
数据挖掘入门与实战 公众号: datadw
作为forecast包与xgboost包的重度依赖者,最近看到整合两家之长的forecastxgb包甚是兴奋,便忍不住翻译forecastxgb包的一些时间序列预测例子与大家交流。
一.安装
目前forecastxgb包还在不断完善中,有兴趣的朋友可以通过以下语句下载试用:
devtools::install_github("ellisp/forecastxgb-r-package/pkg")
二.Forecastxgb包核心函数简介
(一). 核心函数xgbar():
forecastxgb使用xgboost算法(简称xgb),基于自回归(autoregression,简称ar)的思路,通过核心函数xgbar(),以因变量Y的滞后项(Yt-1,…Yt-n)以及自变量X及其滞后项(Xt-1…Xt-n)来预测Y值:
xgbar(y, xreg = NULL,
maxlag = max(8, 2 * frequency(y)),
nrounds = 100,
nrounds_method = c("cv", "v", "manual"),
nfold = ifelse(length(y) > 30,10,5),
lambda = 1, verbose = FALSE,
seas_method = c("dummies","decompose","fourier", "none"),
K = max(1, min(round(f/2 - 1), 10)),
trend_method = c("none", "differencing"),
...)
参数解释:
y: 因变量(数据格式必须是单变量时间序列)。
xreg:如果出现多个自变量预测因变量时,使用该参数;另外自变量与因变量两者的行数必须一致。
maxlag:因变量y和自变量x(若有的话)的最大滞后项数目。
nrounds:指xgboost()的最大迭代次数。
nrounds_method:指决定xgboost最大迭代次数的方法:当nrounds_method
= 'cv',nrounds的值将传送到xgboost()作为交叉检验的次数;当nrounds_method =
'v',xgboost()会把数据拆分成比例为8:2训练集和测试集进行检验;当nrounds_method =
'manual',xgboost()将采用nrounds的值对全部数据进行迭代。
nfold:当nrounds_method = 'cv'时,nfold决定采用多少折检验。
lambda:用于 y的转换系数 (与Box-Cox转换类似,但lambda可以包含负值),会在使用xgboost()前进行转换(之后会使用逆转换回到原始值)。默认lambda = 1 ,此时y值不会被转换; 转换只会用于y值,而不作用于x。
verbose:默认Verbose = FALSE,此时仅显示最终迭代次数,当Verbose = TRUE, 显示每次迭代的误差。
seas_method:处理y值季节性特征的方法,包括"dummies",
"decompose", "fourier"以及"none":当seas_method = "dummies"(默认)或者
"fourier"时,会产生季节性标识的预测变量,:当seas_method =
"decompose",对y进行季节性分解后,再用xgboost()进行预测;当seas_method = "none",
不对y季节性特征做处理。
K:当nrounds_method = "fourier",K值将用于决定傅里叶级数。
trend_method:处理y季节性特征的方法:默认trend_method = "none";当trend_method = "differencing", 采用类似于arma型的差分方法,通过KPSS检验决定差分阶数,以保证剩余序列平稳。
剩余参数设置:当nrounds_method = "cv" 或 "manual"时,xgboost()的参数可以在此使用, xgboost()详细参数参见xgboost包。
(二). 不同Y的季节性特征处理方法出现不同情况:
除了有滞后项外,预测变量集会因参数sea_method的设定而出现不同情况:
当seas_method = ‘none’时,不对Y做季节性特征处理,因此不出现Y的季节性特征变量;当seas_method = ‘decompose’时,会对Y进行季节性分解,并用处理后获得的Y'值作为因变量,因此也不会出现Y的季节性特征变量。
但当seas_method = ‘dummies’ 或者 ‘fourier’时,会通过构造出表达Y的季节性特征的预测变量来参与到xgboost()的计算中,因此在预测变量集中除了滞后项外,还有额外的代表季节性特征的预测变量(如下图的紫色与橙色变量)。
以forecastxgb包自带的单变量时间序列数据集woolyrng为例,在seas_method的不同设定下,参与到xgboost()中的自变量与因变量将以以下方式呈现:

三.例子
(一). 单变量时间序列
以1956年~1995年间澳洲的月度燃气产量数据集作为例:
library(forecastxgb)
model
xgbar()
默认通过行交叉检验方法来决定最佳xgboost算法的迭代次数,以避免过拟合的出现;上面语句最终提示本次计算经过15次迭代后获得最优结果。另外,
最终得到模型会拟合整个数据集。每个预测变量的相对重要性可以通过importance_xgb(),或者更简单的summary() 查看:
summary(model)
Importance of features in the xgboost model:
Feature Gain Cover Frequence
1: lag12 5.097936e-01 0.1480752533 0.078475336
2: lag11 2.796867e-01 0.0731403763 0.042600897
3: lag13 1.043604e-01 0.0355137482 0.031390135
4: lag24 7.807860e-02 0.1320115774 0.069506726
5: lag1 1.579312e-02 0.1885383502 0.181614350
6: lag23 5.616290e-03 0.0471490593 0.042600897
7: lag9 2.510372e-03 0.0459623734 0.040358744
8: lag2 6.759874e-04 0.0436179450 0.053811659
9: lag14 5.874155e-04 0.0311432706 0.026905830
10: lag10 5.467606e-04 0.0530535456 0.053811659
11: lag6 3.820611e-04 0.0152243126 0.033632287
12: lag4 2.188107e-04 0.0098697540 0.035874439
13: lag22 2.162973e-04 0.0103617945 0.017937220
14: lag16 2.042320e-04 0.0098118669 0.013452915
15: lag21 1.962725e-04 0.0149638205 0.026905830
16: lag18 1.810734e-04 0.0243994211 0.029147982
17: lag3 1.709305e-04 0.0132850941 0.035874439
18: lag5 1.439827e-04 0.0231837916 0.033632287
19: lag15 1.313859e-04 0.0143560058 0.031390135
20: lag17 1.239889e-04 0.0109696093 0.017937220
21: season7 1.049934e-04 0.0081041968 0.015695067
22: lag8 9.773024e-05 0.0123299566 0.026905830
23: lag19 7.733822e-05 0.0112879884 0.015695067
24: lag20 5.425515e-05 0.0072648336 0.011210762
25: lag7 3.772907e-05 0.0105354559 0.020179372
26: season4 4.067607e-06 0.0010709117 0.002242152
27: season5 2.863805e-06 0.0022286541 0.006726457
28: season6 2.628821e-06 0.0021707670 0.002242152
29: season9 9.226827e-08 0.0003762663 0.002242152
35 features considered.
476 original observations.
452 effective observations after creating lagged features.
我们可以清楚看到影响燃气产量的最重要预测变量是12个月前的燃气产量(lag12);在仔细看可以得知这个模型中总共用了35个预测变量,另外原本数据集包含476个时点,由于maxlag
= 24,因此在生成y的滞后项后,最终有452个时点参与到xgboost()中计算。
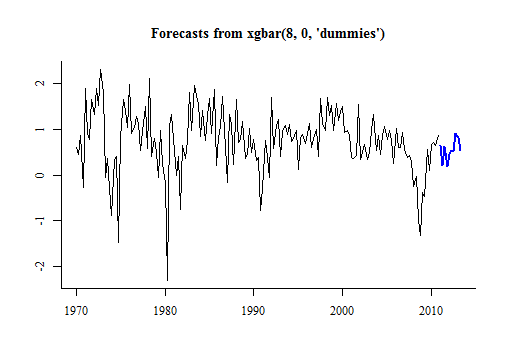
预测是forecastxgb包的重要功能之一,通过forecast() 便可实现预测,最后通过plot()绘制预测图:
fc

需要提醒的是,目前尚未提供预测区间。
(二). 多变量面板数据
与单变量时间序列的操作类似,处理多预测变量的情况只需通过设定xreg = X即可。另外xreg的对象,forecastxgb包的作者建议使用矩阵格式,就算X自变量数据集只有一列也是。
以下的例子数据集usconsumption来自于Athanasopoulos 和 Hyndman撰写的<Forecasting
Principles and Practice>
一书中的配套数据包fpp。该数据集包含‘income’以及‘consumption’
两个指标。本例子使用‘income’作为自变量对‘consumption’进行预测,预测变量集中除了包含‘consumption’的滞后项,同时还包含了’income’及其滞后项:
library(fpp)
consumption
我们可以看到对‘consumption’ 预测重要性最大的指标属于过去两个季度的滞后值,再到当前的‘income’。
使用Y以外的变量来预测都无法避免一个问题:这些预测变量能否提前获得?如果预测变量是月份、日期、星期几、是否有公共假期等等这些可以提前确定的指标就相当好办了;但还有很多指标我们较难提前获知,forecastxgb的作者提供一个小窍门:先预测自变量的未来值,再把自变量的未来值放回原来的预测模型中实现预测Y:
income_future
四.结语
虽然XGBoost大法好,然任何算法都有其适用情况;就个人经历而言,不少经典时间序列预测算法在实际情况中也不时有奇效哦!大家在做时间序列预测工作时,不妨先放下“算法崇拜”,从实际情景与需求出发,多思考多尝试。
另外,按照xgbar()的滞后项+季节性特征处理这个思路,这个模式很容易移植到其他机器学习算法中去做时间序列预测,例如forecast包中的nnetar()就是以这类似的模式用神经网络做时间序列预测的。有兴趣的朋友动手装嵌其他优秀的机器学习算法玩一下!https://zhuanlan.zhihu.com/p/242365
欢迎联系邮件:[email protected].
——Izsak Huang
数据挖掘入门与实战
搜索添加微信公众号:datadw
教你机器学习,教你数据挖掘

长按图片,识别二维码,点关注
公众号: weic2c
据分析入门与实战

长按图片,识别二维码,点关注










