作者简介:Jesse Newland是GitHub的首席网站可靠性工程师。
在过去一年,GitHub逐渐完善了一套运行Ruby on Rails应用软件的基础设施,该应用软件负责github.com和api.github.com。最近我们进入到了一个重大阶段:所有Web和API请求由部署在我们裸机云上的Kubernetes集群中运行的容器来处理。

将关键的应用软件迁移到Kubernetes是个有趣的挑战,我们很高兴分享这方面的心得。
为什么改变?
迈出这一步前,我们的主Ruby on Rails应用软件(我们称之为github/github)配置方式酷似八年前:Unicorn进程由一个名为God的Ruby进程管理器来管理,该进程管理器在Puppet管理的服务器上运行。与之相仿,我们的聊天运维(chatops)部署方式酷似首次推出时的做法:Capistrano建立通向每台前端服务器的SSH连接,然后原地更新代码,重新启动应用软件进程。如果峰值请求负载超过可用的前端CPU容量,GitHub网站可靠性工程师(SRE)就会配置额外容量,添加到活动前端服务器集群。
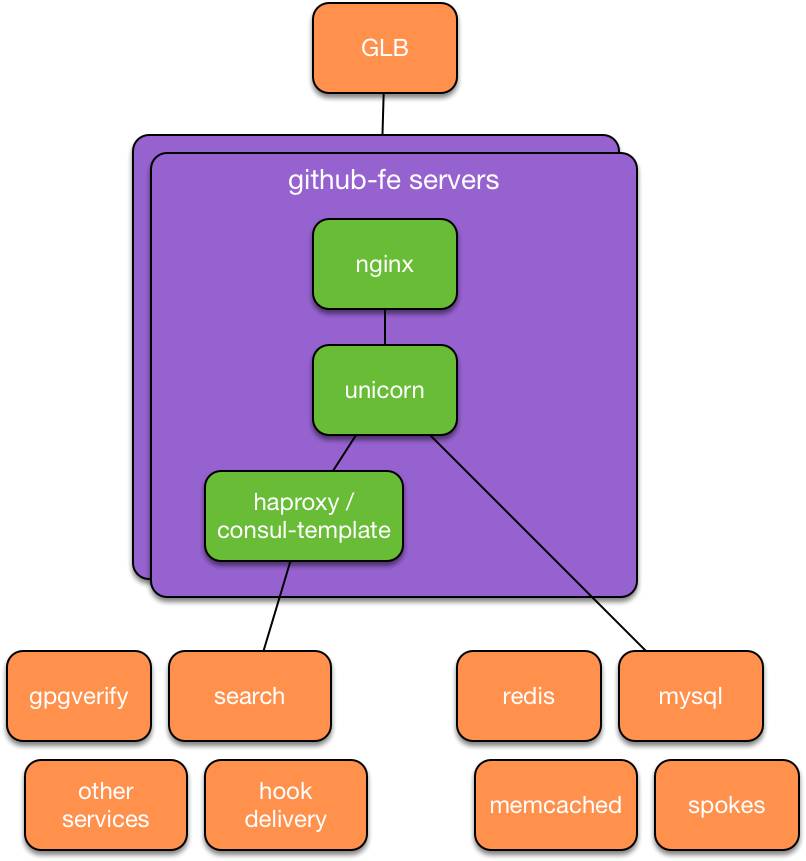
之前的unicorn服务设计
虽然这些年来生产环境的基础方法没多大变化,但GitHub本身发生了很大的变化:新的功能、更庞大的软件社区、更多的GitHub员工以及每秒多得多的请求。随着我们规模不断扩大,这种方法暴露出新的问题。许多团队想把自己负责的功能从这个大型应用软件提取到可以独立运行和部署的更小服务。随着我们运行的服务数量增加,SRE团队开始为另外众多的应用软件支持类似配置,增加了我们花在服务器维护、配置以及与全面改善GitHub体验没有直接关系的其他工作上的时间。新服务要花数天、数周乃至数月才能部署,长短取决于新服务的复杂性和SRE团队有没有空。久而久之,这种方法显然无法为我们的工程师提供继续构建世界级服务所需要的灵活性。我们的工程师需要一种自助式平台,可用来试验、部署和扩展新服务。我们还需要这同一个平台来满足那个核心的Ruby on Rails应用软件的要求,以便工程师及/或机器人可以通过在短短数秒内,而不是在数小时、数天或更长时间内分配额外的计算资源,以应对需求变化。
为了满足这些要求,SRE团队、平台团队和开发者体验团队开始搞一个联合项目,这让我们从初期评估容器编排平台的阶段进入到现阶段:每天数十次将支持github.com和api.github.com运行的代码部署到Kubernetes集群。本文旨在大体上介绍这个迁移过程中涉及的工作。
为何是Kubernetes?
我们最初评估了现有的“平台即服务”工具市场,随后较认真地分析了Kubernetes,源自谷歌的这个项目当时自称是开源系统,可用于使容器化应用软件的部署、扩展和管理实现自动化。Kubernetes的几个特性与我们评估的其他平台相比很突出:充满活力的开源社区在支持该项目,良好的首次体验(让我们可以在初期试验的头几个小时内部署一个小型集群和应用软件),以及丰富的相关信息可参阅。
这些试验的范围迅速扩大开来:搞起了一个小项目,构建Kubernetes集群和部署工具,以支持随后的黑客周活动,旨在对这个平台有一番实际的体验。不光我们在这个项目后觉得很好,用过它的工程师的反馈也很好,于是我们扩大了试验范围,开始计划更庞大的扩建。
为何从github/github开始入手?
在这个阶段的最早阶段,我们有意决定迁移一种关键的工作负载:github/github。许多因素促成了这个决定,有几个尤为突出:
-
我们知道,深入了解GitHub中运行的这个应用软件在迁移过程中很有用。
-
我们需要自助式容量扩展工具来应对继续发展。
-
我们想要确保当初养成的习惯和开发的模式同时适合庞大的应用软件和较小的服务。
-
我们想要更好地让应用软件不受开发、试运行、生产、企业及其他环境之间的区别的影响。
-
我们知道,迁移一种关键的、备受瞩目的工作负载将鼓励Kubernetes在GitHub得到进一步的采用。
考虑到我们选择迁移的工作负载具有的重要性,我们需要在处理任何生产级流量之前先在运维方面树立很强的自信心。
借助审核实验室,快速迭代、树立信心
作为这个迁移的一部分,我们使用Kubernetes的基本单元,比如Pods、Deployments和Services,设计、研制和验证了一项服务,取代目前由前端服务器提供的原有服务。这种新设计的部分验证可通过在容器中、而不是在配置类似前端服务器的服务器上运行github/github的现有测试套件来进行,但是我们还需要观察作为一套更繁多的Kubernetes资源的一部分,这个容器运行起来如何。很快发现,在验证阶段,一种支持试探性测试Kubernetes和我们想要运行的服务这对组合的环境显然必不可少。
差不多同时,我们发现试探性测试github/github合并请求的现有模式已开始露出越来越麻烦的征兆。随着部署速度加快,从事这个项目的工程师数量增加,验证github/github合并请求的过程中用到的几个额外部署环境的使用率随之提高。少量功能齐全的部署环境在峰值工作时间通常满额预定,这减慢了部署合并请求的过程。工程师常常请求能够在“分支实验室”(branch lab)上测试更多的不同生产级子系统。虽然分支实验室允许许多工程师并行部署,但只为每个工程师启动单单一个Unicorn进程,这意味着它只有在测试API和UI变更时才有用。这些要求大量重叠,于是我们合并项目,开始为github/github构建一种新的由Kubernetes驱动的部署环境,名为“审核实验室”(review lab)。
在构建审核实验室的过程中,我们交付了几个子项目,每个子项目可能在各自的博文中有所介绍。我们还交付了:
-
一个在使用Terraform和kops这对组合来管理的AWS VPC中运行的Kubernetes集群。
-
一套测试临时Kubernetes集群的Bash集成测试,大量运用于项目的开始阶段,获得Kubernetes方面的信心。
-
面向github/github的Dockerfile。
-
改进了我们的内部持续集成(CI)平台,以支持构建集群,并发布到容器注册中心。
-
用YAML表示50多个Kubernetes资源,代码签入到github/github。
-
改进了我们的内部部署应用软件,以支持将Kubernetes资源从注册中心部署到Kubernetes命名空间,以及利用内部的secret存储库创建Kubernetes secret。
-
一项结合haproxy和consul-template的服务,以便将流量从Unicorn pod路由至发布服务信息的现有服务。
-
一项读取Kubernetes事件,并将异常事件发送到内部错误跟踪系统的服务。
-
一项名为kube-me的与chatops-rpc兼容的服务,它通过聊天,向用户提供了一套数量有限的kubectl命令。
最终结果是一种基于聊天的接口,可用于为任何合并请求创建GitHub的孤立部署。一旦合并请求通过了所有必需的CI作业,用户可以将合并请求部署到审核实验室,就像这样:
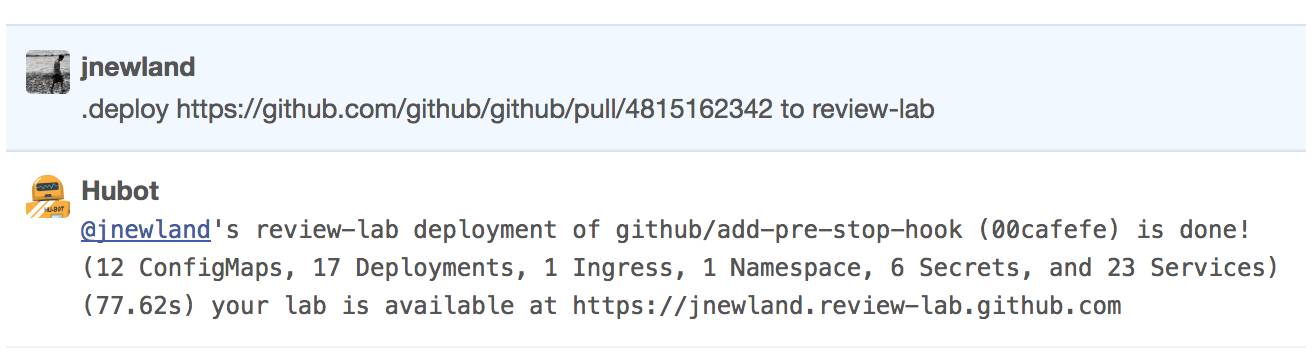
与之前的分支实验室一样,实验室在上一次部署后一天清理。由于每个实验室在自己的Kubernetes命名空间创建,清理起来就像删除命名空间这么简单,我们的部署系统必要时可自动执行这项任务。
审核实验室有一个成功的项目,取得了好多成果。这个环境向工程师敞开之前,它为我们的Kubernetes集群设计以及设计和配置现在描述github/github Unicorn工作负载的Kubernetes资源充当了必不可少的试验场和原型构建环境。发布后,它为大批工程师提供了一种新的部署方式,帮助我们通过来自有兴趣的工程师的反馈以及未注意到任何变化的工程师继续使用,不断树立信心。就在最近,我们观察到高可用性团队的一些工程师在使用审核实验室,通过部署到共享实验室,试验Unicorn与新型试验子系统的行为之间的交互。我们对这个环境帮助工程师们以一种自助方式试验和解决问题极为满意。
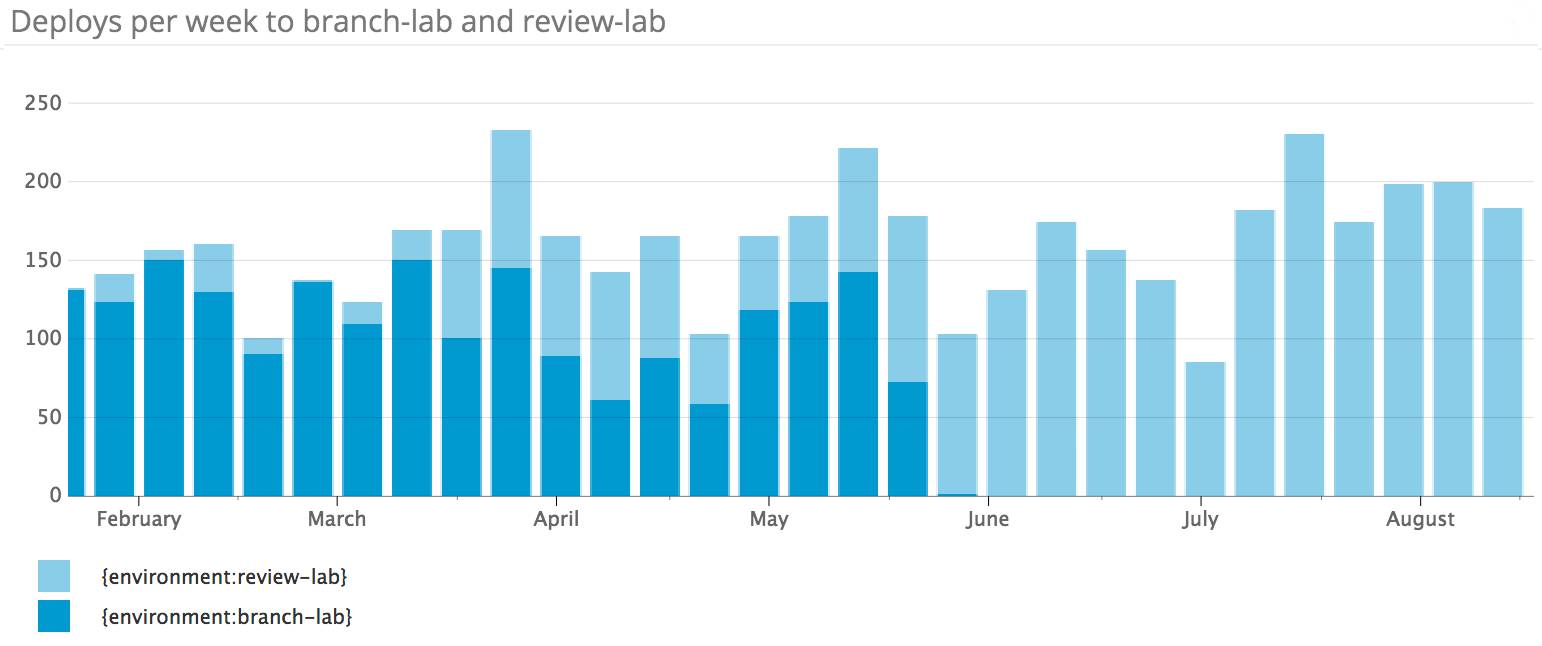
每周部署到分支实验室和审核实验室的情况
裸机上的Kubernetes
审核实验室交付后,我们的注意力转向了github.com。为了满足我们的旗舰服务在性能和可靠性方面的要求――这依赖于对其他数据服务的低延迟访问,我们需要扩建Kubernetes基础设施,该基础设施支持在我们的物理数据中心和接入点(POP)中运行的裸机云。同样,这项工作涉及近十来个子项目:
-
一篇介绍容器网络的适时而深入的文章(https://jvns.ca/blog/2016/12/22/container-networking/)帮助我们选择了Calico网络提供商,它提供了我们在ipip模式下迅速交付集群所需的开箱即用的功能,同时让我们在以后可以灵活地探讨与我们的网络基础设施实现对接。
-
关注了@kelseyhightower的十多篇文章,尤其是必读的Kubernetes the hard way(https://github.com/kelseyhightower/kubernetes-the-hard-way),我们将几台手动配置的服务器组装成一个临时的Kubernetes集群,它通过了我们用来测试AWS集群的同一套集成测试。
-
我们构建了一个小工具,为每个集群生成必要的CA和配置,采用了可以被我们的内部Puppet和secret系统使用的格式。
-
我们用Puppet来管理两个实例角色:Kubernetes节点和Kubernetes API服务器(apiserver)的配置,采用了让用户可以提供已经配置的集群的名称、配置时即可加入的方式。
-
我们构建了一个小小的Go服务,以便使用容器日志,附加采用键/值格式的元数据,并将它们发送到主机的本地syslog端点。
-
我们改进了GLB,这是我们的内部负载均衡服务,以支持Kubernetes NodePort服务。
经过所有这些辛苦的工作后,获得了一个通过我们内部验收的集群。有鉴于此,我们对此颇有信心:一组同样的输入(审核实验室所使用的Kubernetes资源)、一组同样的数据(审核实验室通过VPN相连接的网络服务)以及同样的工具,会带来类似的结果。在不到一周内――大部分时间花在了万一迁移带来重大影响的内部沟通和排序上,我们得以将这整个工作负载从AWS上运行的Kubernetes集群迁移到在我们的其中一个数据中心运行的Kubernetes集群。
提高信心指数
在我们的裸机云上组建Kubernetes集群有了一种成功的、可复制的模式后,接下来该为我们的Unicorn部署能够取代目前的前端服务器集群集群树立信心。
在GitHub,这种做法很常见:工程师及其团队通过创建一项新的Flipper功能,然后一旦证明切实可行,就选择使用该服务,以此验证新功能。我们先改进了部署系统,将一套新的Kubernetes资源部署到与现有生产级服务器并行的github-production命名空间,并且改进GLB,基于受Flipper影响的cookie,支持将员工请求路由至不同的后端。在此之后,我们允许员工使用我们的任务控制栏上的一个按钮,选择使用试验性的Kubernetes后端:
选择使用Kubernetes驱动的基础设施的员工UI
来自内部用户的负载帮助我们查找问题、修复错误,开始熟悉生产环境中的Kubernetes。在此期间,我们竭力通过模拟预计将来执行的程序,编写操作手册,并执行故障测试,以此增强信心。我们还将少量的生产级流量路由至该集群,证实我们在负载情形下性能和可靠性方面的设想,先从每秒100个请求开始,然后提高至github.com和api.github.com请求总数的10%。由于熟悉了这几种情形,我们暂停下来,重新评估全面迁移的风险。
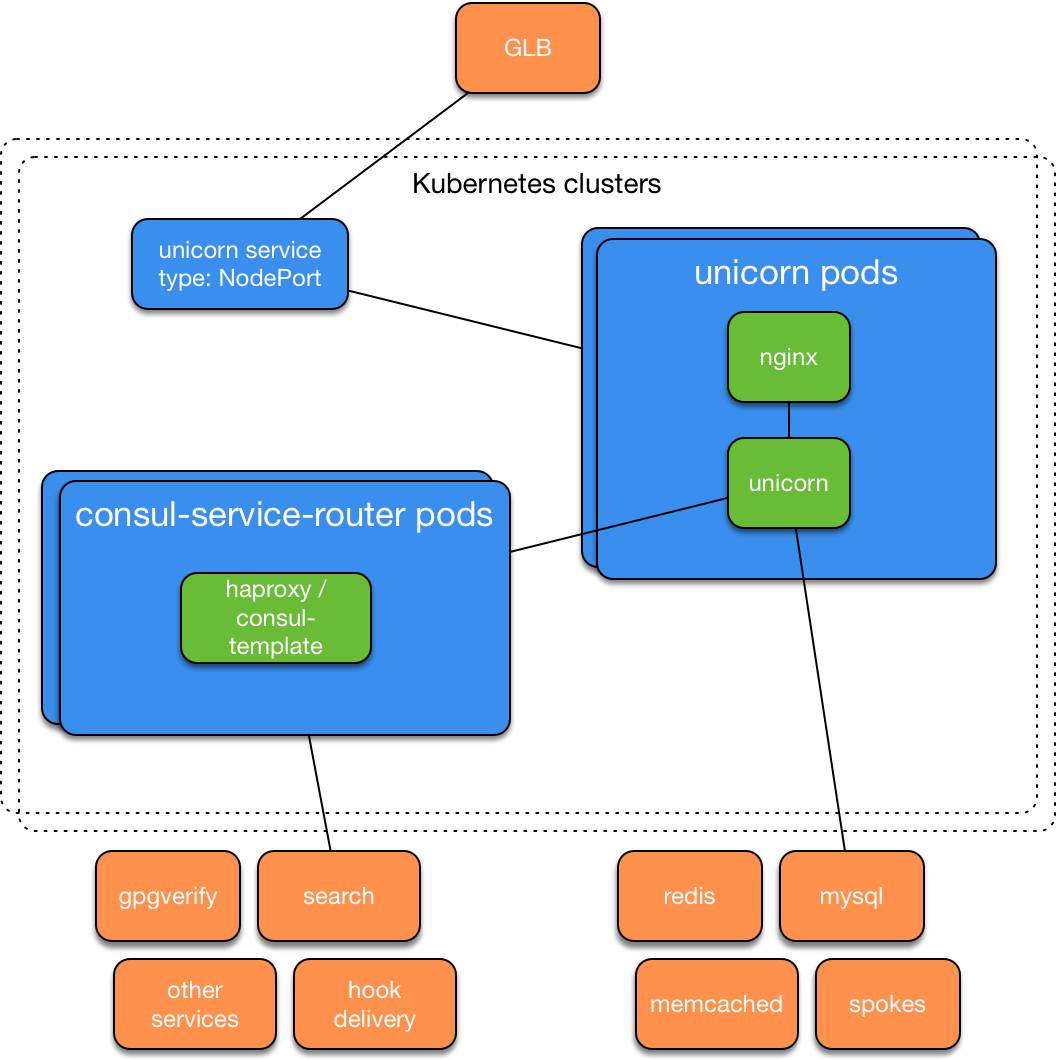
Kubernetes unicorn服务设计
集群组(Cluster Groups)
我们的几项故障测试出现了意料之外的结果。尤其是,模拟单一apiserver节点故障的一项测试扰乱了集群,给运行中工作负载的可用性带来了负面影响。调查这些测试的结果后没有得到明确的结论,不过帮助我们明白这次中断可能与连接至Kubernetes apiserver的诸客户端(比如calico-agent、kubelet、kube-proxy和kube-controller-manager)之间的交互以及内部负载均衡系统在apiserver节点故障过程中的行为有关。鉴于观察到Kubernetes集群性能降级、可能扰乱服务,我们开始考虑在每个站点的多个集群上运行我们的旗舰应用软件,并且使将请求从失效集群转移到其他正常集群的过程实现自动化。
我们已计划开展类似的工作,以支持将该应用软件部署到多个独立运行的站点,而这个方法的其他优点最终促使我们走这条道路,这些优点包括:集群升级干扰小,可以将集群与现有的故障域(比如共享网络和电源设备)关联起来。我们最终选择了这样一种设计:利用我们的部署系统支持部署到多个“分区”,对它作了改进,以便通过自定义的Kubernetes资源标注,支持针对特定集群的配置,摈弃了现有的联合解决方案,改用一种让我们得以使用部署系统中已有的业务逻辑的方法。
从10%提高到100%
集群组到位后,我们逐渐将前端服务器改成了Kubernetes节点,并提高了路由至Kubernetes的流量所占的比例。我们与其他许多负责任的工程小组一道在短短一个月多点的时间完成了前端迁移,同时确保性能和错误率在目标范围内。
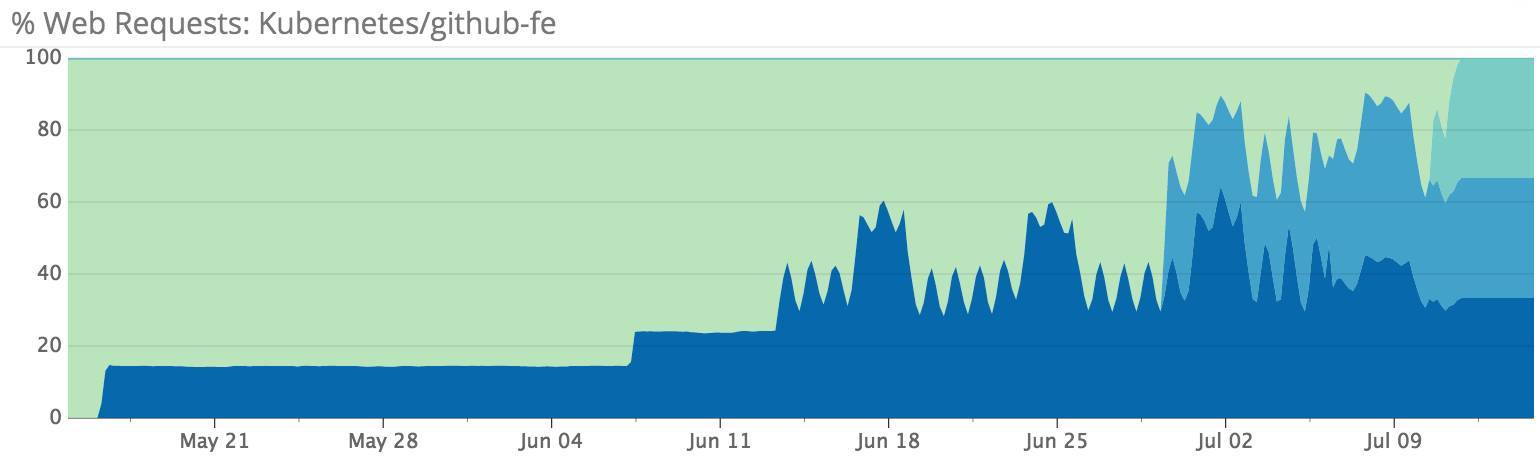
集群服务的Web流量所占的比例
在这个迁移过程中,我们遇到了今天仍存在的一个问题:在高负载及/或容器高流失率期间,一些Kubernetes节点会出现内核崩溃(kernel panic)和重启。虽然我们对此并不满意,继续调查原因(视之为一项重要工作),但让我们高兴的是,Kubernetes能够自动绕过这些故障,继续处理流量,错误率在预定的范围内。我们执行了几项故障测试,用echo c > /proc/sysrq-trigger模拟内核崩溃,发现这是我们的故障测试模式的一种有用补充。
接下来如何?
我们受到将该应用软件迁移到Kubernetes后的启发,期望很快迁移更多的系统。虽然我们首次迁移的范围有意局限于无状态工作负载,但是我们对于试验Kubernetes上运行有状态服务的模式的结果感到很兴奋。
在这个项目的最后阶段,我们还交付了一个工作流程,用于将新的应用软件和服务部署到一组类似的Kubernetes集群。在过去几个月,工程师们已经将众多应用软件部署到该集群。这些应用软件个个之前都需要SRE给予配置管理和资源配置方面的支持。自助式应用软件配置工作流程实施到位后,SRE可以将更多的时间用来向这家技术型公司的其余人员交付基础设施产品,以支持我们的最佳实践,为所有人努力打造一种更快速、更具弹性的GitHub体验。
云头条编译、未经授权谢绝转载
相关阅读:
中高端IT圈人群,欢迎加入!
赏金制:欢迎来爆料!长期有效!
AWS VS Kubernetes
微软加入 Kubernetes 开发者组织(CNCF)成为铂金会员
Kubernetes 正迅速成为云计算的 Linux
为什么说Kubernetes对亚马逊构成的威胁可能比谷歌云还要大?|「云头条」
2017年容器和云编排调查结果及分析
AWS 加入 Kubernetes开发者组织(CNCF)成为“铂金”会员
开源模式发生变化,Kubernetes的好日子可能快到头了
京东从 OpenStack 改用 Kubernetes 的始末






