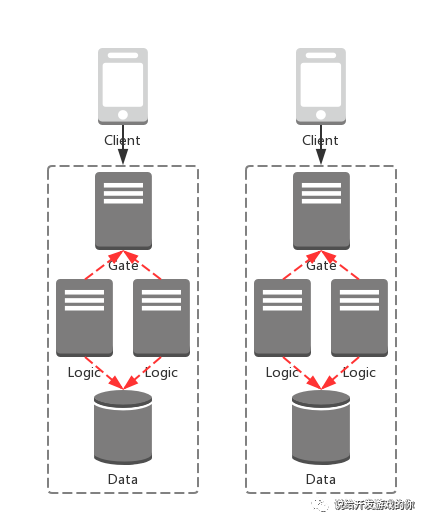
两个特点:
-
不同业务的数据独立,相互隔离。
-
用户可以访问不同的业务,数据无法共享。
那所谓「跨服」,其实就是不同组业务的各种服务可以产生交互。像这样:
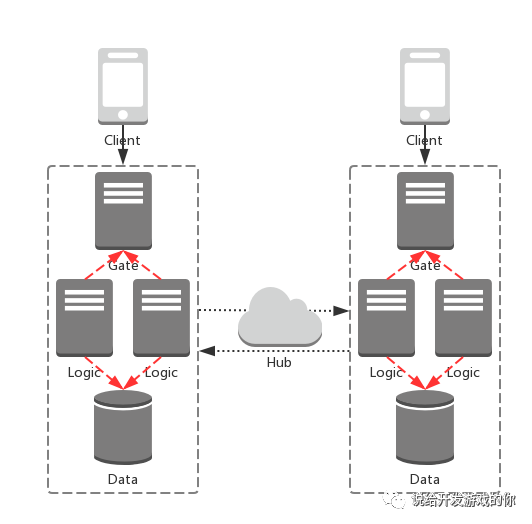
图中的「Hub」,只是一个抽象出来的概念。
实践中,我们当然也可以让不同组业务之间做直连,就可以省去「Hub」这么个抽象。
但是,随着业务复杂度增加,这样的做法可维护性越来越差。
因此,我们通常会在架构中引入「Hub」。
可以自己实现一套,也可以借助成熟的消息中间件,还可以用云服务提供商提供的基础设施。
三种方案孰优孰劣,小说君就不再在本文做探讨。现在假设我们自己实现了一套「Hub」。
设计过程按下不表,我们直接看架构图:
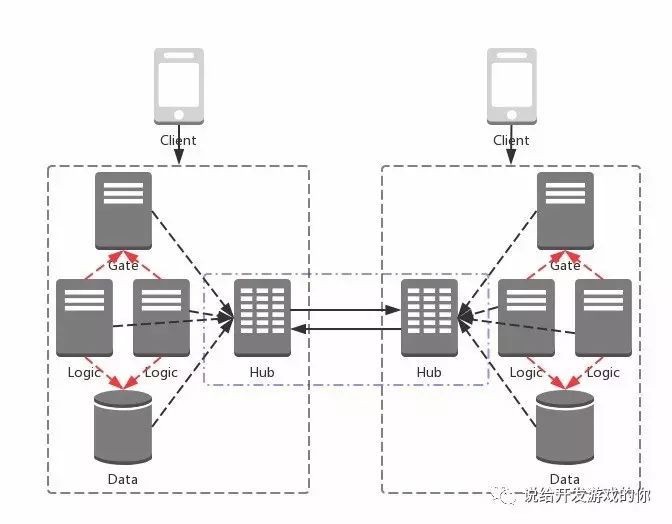
每组业务有一个local message hub,承担着各组业务内部各服务之间的消息转发职责。
同时,不同业务的local message hub互联成网,构成一组stateful service。
背景介绍完毕,我们聚焦下要讨论的问题。
现在有这样一组stateful service。
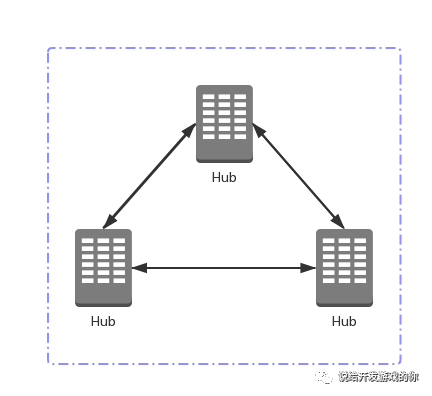
两个特点:
-
服务的每个实例,都会暴露各自的location,比如host/port。
-
服务实例的数量和location会动态变化。(比如下线、迁移等)
接下来,我们就可以引入本篇文章的主题了——服务发现。
何谓服务发现?
在这个例子中,不同组业务的部署时间一定不是同时的,而且先后顺序也不是确定的,因此每组业务的Hub上线时间是动态的,location也是动态的。
当我们部署了一组业务,该组业务的Hub上线时,其他已经上线的Hub如何获取到这个信息,以后新上线的Hub如何追溯到这个信息,所依赖的机制,就是服务发现(Service Discovery)。
接下来看看如何实现。
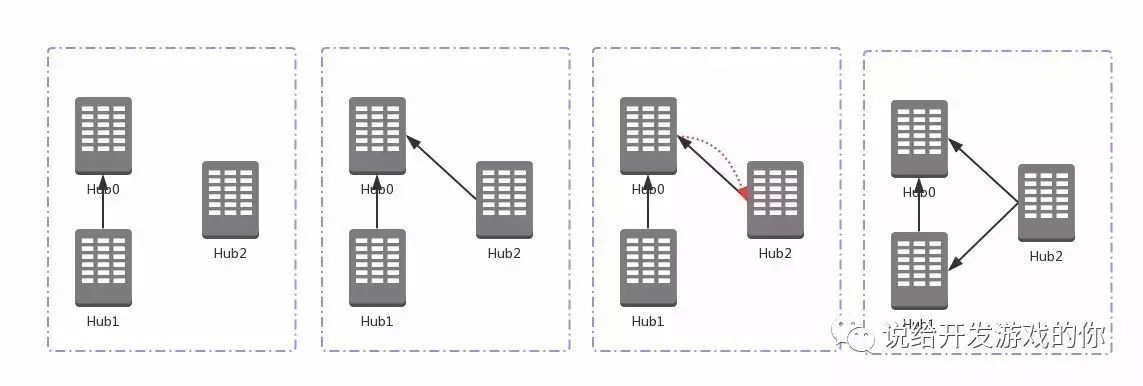
首先我们来看一种最直观的实现方案。
这种方案的核心原则是定义这组stateful service中的静态节点,比如说一定会最先启动的Hub0。然后每组后续启动的业务都配置有Hub0的信息。
如此一来,服务发现的流程如下:
-
最新启动的Hubk,主动连接定点Hub0。
-
连接成功向Hub0登录,拿到当前所有已登录Hub,S。
-
Hubk向S发起连接。
-
Hub0向S推送Hubk的信息。
S中各Hub收到推送后可以向Hubk发起连接(Hub网两两之间有两条物理连接),也可以仅更新本地维护的集群状态(Hub网两两之间有一条物理连接)。
方案实现的比较简单朴素,问题也很多。
最大的问题有两个:
-
Hub0成了集群中的单点。
-
随着Hub网络规模增加,Hub之间的非业务通信量会越来越大(登录、通知、心跳等协议)。
我们先看第一个问题。
单点问题(single point of failure)在我们这个示例系统中有这样几点影响:
解决单点问题有两种思路。
第一个是比较通用的,引入第三方的高可用data store,比如之前小说君的
基于redis构建高可用数据服务一文
中所用的zookeeper,其他的选择还有etcd和Consul。





