听说最近转录因子小姐跟某基因先生走到了一起,并共同购置了爱巢,双宿双栖起来。娱媒圈(科研圈)沸腾了,经过EMSA、 DNase1足迹实验、甲基化干扰实验、体内足迹实验、Chip-on-chip等方式,终于落实了某转录因子跟某基因的关系,执着的娱记们哪肯松懈,继续探索转录因子跟该基因的启动子的爱巢(结合位点)在哪里?
第一步,要确定到他们的爱巢在哪条街?(怎么确定启动子?
一般查阅外文文献,老外把从转录起始位点开始上溯2K-3K的区间算做是启动子。
)
第二步就是要确定家门牌号?(启动子这么长,怎么知道具体的结合位点序列?
如何预测转录因子小姐跟某基因先生的爱巢(启动子结合位点)在哪里?这个活一般的娱记是干不了,还是得听小鱼我的。
干货来了,看这里了(敲黑板!)
以转录因子Nf-KB和Ankh基因为例,用UCSC在线网站锁定启动子范围,
在左栏选择Table browes。
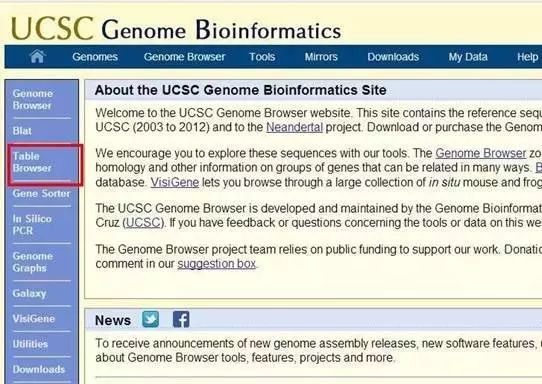
在clade选择Mammal,genome选择Human,assmebly选择最新的数据库,gene中输入ANKH,在track中选择RefSeq Genes,在output format中选择sequence,点击get output,根据需要选择序列,选择genomic-submit。
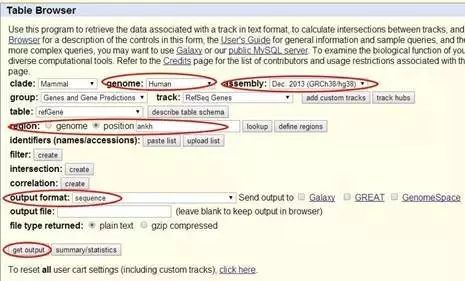
选择Promoter/Upstream by 2000 bases,选Exons in upper case, everything else in lower case(外显子大写,其他小写)。
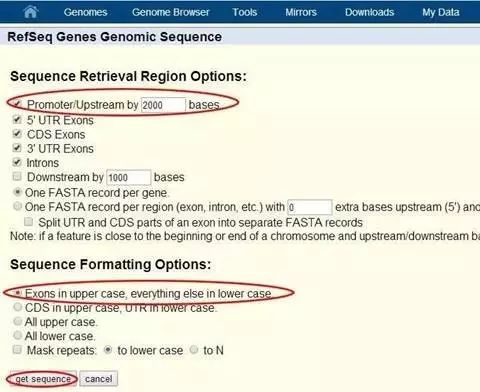
结果如下:大写字母是基因外显子区,大写字母前面的2000个小写字母就是预测的启动子区,复制粘贴保存到文本中。
当我们锁定了这一条街道以后,接下来就是敲定门牌号了,好紧张!
打开PROMO数据库,业界良心!首页就来送助攻:查找转录因子结合位点操作步骤。

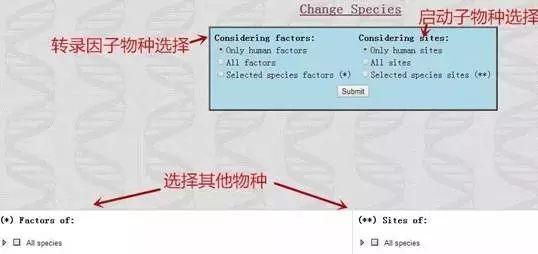
如助攻提到的,先点击黄色左栏SelectSpecies,选择物种, 点击Submit。
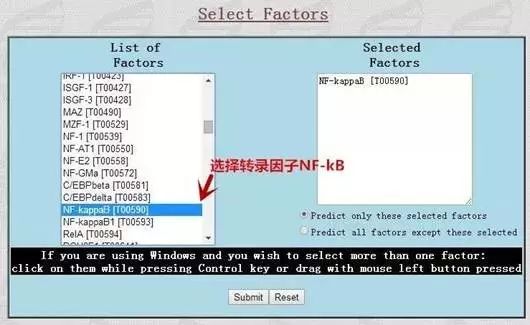
再点击黄色左栏SelectFactors,选择转录因子, 点击Submit。
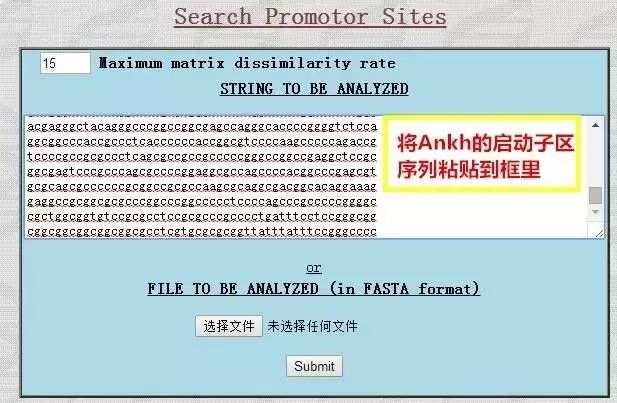
接着点击SearchSites,将之前锁定的启动子区序列粘贴到指定位置,点击Submit。
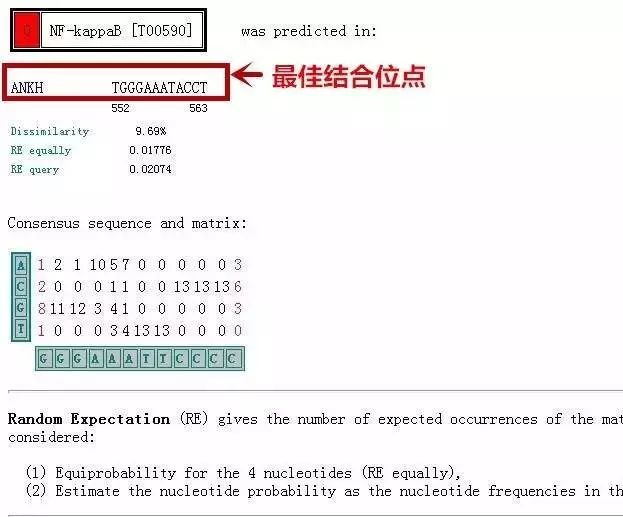
目标出现!
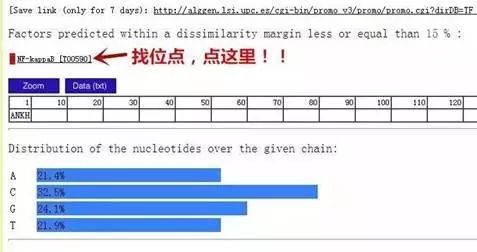
结果中的一个位点TGGGAAATACCT就是预测到的nf-kb结合在Ankh启动子的最佳位点。
同一个基因的启动子都是可长可短的,只是不同长度可能启动子的活性不一样。真核生物一般都是认为在第一外显子上游的2kb以内(也有2kb以外的)。转录因子不同的预测方法(除了PROMO,还可用Jaspar 、TFSEARCH、TRANSFAC等数据库)结果都不一样,最终只有实验验证的才准确。





