随着 DeepMind 公司的崛起,深度学习和
强化学习
已经成为了人工智能领域的热门研究方向。除了众所周知的 AlphaGo 之外,DeepMind 已经与著名的游戏公司 Blizzard 合作,准备挑战热门的即时战略游戏 StarCraft II。之前 DeepMind 已经成功地使用 Deep Learning 和 Reinforcement Learning 来搭建能够自行玩游戏的人工智能,并且成功挑战了 Atari 的一些游戏。虽然目前还没有成功地使用 AI 来战胜 StarCraft II 的顶尖职业玩家,但是 AI 却能够带给大家无穷的想象力和期待。
与机器学习相比,
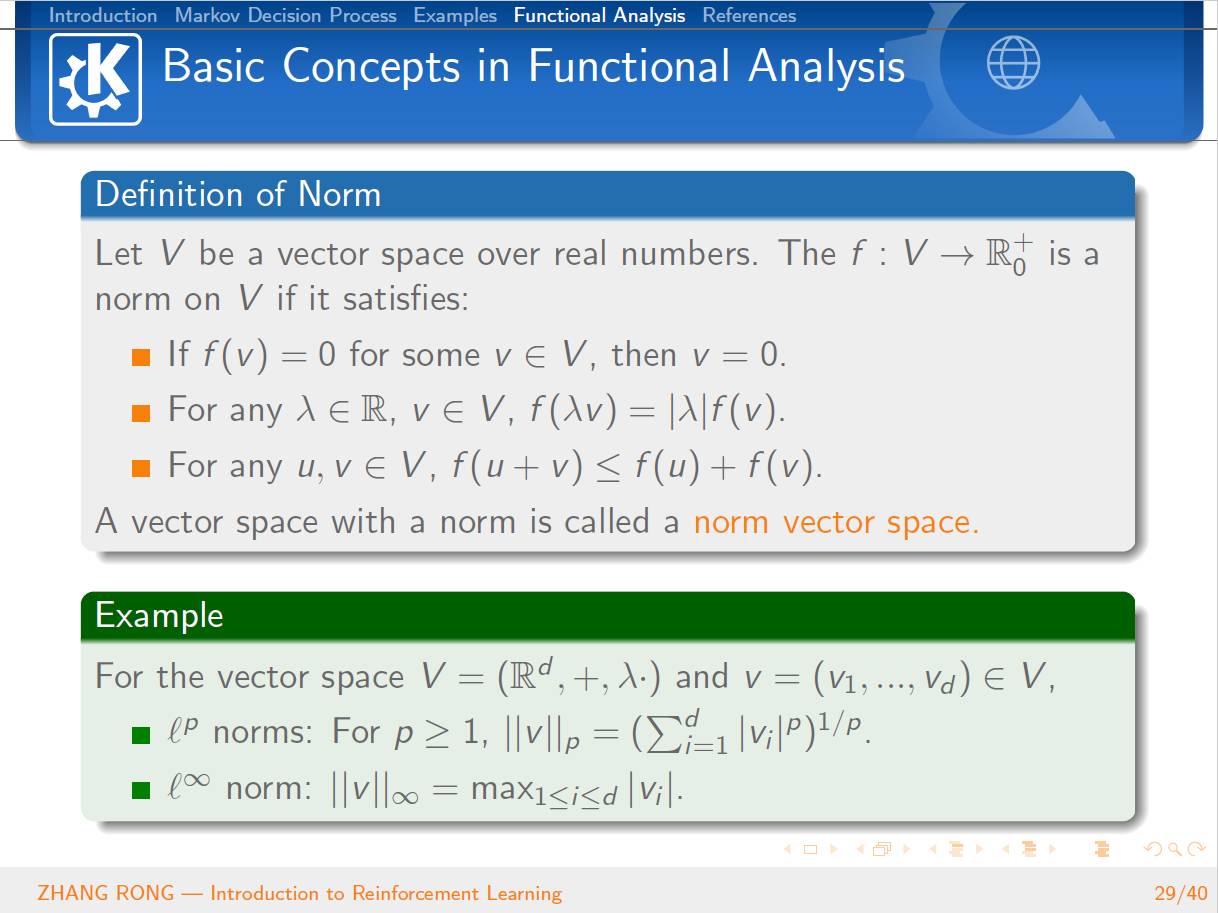
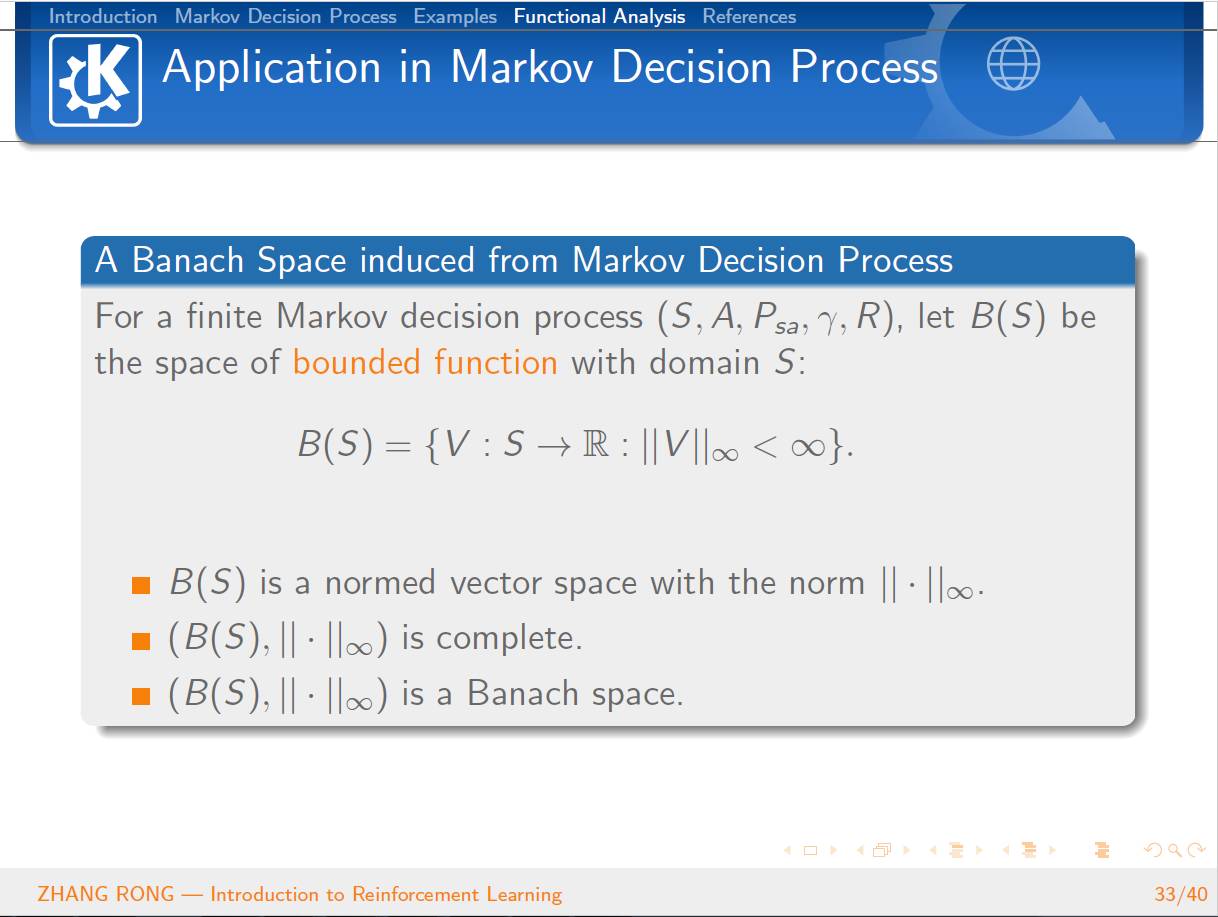
泛函分析
已经是数学史上一门传统而经典的学科。泛函分析是分析学的一个分支,其研究的主要对象就是由函数构成的函数空间。它是从变分问题,积分问题,理论物理的研究过程中,逐步发展起来的。那么泛函分析是怎么和机器学习中的强化学习结合到一起的呢?本篇文章将会从强化学习的定义出发,一步一步地给读者介绍强化学习的简单概念和基本性质,并且会介绍经典的 Q-Learning 算法。文章的最后一节会介绍泛函分析的一些基本概念,并且使用泛函分析的经典定理
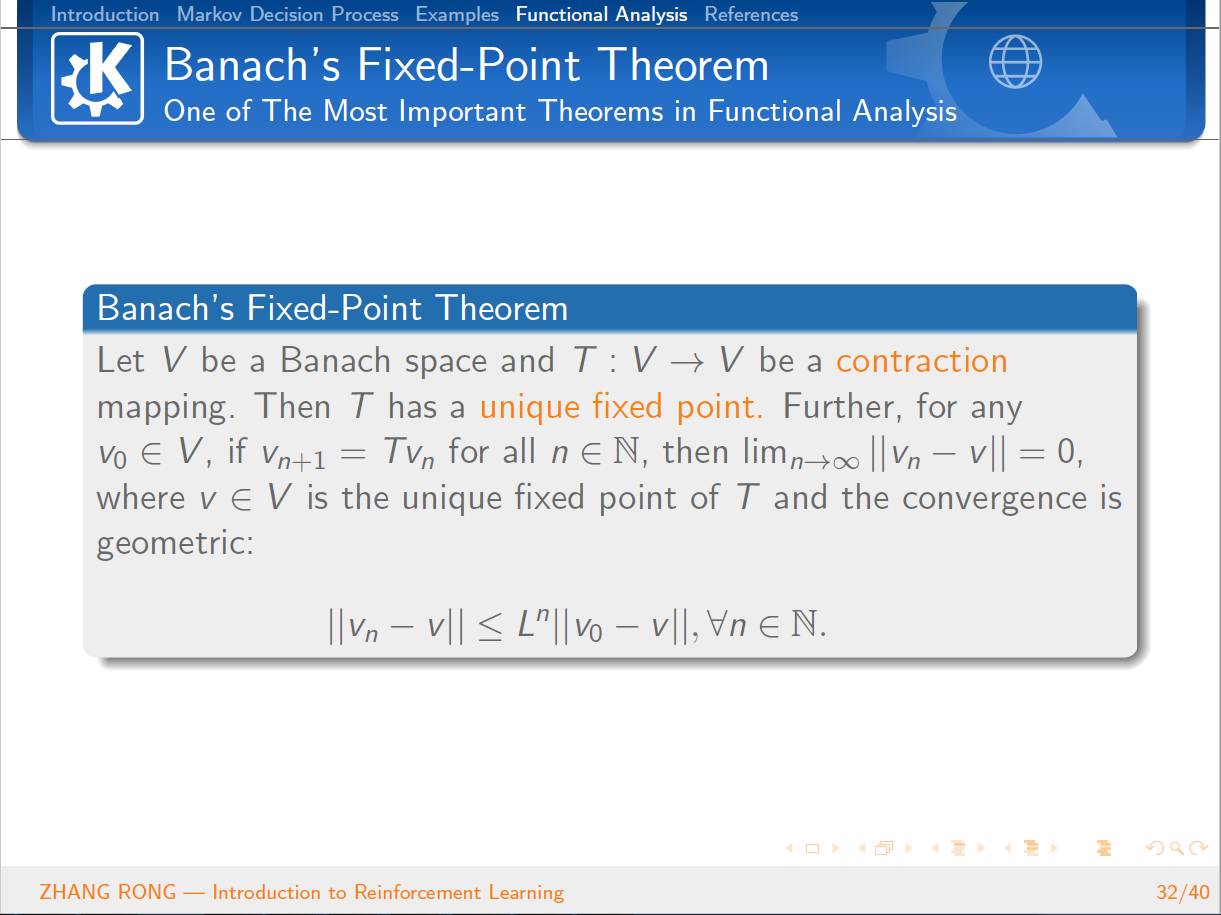
Banach Fixed Point Theorem
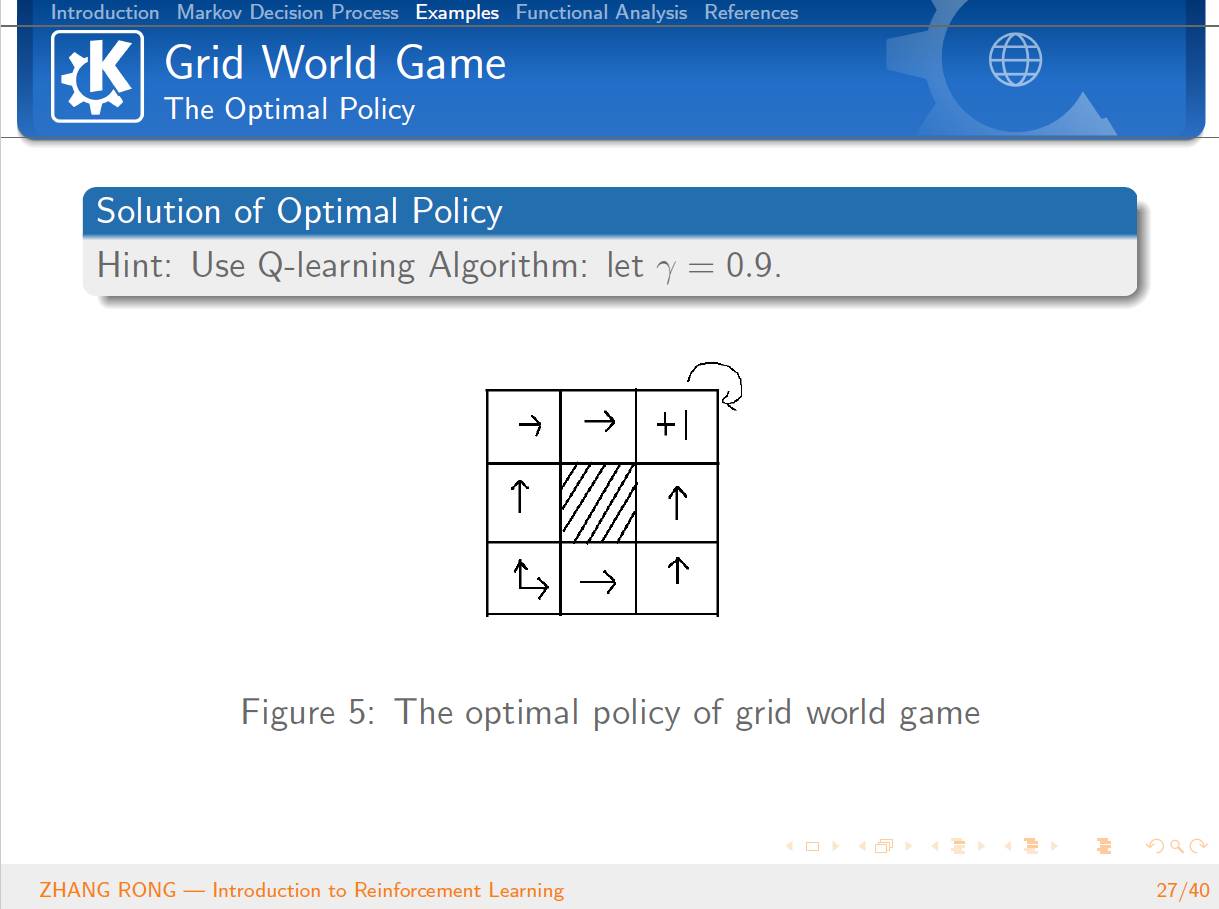
来证明强化学习中 Value Iteration 等算法的收敛性。
























欢迎大家关注公众账号数学人生
(长按图片,识别二维码即可添加关注)






