来源:arxiv
作者:谷歌研究院、英伟达、纽约大学研究人员
编译:张易
【新智元导读】
英伟达创建的基于 CNN 的无人驾驶系统 PilotNet,可以根据前方路面的图像输出转向角度。这项由谷歌研究院、英伟达和纽约大学的研究人员联合参与的研究描述了一种方法,用于在 PilotNet 中找到进行转向决策的输入图像中的区域(称为显著物体)。结果显示,PilotNet 确实能够学习识别道路上的相关物体。除了学习车道标记、道路边界以及其他车辆这样明显的特征,PilotNet 还能学习更难以预料和被工程师编程的微妙特征,例如灌木掩映的道路边界和非典型的车辆。
论文下载地址:https://arxiv.org/abs/1704.07911


作为无人驾驶完整软件堆栈的一部分,英伟达已经创建了一个称为 PilotNet 的基于神经网络的系统,该系统根据前方路面的图像输出转向角度。PilotNet 使用道路图像进行训练,该图像与有人驾驶数据采集车产生的转向角度配对。它通过观察人类驾驶来获得必要的领域知识。这消除了人类工程师预测图像中重要内容和预见所有必要的安全驾驶规则的需要。道路测试表明,PilotNet 可以在各种驾驶条件下成功执行车道保持,无论车道标记是否存在。
本研究的目标是解释 PilotNet 的学习内容以及它是如何做出决策的。为此,我们开发了一种方法,来确定道路图像中的哪些元素最能影响PilotNet 的转向决策。结果显示,PilotNet 确实能够学习识别道路上的相关物体。
除了学习车道标记、道路边界以及其他车辆这样明显的特征,PilotNet 还能学习更难以预料和被工程师编程的微妙特征,例如灌木掩映的道路边界和非典型的车辆。
此前有研究描述了一种用于无人驾驶汽车的端到端学习系统,该系统根据前方道路的输入图像训练卷积神经网络(CNN)以输出转向角度。这一系统现在称为PilotNet。训练数据来自数据采集车中前置摄像机的图像,以及人类驾驶员记录的同步转向角度。使用PilotNet的动机是消除手工编码规则的需要,代之以创建一个通过观察进行学习的系统。初步结果令人鼓舞,尽管该系统还需要进行较大改进,才能在不需要人为干预的情况下上路。为了深入了解学习系统如何决定要做什么,并进一步改进系统,且建立其系统将安全驾驶放在首位的信任,我们开发了一种简单的方法来突出显示在确定转向角度方面最显著的图像。我们把这些突出的图像部分称为显著物体。
PilotNet 训练数据包含从汽车前置摄像机的视频采集的单张图像,与相应的转向指令(1 / r)配对,其中r 是车辆的转弯半径。训练数据用额外的“图像/转向命令对”增强,模拟车辆处于不同偏心角和偏心方位的状态。对于增强图像,目标转向命令被适当地调整为将车辆驶回车道中心。
一旦网络被训练完成,它可以用于为给定图像提供转向命令。
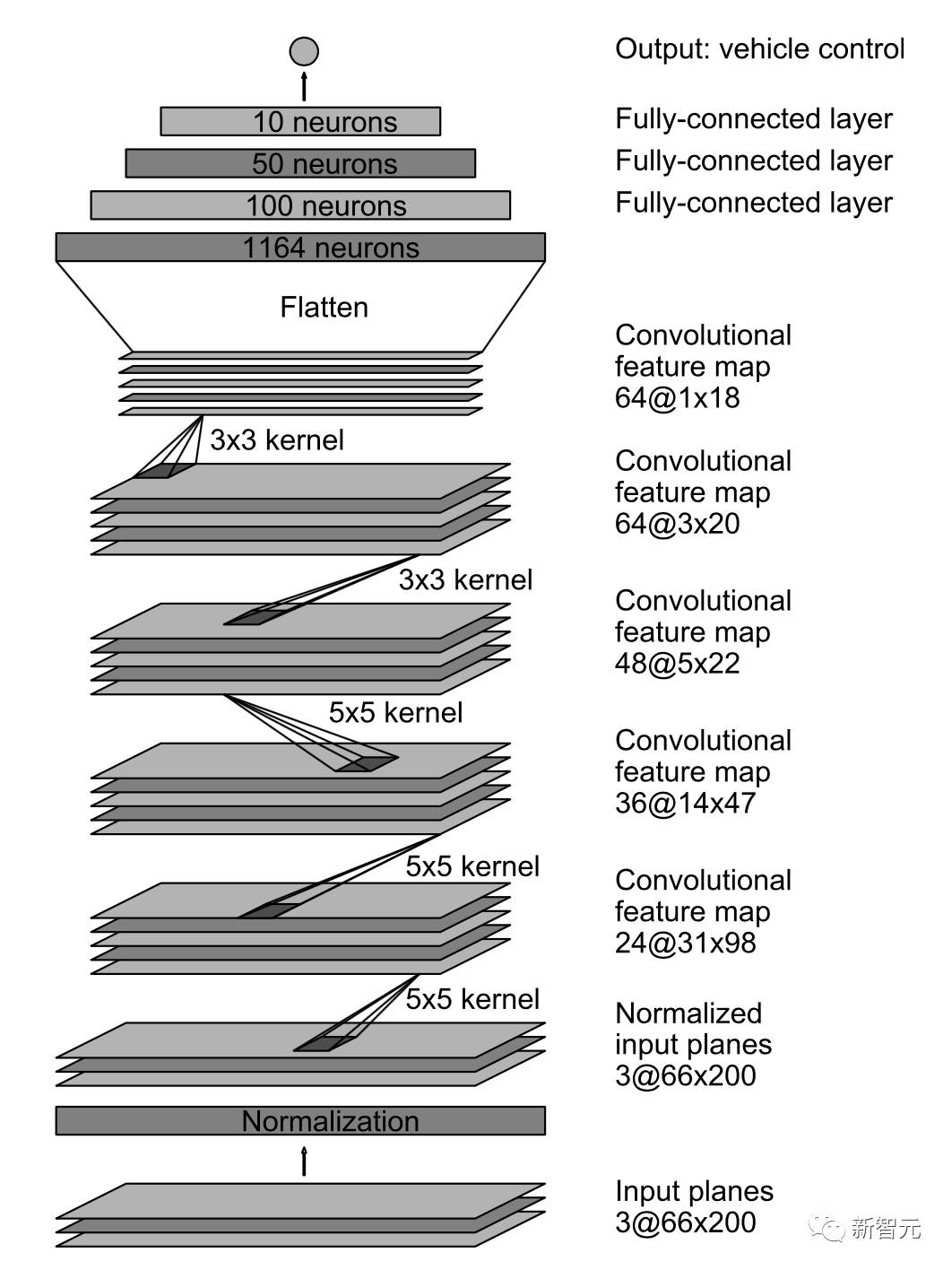
图1 PilotNet 架构
PilotNet 架构如图1所示。该网络由9层组成,包括归一化层,5个卷积层和3个完全连接的层。输入图像被分割成YUV平面并传递到网络。网络的第一层执行图像归一化。归一化器是硬编码的,在学习过程中没有调整。
卷积层被设计用来执行特征提取,并通过一系列改变层配置的实验来选择。
五个卷积层之后是三个完全连接层,输出反转弯半径的控制值。完全连接的层被设计为用作转向的控制器,但是须注意,通过端对端的系统训练,网络的哪些部分作为特征提取器,哪些部分用作控制器,之间没有硬性的边界了。
识别显著物体的中心思想是找到图像中的某一部分,其对应于上述特征图具有最多 activation 的位置。
使用下面的算法,较高级别特征图的 activation 成为了较低级别 activation 的掩码:
1.
在每一层中,特征图的
activation
被平均化了。
2.
最平均的特征图按照下层的特征图尺寸进行放大。使用去卷积完成扩展。
用来去卷积的参数(过滤大小和步幅)与用于生成特征图的卷积层相同。
去卷积的权重设置为
1.0
,偏差设为
0.0
。
3.
然后将来自较高级别的高尺度平均特征图与来自下层的平均特征图相乘(两者现在都是相同的大小)。
结果是一个中间掩码。
4.
中间掩码以与步骤
2
所述相同的方式放大到下层特征图的大小。
5.
高尺度的中间特征图再次乘以下层的平均图(现在两者都是相同大小)。
因此获得了新的中间掩码。
6.
重复上述步骤
4
和
5
,直到达到输入。将输入图像大小的最后一个掩码归一化到从
0.0
到
1.0
的范围,并成为最终的可视化掩码。
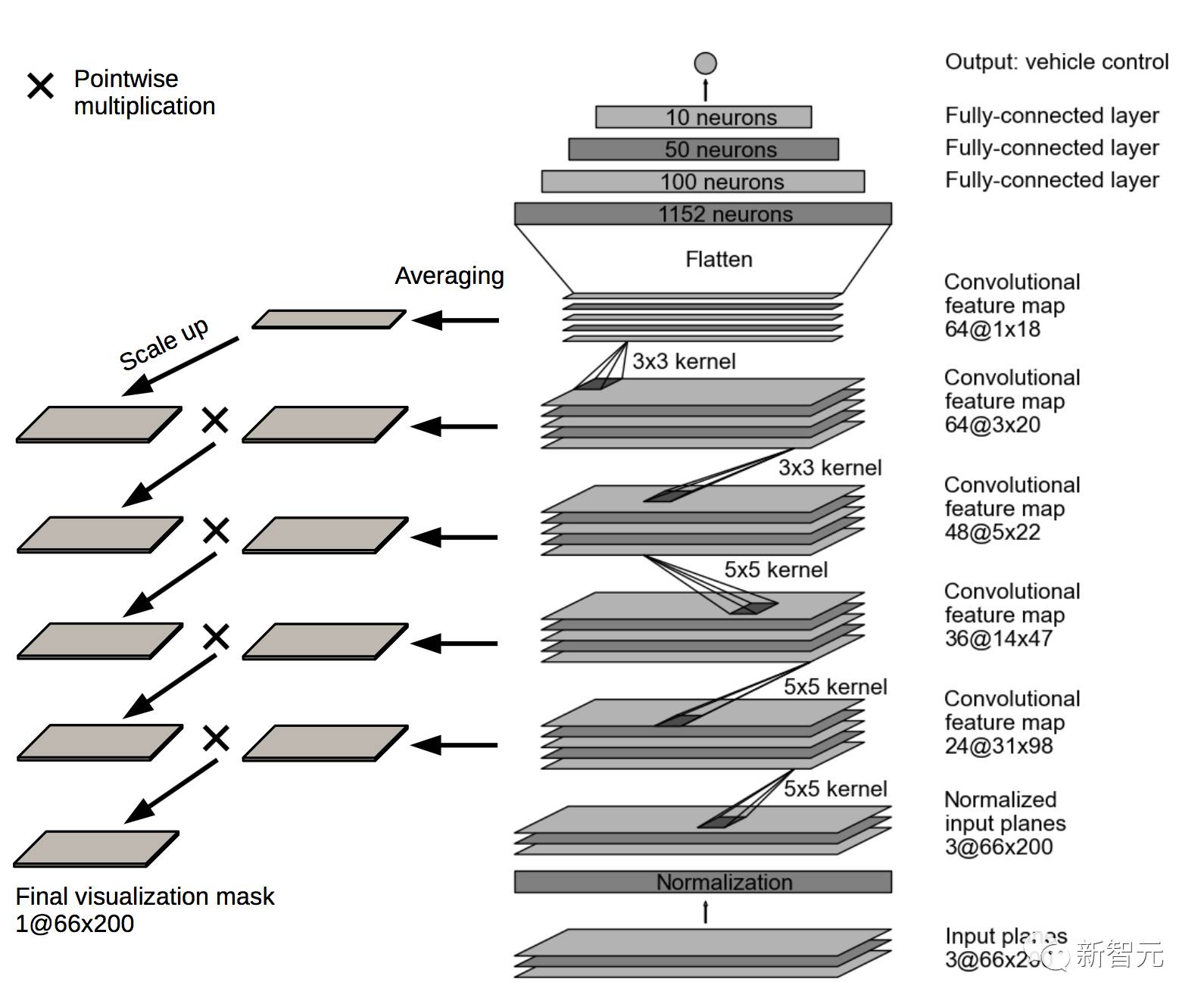
图3 识别显著物体的可视化方法的算法示意图
该可视化掩码显示了输入图像的哪些区域对网络的输出贡献最大。这些区域识别显著物体。算法示意图如图2所示。

图3 (左)网络各层的平均特征图;(右)网络各层的中间可视化掩码。
创建可视化掩码的过程如图 3 所示。可视化掩码覆盖在输入图像上,以突出显示原始摄像头图像中的像素以说明显著物体。

图4 用于各种图像输入的显著物体的示例
各种输入图像的结果如图 4 所示。注意在最上面的图像中,汽车底盘以及指示车道的线(虚线和实线)被突出显示,而人行横道上几乎水平的线被忽略。在中间的图像中,道路上没有车道,但是突出显示了道路边缘的停放汽车。在底部的图像中,道路边缘的草被突出显示。没有任何手工编码,这些检测显示了 PilotNet 如何模拟人类驾驶员使用这些视觉线索的方式。

图5 测试车内部
图5 显示了我们的测试车内的一个视图。在图像的顶部,我们看到的是通过挡风玻璃的实际视图。 PilotNet 监视器位于图像底部正中,显示诊断信息。

图6 PilotNet 监视器画面
图6是 PilotNet 监视器画面的放大图。上面的图像由前置摄像头捕获。绿色矩形圈出了馈送到神经网络的摄像头图像的部分。下面图像显示了显著区域。请注意,PilotNet 将道路右侧部分遮挡的建筑车辆识别为显著物体。据我们所知,这样的车辆,特别我们这里看到的这辆,绝非PilotNet 训练数据的一部分。
虽然我们的方法发现的显著物体显然是影响转向的物体,但我们进行了一系列实验来验证这些物体实际上确实控制了转向。为了进行测试,我们将提供给 PilotNet 的输入图像分为两类。
第一类旨在包括对PilotNet 的转向角输出有显著影响的所有区域。这些区域包括对应于可视化掩码高于阈值的位置的所有像素。然后将这些区域扩大 30 个像素,以抵消相对于输入图像的较高级别特征图层的增加的跨度。确切的扩张量由实践确定。第二类是包括原始图像中的所有像素减去第一类中的像素。如果我们的方法找到的物体确实主导了转向角的输出控制,我们会期待:如果我们创建一个图像,其中我们只统一转换第一类中的像素,同时保持第二类中像素的位置,并将该新图像用作 PilotNet 的输入,我们预计转向角输出会发生显著变化。但是,如果我们在第二类中转换像素,同时保持第一类中的像素固定,并将该图像提供给 PilotNet,那么我们预计 PilotNet 输出的变化将是最小的。

图7 实验图像显示了转向角度图像位移的效果
图 7 显示了上述过程。顶部图像显示了我们的数据采集车捕获的场景。下一个图像显示使用我们的方法识别的显著突出区域。下一个图像显示突出区域扩大。底部图像显示了测试图像,其中扩大的显著物体被移动了。
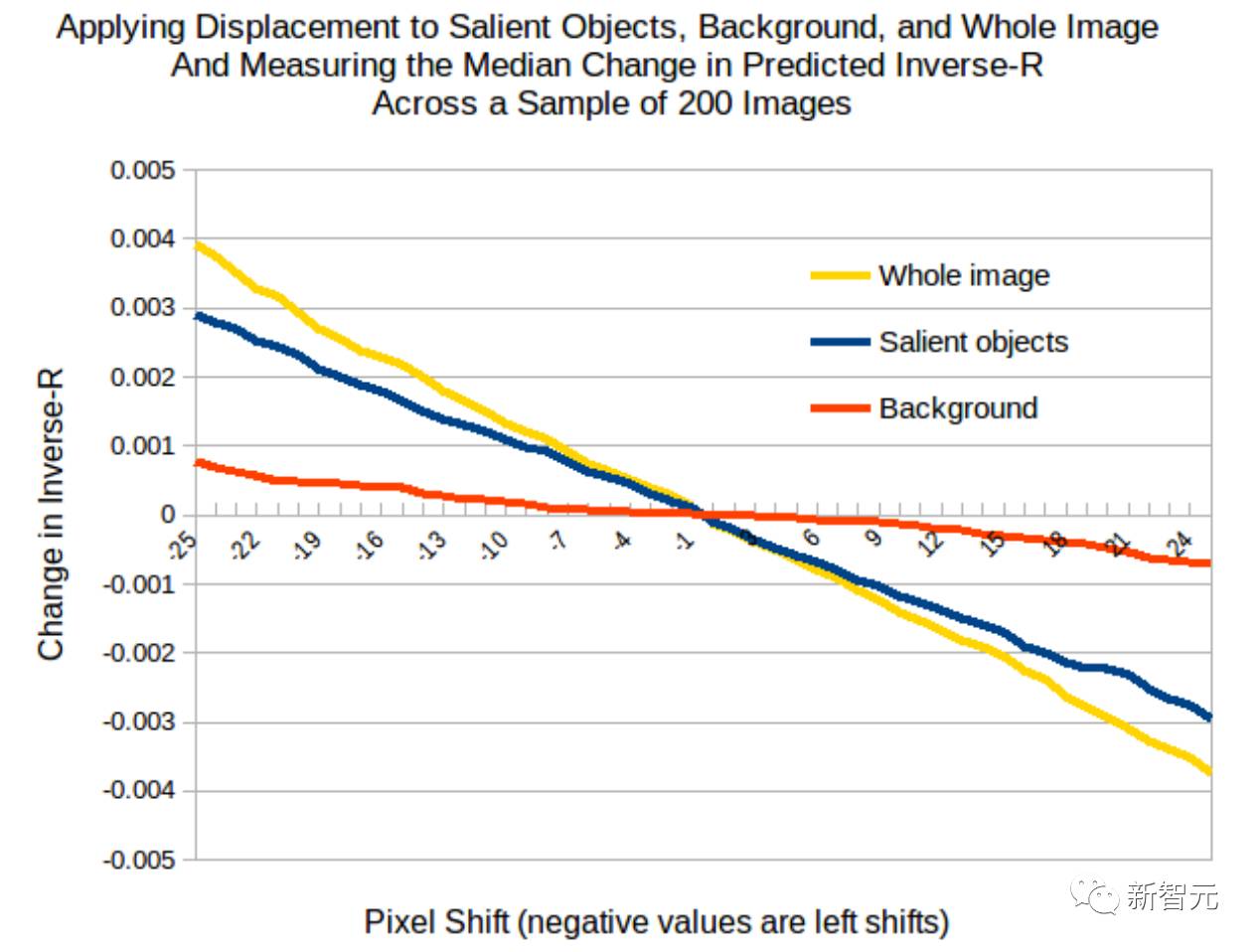
图8 PilotNet 转向输出作为输入图像像素偏移函数的曲线
上述预测确实是由我们的实验产生的。图 8 显示了 PilotNet 转向输出作为输入图像中像素偏移函数的曲线。蓝线显示了当我们移动包括显著物体(第一类)的像素时的结果。红线显示了当我们移动不包括在显著物体中的像素时的结果。黄线显示了当我们移动输入图像中所有像素时的结果。
转移显著物体会导致转向角度的线性变化,这与转换整个图像时几乎一样大。仅转移背景像素对转向角度的影响要小得多。因此,我们确信我们的方法确实找到了图像中用于确定转向的最重要的区域。
我们描述了一种方法,用于在 PilotNet 中找到进行转向决策的输入图像中的区域,即显著物体。我们进一步提供证据表明,该方法识别出的显著物体是正确的。这些结果大大有助于我们对 PilotNet 学习过程的认识。
检查显著物体表明,PilotNet 可以学习人类认为“有意义”的特征,同时忽略摄像机图像中与驾驶无关的结构。此功能来源于无须手工编制规则的数据。事实上,PilotNet 学习识别了人类工程师难以预料和编程的微妙特征,例如公路边缘掩映的灌木和非典型车辆。
原文地址:https://arxiv.org/abs/1704.07911






